克雷西发自凹非寺
量子位公众号 QbitAI
FP8 和更低的浮点数量化精度,不再是 H100 的“专利”了!
老黄想让大家用 INT8/INT4,微软 DeepSpeed 团队在没有英伟达官方支持的条件下,硬生生在 A100 上跑起 FP6。
测试结果表明,新方法 TC-FPx 在 A100 上的 FP6 量化,速度接近甚至偶尔超过 INT4,而且拥有比后者更高的精度。
在此基础之上,还有端到端的大模型支持,目前已经开源并集成到了 DeepSpeed 等深度学习推理框架中。
这一成果对大模型的加速效果也是立竿见影——在这种框架下用单卡跑 Llama,吞吐量比双卡还要高 2.65 倍。
一名机器学习研究人员看了后表示,微软的这项研究简直可以用 crazy 来形容。
表情包也第一时间上线,be like:英伟达:只有 H100 支持 FP8。
微软:Fine,我自己搞定。

那么,这个框架到底能实现什么样的效果,背后又采用了什么样的技术呢?
用 FP6 跑 Llama,单卡比双卡还快
在 A100 上使用 FP6 精度,带来的是内核级的性能提升。
研究人员选取了不同大小的 Llama 模型和 OPT 模型之中的线性层,在 NVIDIA A100-40GB GPU 平台上,使用 CUDA 11.8 进行了测试。
结果相比于英伟达官方的 cuBLAS(W16A16)和 TensorRT-LLM(W8A16),TC-FPx(W6A16)速度提升的最大值分别是 2.6 倍和 1.9 倍。
相比于 4bit 的 BitsandBytes(W4A16)方法,TC-FPx 的最大速度提升则是达到了 8.9 倍。
(W和A分别代表权重量化位宽和激活量化位宽)
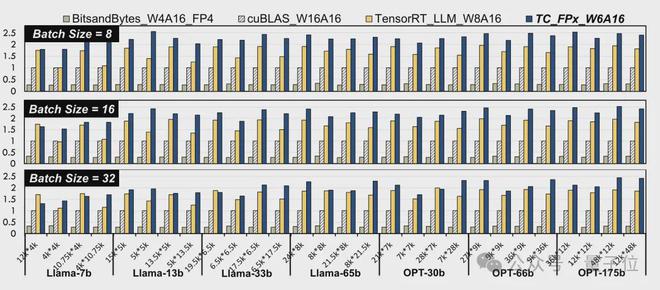
△归一化数据,以 cuBLAS 结果为1
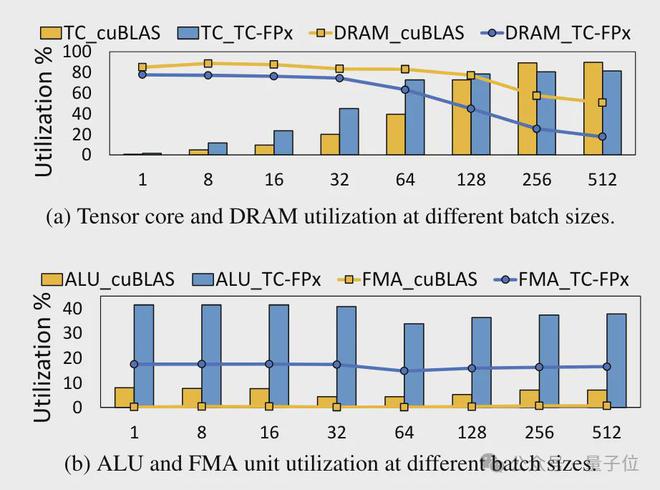
同时,TC-FPx 内核还减少了对 DRAM 内存的访问,并提高了 DRAM 带宽利用率和 Tensor Cores 利用率,以及 ALU 和 FMA 单元的利用率。
在 TC-FPx 基础之上设计的端到端推理框架 FP6-LLM,也给大模型带来了显著的性能提高。
以 Llama-70B 为例,用 FP6-LLM 在单卡上的运行吞吐量,比 FP16 在双卡上还要高出 2.65 倍,在 16 以下的批大小中的延迟也低于 FP16。
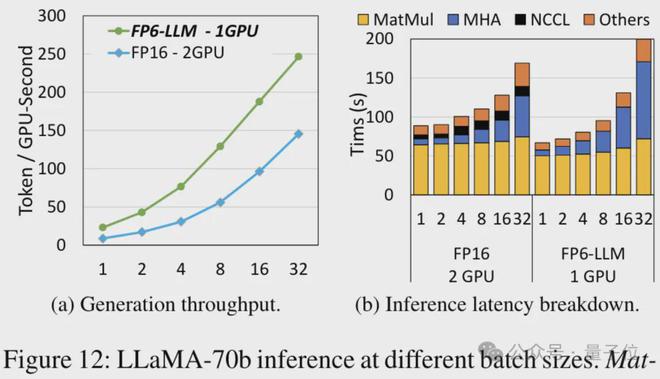
而对于参数量小一些的模型 OPT-30B(FP16 也使用单卡),FP6-LLM 同样带来了明显的吞吐量提升和延迟降低。
而且单卡 FP16 在这种条件下最多支持的批大小只有4,FP6-LLM 却可以在批大小为 16 的情况下正常运行。
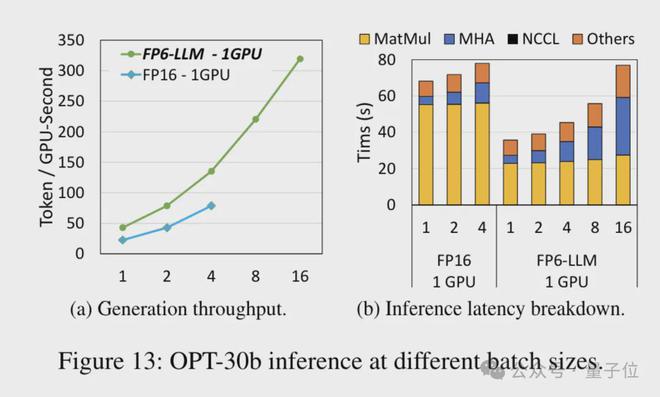
那么,微软团队是怎样实现在 A100 上运行 FP16 量化的呢?
重新设计内核方案
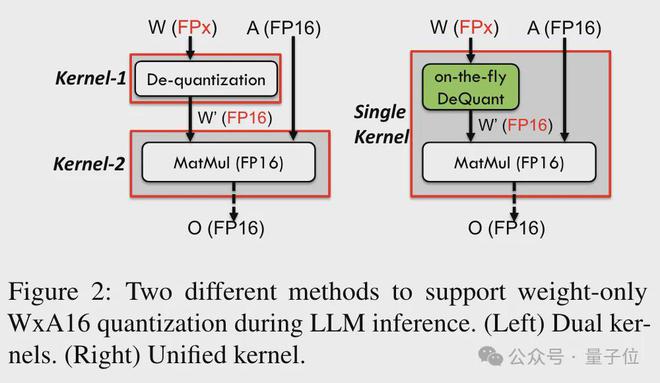
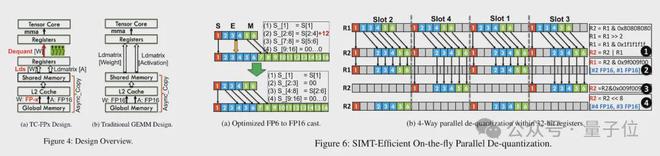
为了实现对包括 6bit 在内精度的支持,TC-FPx 团队设计了一个统一的内核方案,可以支持不同位宽的量化权重。
相比于传统的双内核方法,TC-FPx 通过将去量化和矩阵乘法融合在单个内核中,减少了内存访问次数,提高了性能。
实现低精度量化的核心奥义则是通过去量化方式,将 FP6 精度的数据“伪装”成 FP16,然后按照 FP16 的格式交给 GPU 进行运算。
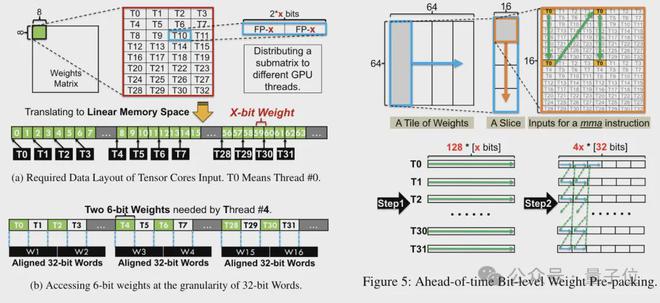
同时团队还利用了位级预打包技术,解决 GPU 内存系统对非 2 的幂次位宽(如6-bit)不友好的问题。
具体来说,位级预打包是在模型推理之前对权重数据进行重新组织,包括将6-bit 量化的权重重新排列,以便它们能够以 GPU 内存系统友好的方式进行访问。
此外,由于 GPU 内存系统通常以 32 位或 64 位的块进行数据访问,位级预打包技术将还会6-bit 权重打包,使得它们能够以这些对齐的块的形式存储和访问。
预打包完成后,研究团队使用 SIMT 核心的并行处理能力,对寄存器中的 FP6 权重执行并行去量化,生成 FP16 格式的权重。
去量化后的 FP16 权重在寄存器中被重构,然后送入 Tensor Core,使用重构后的 FP16 权重执行矩阵乘法运算,完成线性层的计算。
在此过程中,团队利用了 SMIT 核心的位级并行性,提高了整个去量化过程的效率。
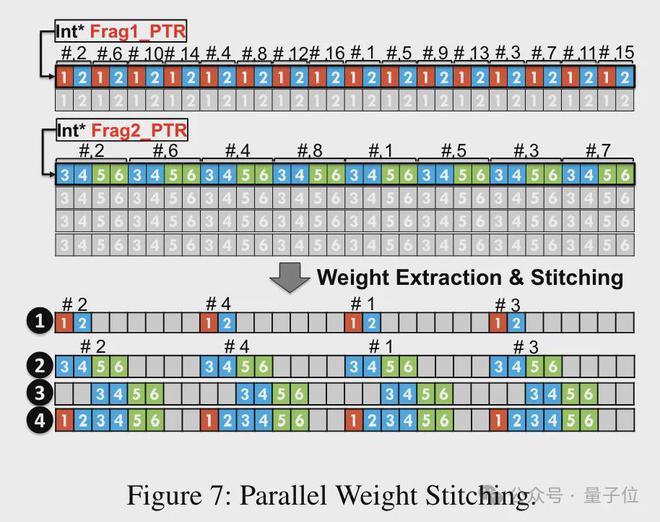
而为了权重重构任务能够并行运行,团队还使用了一种并行权重拼接技术。
具体来说,每个权重被分割成几个部分,每个部分的位宽是 2 的幂次(如把 6 分割成2+4 或4+2)。
在去量化之前,权重首先从共享内存加载到寄存器中。由于每个权重被分割成多个部分,需要在运行时在寄存器级别重构完整的权重。
为了减少运行时的开销,TC-FPx 提出了一种并行提取和拼接权重的方法。这种方法使用两组寄存器来存储 32 个 FP6 权重的片段,并行地重构这些权重。
同时,为了并行提取和拼接权重,需要确保初始数据布局满足特定的顺序要求,因此 TC-FPx 通过在运行前对权重片段进行重排。
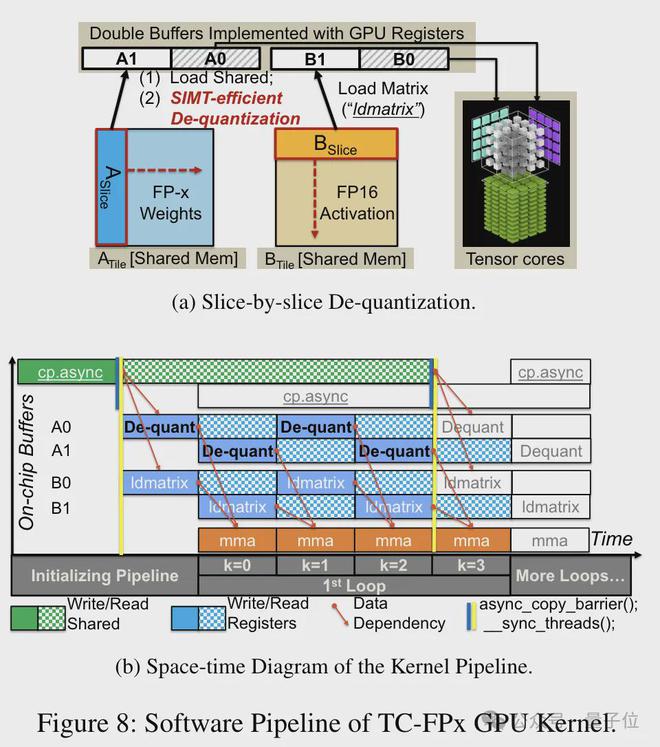
此外,TC-FPx 还设计了一个软件流水线,将去量化步骤与 Tensor Core 的矩阵乘法操作融合在一起,通过指令级并行性提高了整体的执行效率。
论文地址:
https://arxiv.org/abs/2401.14112
参考链接:











