
新智元报道
编辑:LRS
文中提出了一个半自动数据集创建管道 Gen4Gen,将个性化概念与文本描述结合成复杂的组合,创建了基准测试数据集 MyCanvas,利用 CP-CLIP 和 TI-CLIP 指标证明了该方法的有效性。
过去几年里,基于文本来生成图像的扩散模型得到了飞速发展,生成能力有了显著的提升,可以很容易地生成逼真的肖像画,以及各种天马行空的奇幻画作。
近期的相关研究主要集中在控制模型生成「个性化」的内容,即用户先提供一个最小概念图像集,然后对预训练的文本转图像扩散模型进行增强,从而使模型可以生成包含个性化概念的新场景。
现有的一些工作可以增强用户对生成过程的控制,并衍生出许多量身定制的应用场景;但要同时对多个概念进行个性化处理,并控制图像生成以准确遵循给定的文本描述,仍然具有挑战性。
最近,来自加州大学伯克利分校、牛津大学、哈佛大学、卡内基梅隆大学、香港大学、加州大学戴维斯分校的研究人员联合发表了一篇论文,讨论了「图像生成个性化」领域下的两个关键问题。

论文链接:https://arxiv.org/abs/2402.15504
项目主页:https://danielchyeh.github.io/Gen4Gen/
1. 当前的个性化技术无法可靠地扩展到多个概念,研究人员推测是由于预训练数据集(如 LAION)中复杂场景和简单文本描述之间的不匹配造成的。
2. 对于包含多个个性化概念的图像,缺乏一种全面的衡量标准,不仅评估个性化概念的相似程度,还评估图像中是否包含所有概念,以及图像是否准确反映了整体文本描述。
为了解决上述问题,研究人员提出了一种半自动数据集创建管道 Gen4Gen,利用生成模型将个性化概念与文本描述结合成复杂的组合;并且创建了一个可用于多概念个性化任务的基准测试数据集 MyCanvas。

此外,研究人员还设计了一个由两个分数(CP-CLIP 和 TI-CLIP)组成的综合指标,用于更好地量化多概念、个性化文本到图像扩散方法的性能。
我们在 Custom Diffusion 的基础上提供了一个简单的基线,其中包含经验性提示策略,供未来的研究人员在 MyCanvas 上进行评估。
实验结果表明,通过改进数据质量和提示策略,可以显著提高多概念个性化图像生成的质量,而无需对模型架构或训练算法进行任何修改。
结果也证明,chaining 基础模型可能是生成高质量数据集的一个有前途的方向,主要面向计算机视觉领域的各种挑战性任务。
Gen4Gen:面向多概念个性化的数据驱动方法
给定一组由用户提供的、多个概念的照片,多概念个性化的目标是学习每个概念的特征,以便能合成由多个概念组成的、背景和构图各不相同的新图像。
但随着要注入图像的个性化概念数量的增加,问题的难度也会大大增加。
之前的研究主要集中在优化训练策略上,而这篇论文证明了在整个训练过程中提高数据质量可以提高多概念个性化图像的生成质量。
1. 数据集设计原则
从 LAION 数据集中最具美感的子集(LAION-2B-en improved Aesthetics)中,可以清楚地看到图像的复杂程度与简单描述之间的不匹配。
由于该数据集主要通过网络检索,因此可能会出现差异:例如,图像可能存在不准确的大量文本描述,以及包含多个对象的图像分辨率较低。

研究人员从这些差异中汲取灵感,并提供了三个关键的设计原则:
1)详细的文字描述和图像配对:文本必须与相应的图像对齐,为前景和背景对象提供信息;
2)合理的物体布局和背景生成:为了避免图像看起来像人工剪切混合图像(Cut-Mixes),并充分利用 LAION 数据集已有的信息,必须确保只有在现实生活中有可能捕捉到物体时,这些物体才会同时出现在一张图像中,而且它们在图像中的位置也要合理;
3)高分辨率:确保数据集能够满足生成高质量、多概念个性化图像的最终目标。
2. Gen4Gen 管道
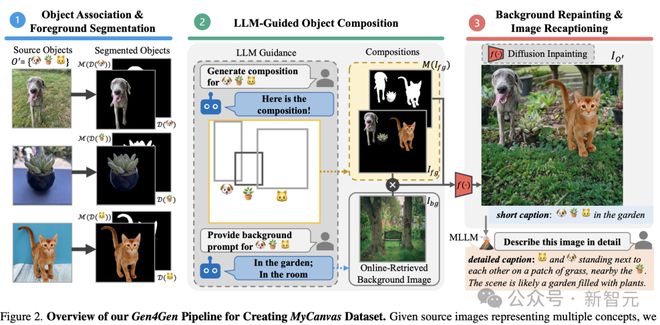
如上图所示,Gen4Gen 主要包括三个阶段:
1)对象关联(object association)和前景分割;
2)LLM 引导的对象组合;
3)背景重绘和图像重构。
3. 数据集统计
对于 MyCanvas 数据集,研究人员收集了 150 个对象(每个对象有一张或多张图片),并创建了 41 个可能的组合(composition)和 10,000 多张图片,然后手动筛选出 2684 张重绘结果质量最好的图片。

在该数据集中,图像描述的平均单词长度为 17.7 个,大约 30% 的描述长度超过了 20 个单词。

与之前的基准(如 DreamBooth 和 Custom Diffusion)相比,新数据集涵盖了更多种类的对象和多概念组合,因此是衡量个性化任务的更全面的数据集。

4. 提升训练时间的文本提示
除了设计与数据集中的图像完全一致的提示外,研究人员在训练过程中进一步探索最佳提示设计。
全局合成 token
之前的工作(如 DreamBooth)已经表明,模型可以学会将一个新 token 映射到非常困难的概念上,如莫奈艺术这样的抽象风格。
研究人员将这一概念应用于复杂的合成:通过引入全局 token 和每个物体的单独 token,该模型在描述详细场景安排方面的能力得到了增强,从而生成的图像更加逼真、更加连贯
在训练过程中重复概念 token 提示
可以注意到,在很多情况下,涉及多个概念的复杂组合往往会导致一个或两个概念缺失,可能是由于模型有时会忘记冗长提示中的细节;所以在训练过程中采用了重复概念 token 提示的策略,可以促使模型确保生成的图像中存在每个指定的概念,从而提高整体对象的持久性和完整性。
结合背景提示
研究人员观察到一个问题,即在 token 特征空间中,背景会无意中与 object identity 一起学习。
为了区分背景和概念的构成,必须确保在训练提示中说明背景,以鼓励 concept tokens 只学习 object identity
5. 个性化组合指标(composition metric)
为了克服这一问题,我们从文献[3, 18]中汲取灵感,提出了两个指标。第一个指标是合成个性化 CLIP 分数(CP-CLIP),用于评估合成和个性化的准确性。第二个指标是文本-图像对齐 CLIP 分数(TI-CLIP),通过评估模型在不同文本背景下的泛化质量,作为潜在过拟合的指标。
组合个性化 CLIP 评分(CP-CLIP)
用于评估组合和个性化的准确率。
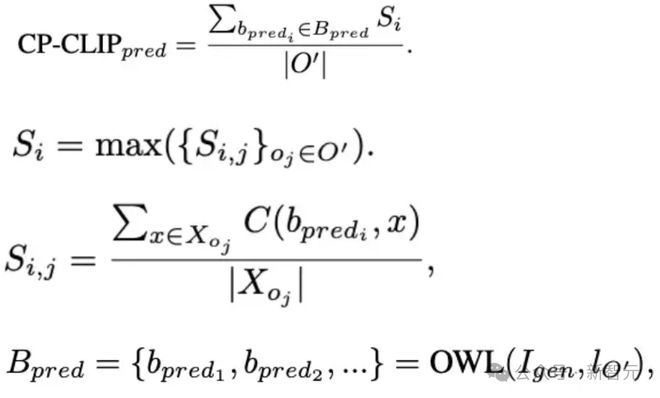
该指标主要解决两个问题:
1)文本中提到的每个个性化概念是否都在图像生成过程中得到了反映?(组合准确性)
2)生成的个性化概念是否与其源对应概念相似?(忠实度)
文本图像对齐 CLIP 评分(TI-CLIP)
通过评估模型在不同文本背景下的泛化质量,作为潜在过拟合的指标。
为了定量衡量过度拟合的程度,研究人员将 TI-CLIP 计算为「生成图像」与「提示词」之间的 CLIP 分数。
虽然 TI-CLIP 的表述与 CP-CLIP 非常相似(即可以将 TI-CLIP 视为个性化剪辑得分的一种特例,其边界框为整个图像,个性化目标为文本),但其评估的是模型泛化质量的一个正交概念,因此应作为一个单独的指标来衡量。
从高层次来看,TI-CLIP 衡量的是整个生成图像的背景提示(不包括对象),在提高 CP-CLIP 分数时,其目标应该是维持 TI-CLIP 的评分,也能表明模型并没有过度拟合训练集的背景。
评分解释
在实践中,研究人员发现 CP-CLIP 的理想分数约为 0.5,而 TI-CLIP 的分数应保持不变,不会增加。
实验结果
定量分析
研究人员使用了 41 个文本提示,每个提示有 6 个样本,共生成 246 幅图像。
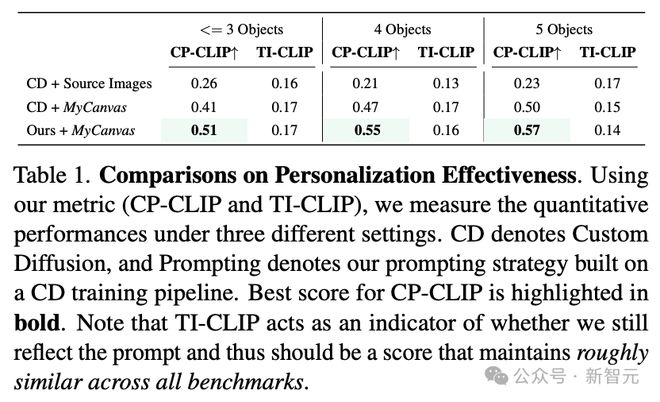
很明显,在使用原始源图像进行学习时,Custom Diffusion 的性能比使用 MyCanvas 数据集的同类产品降低了 50%。
将我们的提示策略应用于自定义扩散后,CP-CLIP 分数进一步提高。
值得注意的是,TI-CLIP 分数(表示背景泛化)在所有方法中都保持一致,可以确保组合准确率的提高不是因为过拟合。
定性分析
研究人员精心设计了多个 prompt 来测试模型在不同于训练场景的新场景中生成概念、将概念与其他已知对象(如独木舟上的猫、漂浮物上的狮子)组合在一起以及描述概念相对位置(如并排、背景中)的能力。
主要对比了三种设置下的定性结果:
1)使用原始源图像进行自定义扩散;
2)使用 MyCanvas(由源图像组成的数据集)进行自定义扩散;
3)提示策略建立在使用 MyCanvas 进行自定义扩散的基础之上。

可以看到,即使背景描述极具挑战性,组合策略也能成功分离出潜在空间中相似的物体(如狮子和猫、两辆拖拉机)。
此外,随着组合的难度增加(即每一行的下降会增加组合中对象的数量),提示方法可确保在生成过程中不会遗漏任何概念。
值得注意的是,结果证明了通过使用 MyCanvas 数据集,现有个性化模型(如自定义扩散模型)的生成质量可以显著提高。
参考资料:











