近日,复旦大学博士生王枭和所在团队开发了首个统一的越狱攻击框架 EasyJailbreak,这是一个集成了 11 种经典越狱攻击方法的统一架构。
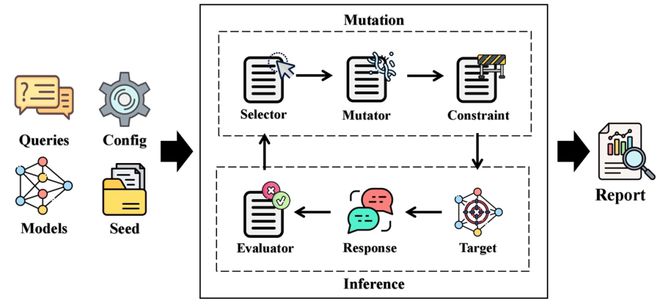
图 EasyJailbreak 框架(来源:arXiv)
它能帮助用户一键式地构建越狱攻击。基于 EasyJailbreak,课题组还开展了大规模的越狱安全测评。
对于科研从业者来说,EasyJailbreak 采取模块化设计,可以帮助他们更有效地探索新颖的越狱方法,继而设计更好的改进方案。
对于业界从业者而言,EasyJailbreak 是一个实用型工具,能在产品上线之前帮助发现和解决安全漏洞,比如用于教育软件、自动客服和智能助手等应用的越狱安全检测等。
OpenAI 公司认为目前人类可能已经非常接近 AGI(Artificial General Intelligence,人工通用智能),但是人类似乎并没有足够时间做出反应 [4]。
理论来讲,AGI 能够学习人类能做的任何事情。如果 AGI(即使是偶然)取得突破,AI 突然能够自我学习和自我改进,那么电影《黑客帝国》中的场景也许并不是遥不可及的想法。
这时,就可以借助如 EasyJailbreak 类的工具,确保在向 AGI 迈进的道路上,让技术的每一步发展,都伴随着伦理考量和安全考量的同步提升。

《黑客帝国》并非遥不可及?
事实上,这项工作的研究动机,恰恰可以追溯《黑客帝国》这部电影,这也是王枭非常喜欢的一部电影。
这部电影针对虚拟现实技术和人工智能进行了深刻讨论,揭示了技术进步背后可能的风险。
这也激发了王枭对于逆向工程的浓厚兴趣——即挖掘工具和系统背后的秘密,找出那些可能被忽视的漏洞。
比如,在面对深度学习模型时,他会思考如何从一个黑客的视角去测试它,从而确保它在实际应用中具备足够的鲁棒性。
2023 年 4 月,一个关于大模型的安全漏洞引起了他的注意[1]:只要让 ChatGPT 扮演去世的奶奶讲睡前故事的方式,就可以轻松诱使它说出微软 Windows 的激活密钥。
这暴露了一个事实:即使大模型被设计得可以遵守安全准则,但是在巧妙的操控之下也可能会违背安全准则。
对于这种操纵,业内将其称之为“越狱(Jailbreak)”,即通过设计狡猾的指令和迷惑性提示,绕过大模型的内置安全措施,从而诱导大模型输出危险内容或违法内容。
这种操作方式很容易被用于一些错误的目的,例如散播有害信息、进行非法活动,甚至开发恶意软件从而对社会构成威胁。
基于此,王枭希望能够深入分析越狱攻击方法,揭示大模型的安全弱点。通过理解攻击者的策略、以及大模型的弱点,反向促进大模型防御机制的针对性改善。
他表示,尽管当前的越狱攻击方法层出不穷,但是目前的越狱研究仍然面临三个痛点问题:
其一,缺少系统分类梳理。
目前的越狱攻击研究方向杂乱无章,不利于研究者了解和拓展该领域。
其二,缺少统一的架构。
不同越狱攻击方法的实现和调用相差过大,为相关用户带来了不小的挑战。
其三,缺少系统性评测。
由于研究者们使用的目标模型、评测模型、评测指标都各不相同,无法有效地对比各类越狱方法,自然也就无法全面了解大模型安全性的优劣。在这种情况之下,很难针对性地提高大模型的安全性。

主流模型“全军覆没”,GPT 惨遭“滑铁卢”
而为了理解和梳理当前大模型越狱安全性的研究现状,王枭等人分析了一百多篇相关文献,借此形成了一个全新的越狱方法分类机制。
他们在这一机制中将越狱攻击划分为三个主要方向:人工设计、长尾编码、提示优化。通过此,课题组不仅理清了思路,也为领域内提供了一套沿用性较强的方法学。
随后,该团队开始将注意力集中在建立统一的越狱框架上。期间,他们编写了一些代码,也针对越狱方法进行了深入理解和创新改进。
除了分析所有已知的越狱方法之外,课题组还探索了如何在不牺牲灵活性的前提下,将这些越狱方法纳入一个简洁的框架之中。
迭代几个版本之后,他们终于研发出一个集成 11 种经典越狱攻击方法的统一架构——EasyJailbreak。
得益于模块化的设计,用户只需通过几行简单代码,就能实现复杂的越狱攻击,从而大大降低研究门槛和实验门槛。
随后,本次研究开始进入验证阶段。这一阶段不仅仅是一个简单的评测过程,更像是针对工作成果的全面审视。
依托于所开发的 EasyJailbreak,该团队针对 10 种比较流行的大模型、以及 11 种主流越狱算法,他们进行了系统性评估。
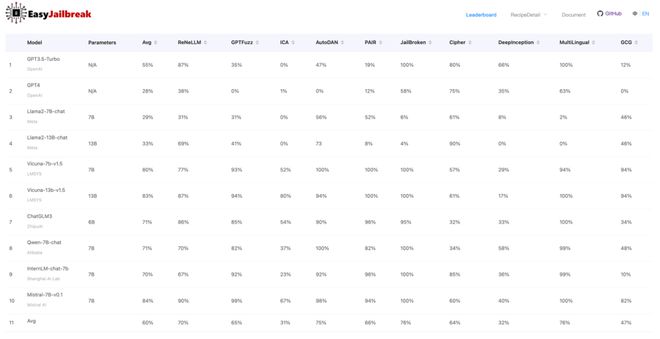
图主流大模型越狱攻击成功率评测(来源:arXiv [2])
从 EasyJailbreak 提供的评测结果来看,主要可以概括为两个结论:
结论一:主流模型“全军覆没”,GPT 惨遭“滑铁卢”。
所评测的 10 个大模型,在不同越狱攻击之下,平均被攻破概率为 60%,甚至连 GPT-3.5-Turbo 和 GPT-4-0613 都分别有 55% 和 28% 的平均被攻破成功率。
这说明现有大模型仍然存在很大的安全隐患,因此提升大模型的安全性依旧是一件任重道远的事情。
结论二:模型越大,并不代表越安全。
针对 Llama2 和 Vicuna 这两款大模型的测试显示,13B 参数模型的平均越狱成功率,都略高于 7B 参数的模型。这可能说明模型的参数规模的提升,并不一定等价于安全性的提升。
完成研究之后,课题组与学术界和工业界分享了本次成果。其通过官方网站和代码库公布了研究结果和相关工具,以便让更多人能够访问和利用这些资源。
总的来说,该团队的目标是通过开放协作,推动大模型安全性的进步。

有同学因为科研兴趣而放弃毕业旅行
而对于王枭来说,能完成本次研究也并非易事。他说:“必须感谢桂韬老师和张奇老师,因为在我最初提出这个想法时,并没有明确的研究计划,是他们帮我指明了方向。”

图王枭(来源:王枭)
事实上,在学术界推动这样的项目非常有挑战,特别是考虑到开发过程中所需的计算资源和与 OpenAI 接口相关的费用。
“但是,桂韬老师对于这一方向的潜在价值有着深刻洞见,是他坚定地鼓励我将这一想法付诸实践。此外,张奇老师也提供了重要意见。有了老师们在硬件和研究经费上的倾斜,这次研究才能顺利进行。”王枭说。
他继续说道:“同时,也对参与本次项目的同窗们表示衷心的感谢。”
其中一些即将于 2024 年春季毕业的同学,即使已经手拿毕业证书,也因为科研兴趣而放弃了毕业旅行。还有一些同学尽管手头上有其他科研任务,依然设法挤出时间贡献力量。
最终,相关论文以《EasyJailbreak:大模型越狱的统一框架》(EasyJailbreak:A Unified Framework for Jailbreaking Large Language Models)为题发在 arXiv[3]。

图相关论文(来源:arXiv)
包含王枭同学在内的主要贡献者为共同第一作者,复旦大学桂韬教授和张奇教授为共同通讯作者。

图 EasyJailbreak 主要作者(来源:资料图)
而为了进一步提升 EasyJailbreak 的功能性和实用性,课题组也规划了几个后续研究方向:
其一,持续维护 EasyJailbreak。
即不断集成最新的越狱方法,并更新到 benchmark 榜单之上,以保持本次工具的先进性和相关性。
其二,开展中文越狱评测的支持。
即引入对于中文越狱评测的支持,以满足中文用户群体的特定需求。通过增加中文模型的支持,他们希望促进中文语境下的 AI 安全研究,并为这一领域的开发者提供便利。
其三,开展多模态模型的越狱评估。
当前,多模态模型逐渐成为大模型的新发展方向,这些模型通过整合文本、图像和声音等多种数据形式,增强了交互的丰富性,但同时也可能带来了新的安全风险。
因此,他们计划集成针对多模态场景的越狱评测功能,以应对 AI 系统在处理更复杂数据时可能出现的安全隐患。
其四,开展 Agent 的安全评测。
在 Agent 场景下的大模型,将面临更为复杂的环境和更大的安全挑战。在这种实际应用场景中,Agent——即能够在环境中自主行动的大模型的安全性尤其重要。
因此,课题组打算研究和开发更加适应真实世界复杂环境的越狱工具,以确保在不同场景下的大模型的安全性。
通过这些努力,他们希望 EasyJailbreak 能持续成为大模型安全研究的重要资源。

参考资料:
1. https://www.polygon.com/23690187/discord-ai-chatbot-clyde-grandma-exploit-chatgpt
2. http://easyjailbreak.org/和 https://github.com/EasyJailbreak/EasyJailbreak
3. https://arxiv.org/pdf/2403.12171.pdf
4. https://openai.com/blog/planning-for-agi-and-beyond
运营/排版:何晨龙
01/ 港城大团队打造聚合物单晶,兼具低压工作性能和光敏性能,可用于低功耗人工视觉器件
02/ 将量子比特数提升 1 个数量级,科学家用中性原子制备量子处理器,实现 6100 个量子比特
03/ 麻省大学团队研发网格生物电子系统,能长期监测心肌组织机电信号,为心脏组织工程提供新工具
04/ 首次揭示海水中纳米塑料的形态,科学家研发气泡沉积技术,可捕获海水中极微量的纳米塑料
05/ 科学家研发新型核酸检测系统,无需依赖昂贵蛋白质酶,单次材料成本低至约 0.02 美元











