
新智元报道
编辑:flynne
苹果开发的多模态模型 Ferret-UI 增强了对屏幕的理解和交互,在引用、基础和推理方面表现出了卓越的性能,这些增强功能的出现预示着巨大的进步。
一句话 Siri 就能帮忙打开美团外卖下订单的日子看来不远啦!
4 月 8 日,苹果发布了其最新的多模态大语言模型(MLLM )——Ferret-UI,能够更有效地理解和与屏幕信息进行交互,在所有基本 UI 任务上都超过了 GPT-4V!

论文地址:https://arxiv.org/pdf/2404.05719.pdf
虽然苹果前段时间经历了泰坦项目的沉没,但看目前的形式,这是又要开卷的节奏呀~

不少人十分期待,这项技术如果在苹果的 Siri 上,Siri 岂不是要变得聪明绝顶了!

众所周知,通用域多模态大型语言模型(MLLM )在理解和有效交互的能力方面往往不足。
而 Ferret-UI 被称之为是一种新的 MLLM,专为理解移动 UI 屏幕而量身定制,具备指向、定位和推理等多种能力。
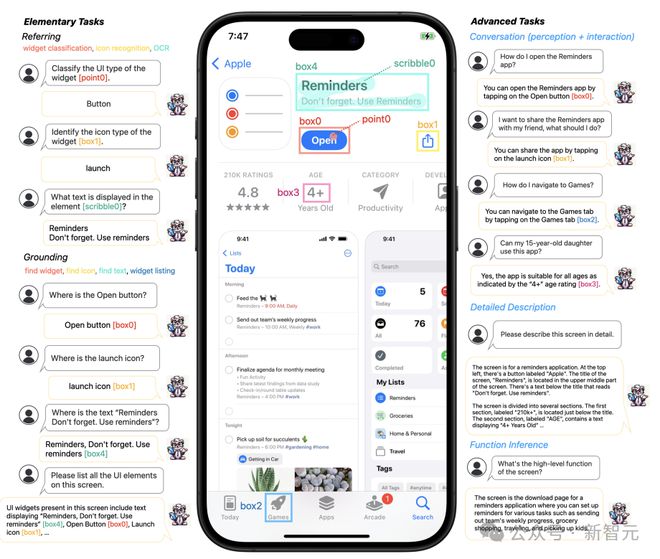
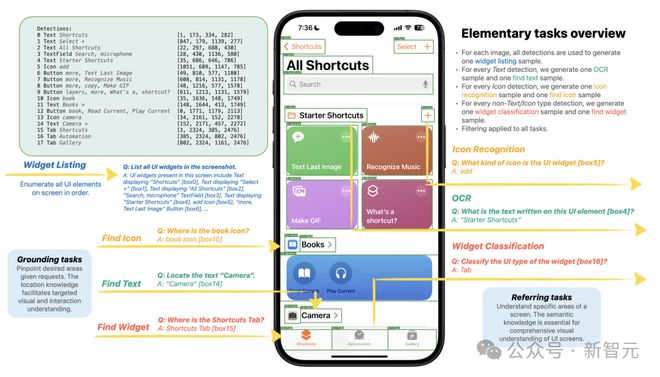
Ferret-UI 能够通过灵活的输入格式(点、框、涂鸦)和基础任务(例如:查找小部件、查找图标、查找文本、小部件列表)在移动用户界面屏幕上执行引用任务(例如:小部件分类、图标识别、OCR) )。
Ferret-UI 的一个关键特点是「任何分辨率」(anyres),该技术通过放大细节来解决 UI 屏幕中小型对象的识别问题,从而提高模型对 UI 元素的理解精度。
这些基本任务为模型提供了丰富的视觉和空间知识,使其能够在粗略和精细级别上区分 UI 类型, 例如区分各种图标或文本元素。
具体来说,Ferret-UI 不仅能够在详细描述和感知对话中讨论视觉元素, 还能在交互对话中提出目标导向的动作并通过函数推理来推断屏幕的整体功能。
网友直呼:泰裤辣!

虽然 Ferret-UI-base 紧密遵循 Ferret 的架构,但 Ferret-UI-anyres 融入了额外的细粒度图像功能。
特别是,预先训练的图像编码器和投影层可以为整个屏幕生成图像特征,对于基于原始图像长宽比获得的每个子图像,生成附加图像特征。
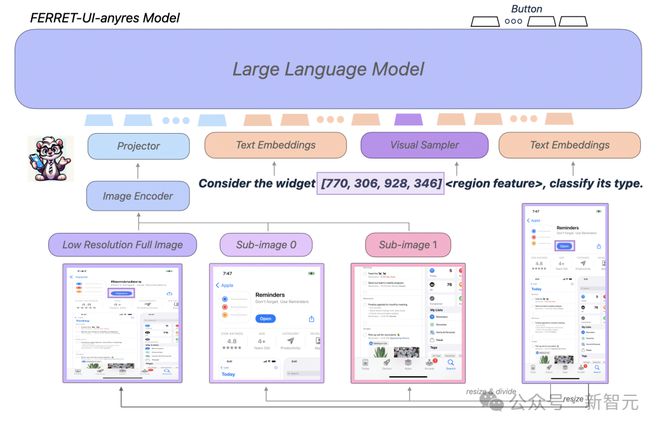
为了增强模型的推理能力, 研究人员编译了用于高级任务的数据集,包括详细描述、 感知/交互对话和函数推理。
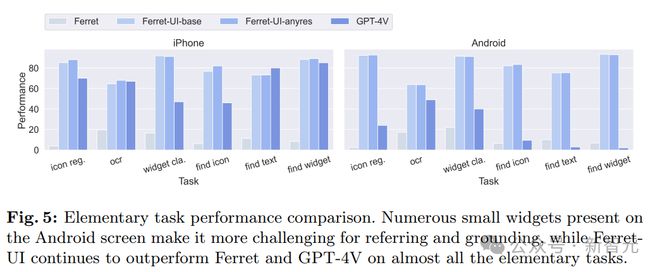
在基础任务性能的比较上, Ferret-UI 展现出了对 UI 屏幕的出色理解能力以及执行开放式指令的能力,表现可谓亮眼!
掌握应用程序屏幕并使 AI 像人类一样进行交互,苹果未来或许将改变 MLLM 的游戏规则!
论文细节
方法
Ferret-UI 建立在 Ferret 的基础上。
Ferret 是一种 MLLM,擅长在形状和细节各异的自然图像中进行空间参照和定位。

它可以解释区域或对象并与之交互,无论这些区域或对象被指定为任何自由形状(点、方框等)。
它包含一个预先训练好的视觉编码器和一个纯解码器语言模型,并采用一种独特的混合表示技术,将指定区域转换为适合 LLM 处理的格式。
为了向 Ferret 灌输 UI 专业知识,他们对 Ferret-UI 进行了两个扩展:
1. UI 参照和定位的定义与构建
2. 模型架构调整以更好地处理屏幕数据
与之前需要外部检测模块或屏幕视图文件的 MLLM 不同, Ferret-UI 是自给自足的。
它将原始屏幕像素作为模型输入,这种方法不仅促进了高级单屏交互,还为新应用程序铺平道路,例如:提高可访问性。
数据集
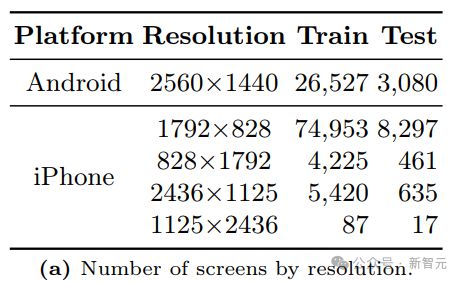
他们对 iPhone 和安卓设备的屏幕进行了研究。
对于安卓屏幕,研究人员使用 RICO 数据集的一个子集,具体来说,他们考虑了 Spotlight 中的任务,其数据是公开的,包括 screen2words、widgetcaptions 和 taperception。
对于 iPhone 屏幕,研究人员使用 AMP 数据集,它涵盖了广泛的应用程序。
在收集 Android 和 iPhone 屏幕后,他们使用预先训练好的基于像素的 UI 检测模型进一步从屏幕收集细粒度元素注释。
对于每个检测到的用户界面元素,输出结果都包括用户界面类型(按钮、文本、图标、图片等)、相应的边界框,以及由 Apple Vision Framework 识别的显示在其上的文本(如果有的话)。
任务制定
首先从现有的 Spotlight 任务中获取 screen2words、widgetcaptions 和 taperception,并将它们格式化为会话 QA 对。
对于每个训练示例,他们都会对相应任务的提示进行采样,并将其与原始源图像和真实答案配对。
基础任务数据生成
除了 Spotlight 任务之外,他们将 referring 任务定义为输入中带有边界框的任务,而基础任务则是输出中带有边界框的任务。
对于每个任务,他们还使用 GPT-3.5 Turbo 来扩展基本提示以引入任务问题的变体。
数据生成的详细信息如下图所示。
高级任务数据生成
为了将推理能力融入到该模型中,他们使用 LLaVA 方法,并用 GPT-4 收集另外 4 种格式的数据。
首先对检测输出中的边界框坐标进行标准化,然后将检测、提示和可选的一次性示例发送到 GPT-4。
为了详细描述和功能推理,他们将生成的响应与预选的提示配对来训练 Ferret-UI。
下图说明了高级任务的训练数据生成过程。
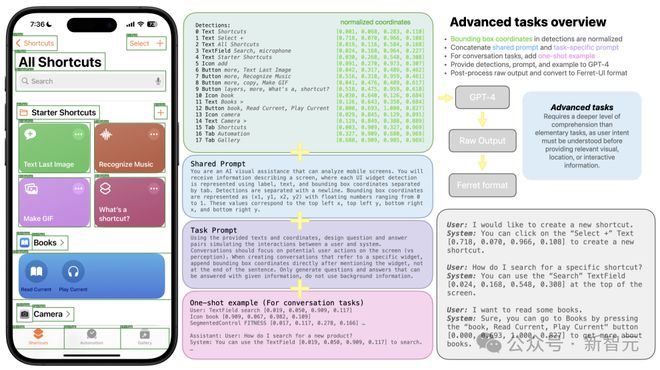
以上数据的生成主要为 4 个任务,分别是:详细描述、对话感知、对话交互和功能推理。
其中,他们扩展了详细描述和函数推理的基本提示,将它们与 GPT-4 响应配对,作为模型训练中的输入数据。
对于对话任务,他们为 GPT-4 提供了一个上下文示例,以更好地遵循其输出中的边界框格式。
实验结果
初级任务的性能细分如下表所示。
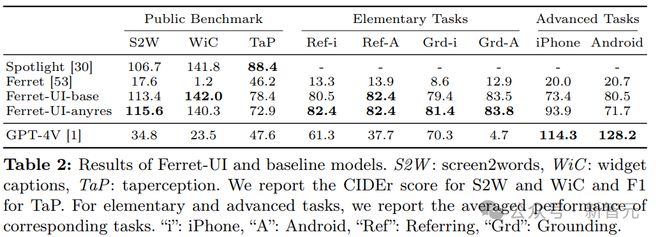
可以看到,与 Spotlight 相比,Ferret-UI 在 S2W 和 WiC 方面表现出了优越的性能,尽管 Spotlight 使用了 80M 网页截图和 269M 手机截图进行预训练。Ferret-UI 性能虽然低于 TaP,但仍然具有竞争力。
高级任务性能的结果如下表所示。
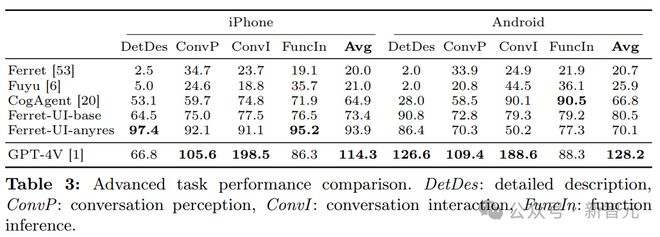
尽管 Ferret-UI 的训练数据集中缺少 Android 特定数据,但它在两个平台的高级任务上都表现出了值得称赞的性能。
这表明用户界面知识在不同操作系统之间具有显著的可转移性。
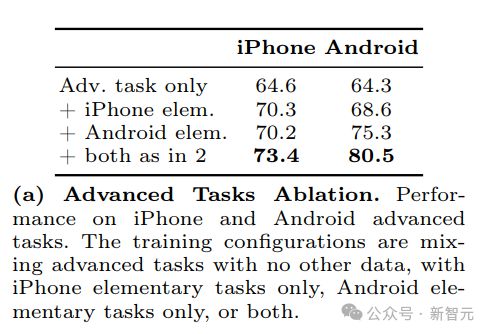
消融研究
研究发现,当仅使用高级任务数据,两个平台的性能均为 64%。添加 iPhone 或 Android 基本任务后,iPhone 上高级任务的性能持续提高5%。
同样,从 iPhone 添加基本任务可将 Android 在高级任务上的性能提高约4%,而合并 Android 基本任务可将这一性能提高9%。
包含 iPhone 和 Android 基本任务后,iPhone 和 Android 高级任务的性能分别进一步提高了3% 和5%,超出了单组基本任务所带来的改进。
这些观察结果支持他们的假设,即:基本任务为模型提供了增强的视觉和空间理解,从而促进了高级任务。
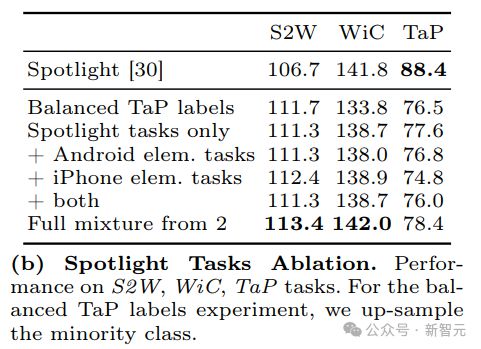
为了探索不同数据配置对 Spotlight Tasks 性能的影响,他们特别研究了添加初级任务数据是否能提高模型性能,因为这些任务的目的是为了提高对屏幕的视觉和空间理解能力。
如下表所示,添加基本任务数据(无论是仅来自 Android、iPhone 还是两者的组合)都不会显著改变三个 Spotlight 任务的性能。
在分析 Ferret-UI 的参照功能时,他们特别关注 OCR 和小部件分类预测,如下图所示。
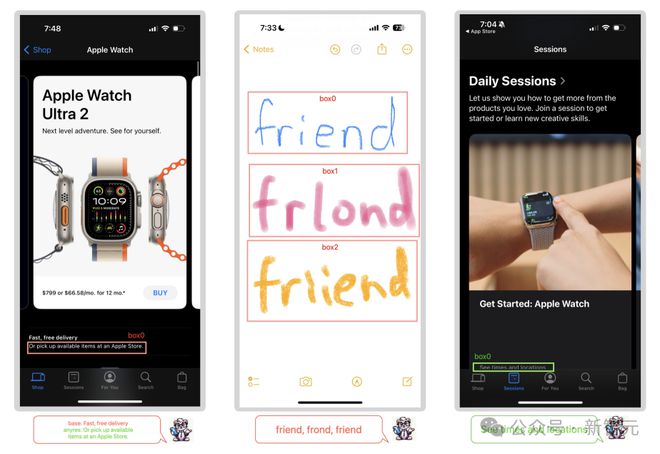
OCR 分析揭示了三个值得注意的观察结果:
1. 模型预测相邻文本而不是目标区域中的文本
2. 该模型表现出预测实际单词的倾向,而不仅仅是破译屏幕上显示的字符。
3. Ferret-UI 展示了准确预测部分被截断的文本的能力,即使在 OCR 模型返回不正确文本的情况下也是如此。
参考资料:











