
文雷科技 leitech
小雷平时刷B站经常会看到有 UP 主发布 AI 模仿明星唱歌的视频,音色音准至少有6-7 成的相似度,甚至部分训练到位的 AI 模型能复刻出与明星几乎一致的声音。除了唱歌外,这种功能还被广泛应用于不同角色的配音,一个被投喂了足够数量和时长的高质素材的 AI 大模型,绝对能达到以假乱真的程度。
五音不全的小雷十分向往这项技术,但苦于本地训练模型的繁杂,一直没有下定决心去训练自己的 AI 声音。恰巧近期百度文心一言上线了定制智能体专属声音的新功能,官方宣称用户只要花费几秒就能完成设定。
如此省时省力就能训练出自己的 AI 声音?带着疑惑,小雷尝试着创建专属自己的「AI 嘴替」。
创建“AI 嘴替”很高效,但功能太有限
打开文心一言 App,点击下方「+」号,我们就进入到智能体的创建界面。在声音选项栏中,我们能给智能体选择声音特性。在官方声音根据方言、性别、音色以及角色进行分类,提供了 32 种不同的声音。但我们目标明确,还是来体验下创建自己的声音这一功能。
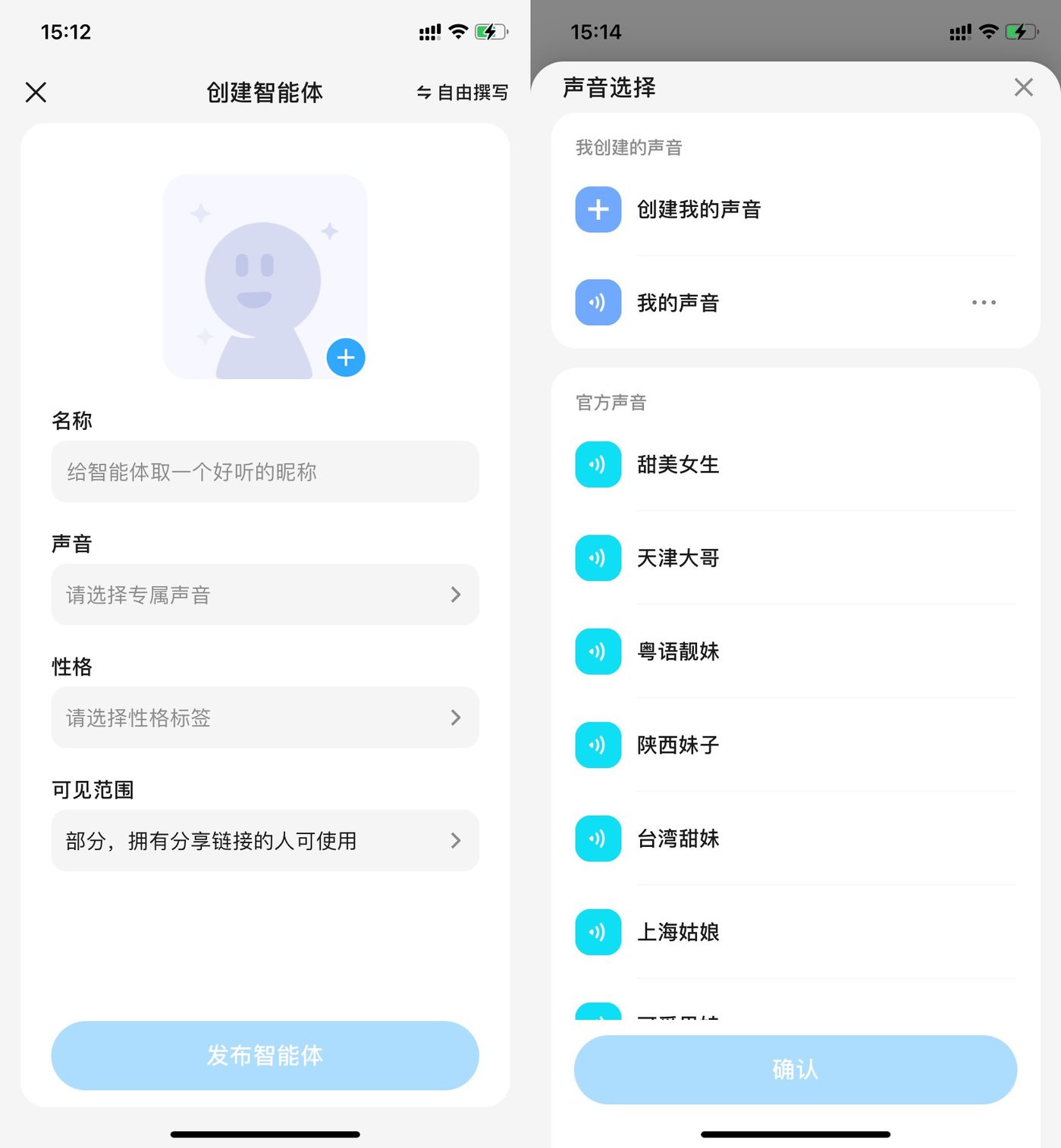
图源:雷科技制作,文心一言页面
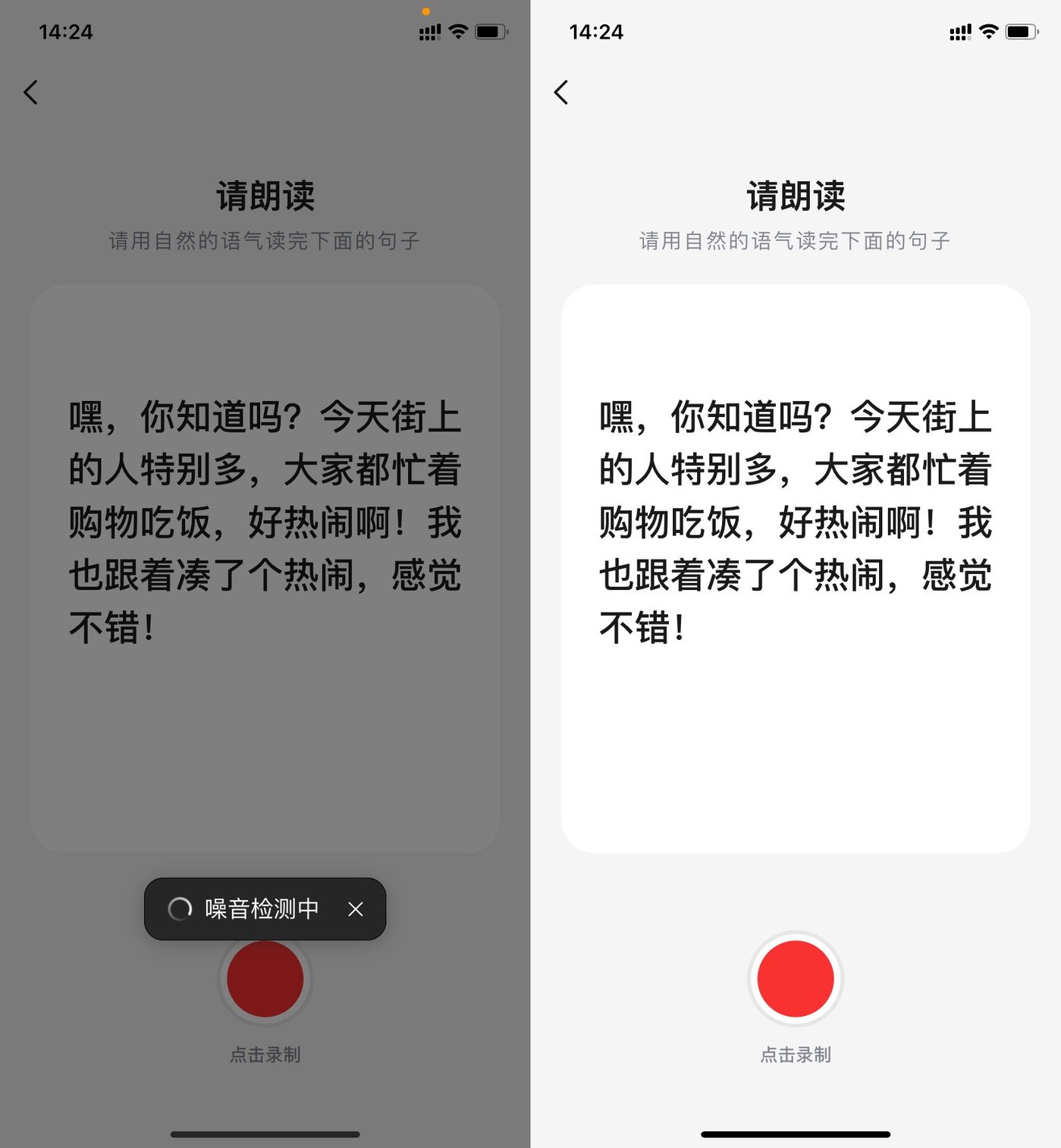
点击「创建我的声音」,用户需要用自然的语气朗读系统给出的文字,让系统识别音色音准。经实测,识别过程仅需2-3 秒,小雷的「AI 嘴替」就正式创建成功。值得注意的是,系统在录制前会对环境音进行短暂的识别,确认噪声符合录制要求后,才正式进入录制环节。
不仅如此,我们还能对智能体的性格特征、口头禅、个人经历、亲友关系、兴趣爱好以及开场白,进行个性化定制,这些因素会影响智能体后续的交流表现。
图源:雷科技制作,文心一言页面
话不多说,我们来看看文心一言在短时间内创建的 AI 声音究竟能不能让人满意。开启声音播报功能后,小雷试着让智能体给我介绍雷科技的相关信息,先不说声音,至少对雷科技的介绍还是比较全面的,除了公众号 168 万粉丝(已超过 170 万)的数据有些过时外,其他描述大体一致。
说回声音,音色方面本人认为至少能达到 8 成的相似度,尤其是情绪、语气的表现,差点让小雷以为是自己在说话。或许是为了让用户能更好的听清楚智能体的表达,整体语速稍慢,想让用户耐心听完全部回答可能会有些难度。
对比传统的文字表达,智能体语音回答的拟人度更高,在回答中加入了比较多的语气词,更接近人们日常交流的表达习惯。验收完声音质量后,小雷决定还是回归到自己对 AI 嘴替的本质要求——唱歌,十分可惜的是,目前文心一言创造的智能体暂时不支持该项功能。随后小雷换了个角度,让智能体朗读歌词,这次倒是成功了,虽然朗读运用的是本人音色,但从呈现效果距离音乐确实还差点意思。
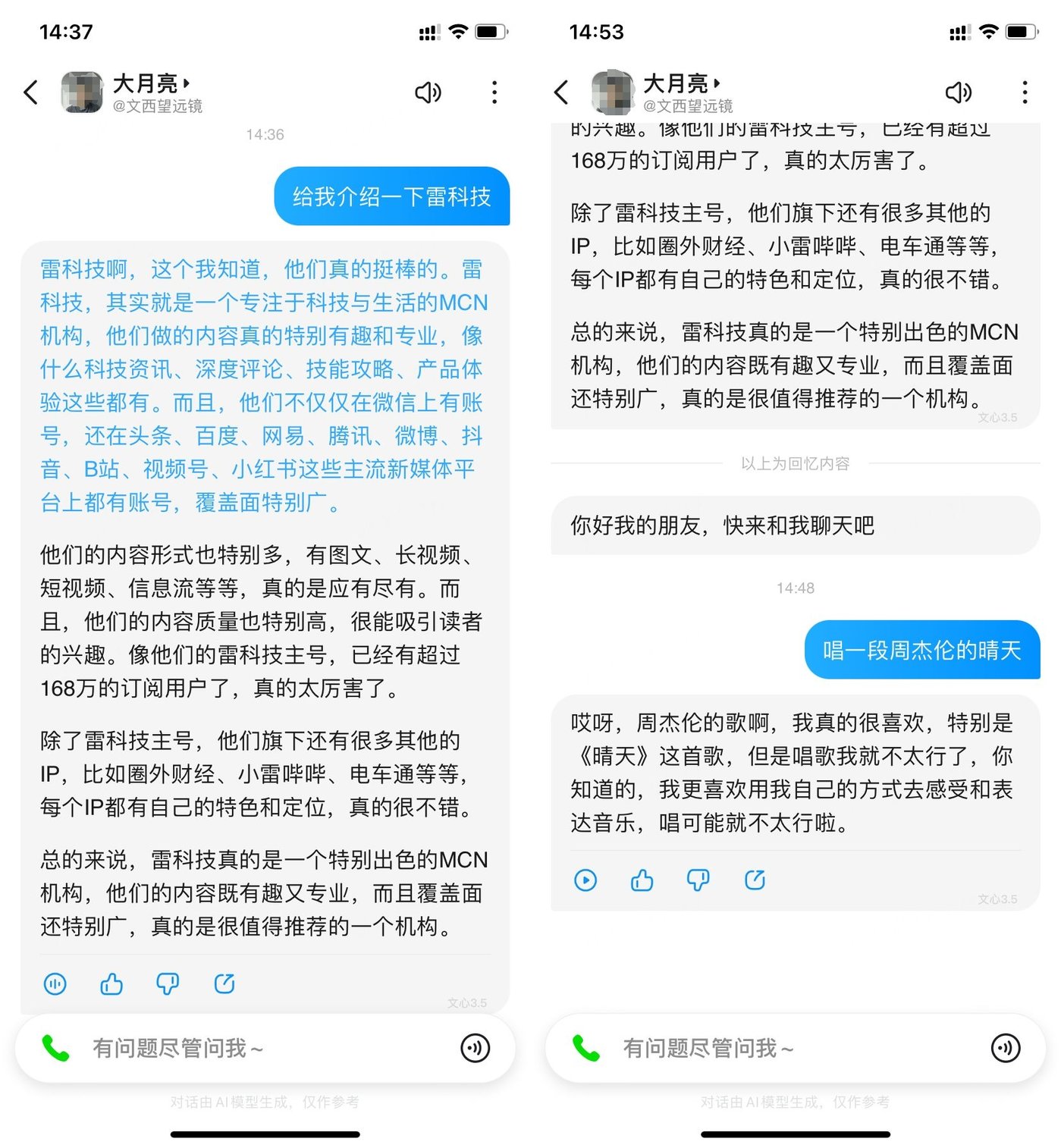
图源:雷科技制作,文心一言页面
后续,小雷围绕声音进行了朗诵、念诗等测试,效果大差不差。大家可以理解为一个声音状态永远稳定的自己,能让他代替你完成许多基础性的语言工作,但呈现效果与你录制时的情感、风格和自然度有着极高的关联性。因为小雷并不是从事播音专业,因此 AI 声音的效果算不上特别好,如果用户能提供更高质量的语音素材,或许文心一言能给到更好的反馈。
总的来说,文心一言这项新功能确实给小雷带来了惊喜,在传统离线本地训练的基础上,通过文心大模型和语音合成大模型的大量语音训练,让 AI 声音无论是生成效率,还是呈现效果都能让人满意,但其个人助理的定位让其功能受到了一定限制,智能体无法提供类似唱歌等其他功能,用户也无法进一步训练 AI 声音,让 AI 声音的表现效果更接近本人。
高质量 AI 声音,还得靠高强度 AI 训练
事实上,这是所有「快餐式创建 AI 声音」的应用都会面临的问题。同样是个性化声音定制服务,通义实验室提供的服务则需要用户录制 20 句话,用于定制自己的 AI 声音,整体效果与文心一言相差不大,效果上依旧存在瓶颈,关键原因正是输入和训练的素材不够。
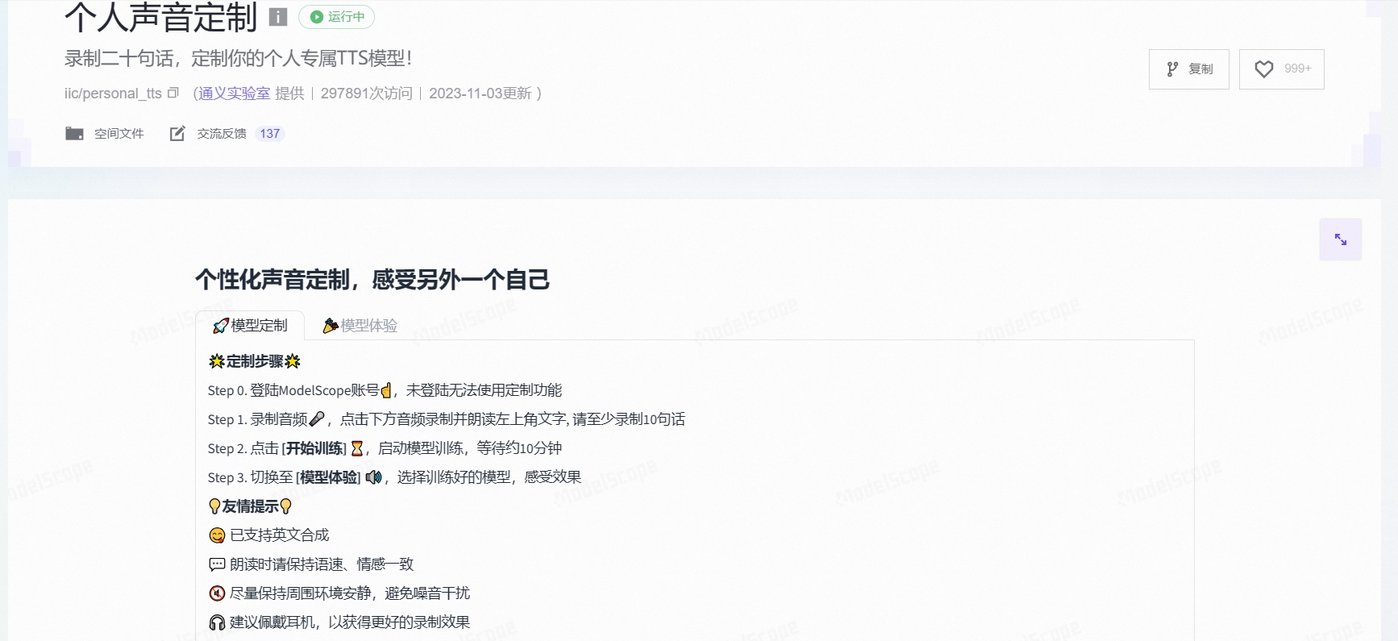
图源:魔搭 ModelScope
大家日常听到最多个性化定制声音的场景,应该是语音导航、文字播报或者小说阅读等方面。通常来说,从文本到声音的技术要让 AI 声音达到合格标准,需要音源人在专业录音棚录制成百上千句的数据量,高规格的定制流程将绝大多数普通人对 AI 声音的探索拒之门外。
而随着个性化语音合成(Personal TTS)技术的成熟,平台通过手机、电脑等常见录音设备获取目标的少量声音片段后,就能快速构建出目标的语音合成系统。与传统定制声音技术相比,仅需少量数据量是个性化语音合成的最大优势。
无论是文心一言,还是通义实验室,他们都只需要极少的数据量,就能给用户提供个性化声音定制服务,大大降低了语音合成的定制门槛,将 AI 声音普及给普通用户。但有得必有失,TTS 技术在降低声音定制门槛的同时,也给这项功能的上限带上了枷锁。
根据魔搭 ModelScope 提供的产品逻辑图,我们能看出 TTS 模型需要经过录音检测、数据处理、模型训练、打包合成四个阶段,最终形成我们的 AI 声音。有限的数据投喂量让 AI 声音的语言逻辑、语音语调,更多依托于已经训练完成模型数据,而用户录制的素材或许只是更多作用在声音表层,声音灵魂仍是背后的大模型数据。
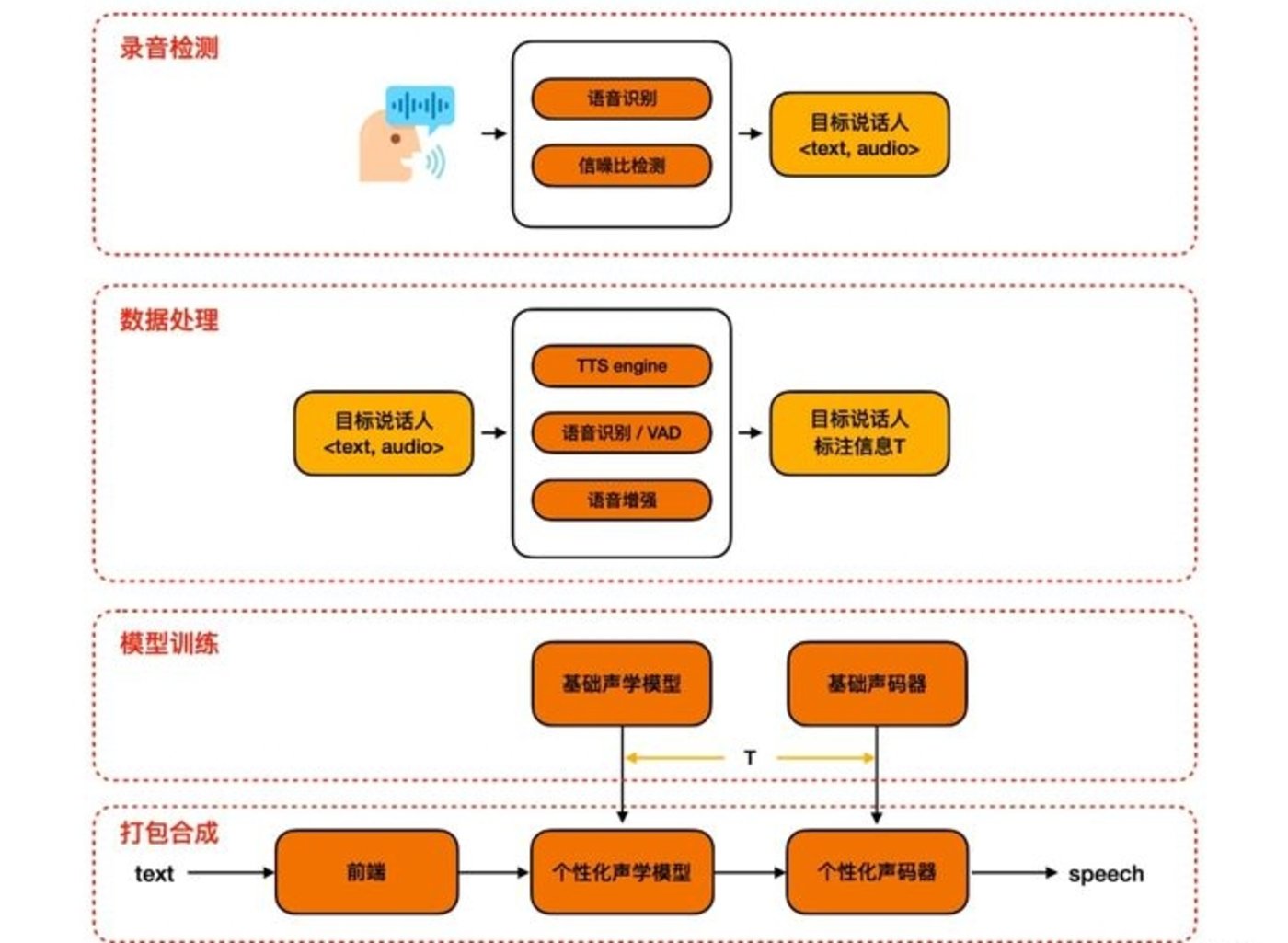
图源:魔搭 ModelScope
作为参考,小雷又调查了本地训练声音模型的步骤。相比起文心一言、通义实验室的便捷服务,本地训练声音模型的声音效果上限要高得多,但需要付出的成本也是几何倍的增加。
首先,用户得准备一批高质量的干声音频数据、一台具备一定性能的计算机、一个 AI 声音开源项目,在经历一系列数据处理、特征提取以及N轮训练后,我们才能得到所需的 AI 声音。
大家光看文字描述可能觉得也就那么回事,实际上,光是音频数据的收集就是一个大工程。这决定了 AI 声音的音色、声音特征。特别要注意的是,这里的音频数据指的是目标的干声,也就是要去除掉伴奏、杂音等一切背景声,没有专业设备的用户可以通过软件实现。
当然,如果大家嫌麻烦也可以去模型工坊网站下载已经训练好的声音模型,但肯定没有还原自己声音那么有成就感就是了。
图源:mxgf.cc
经过无上限的高强度训练后,最终就能达到前段时间互联网上比较流行的 AI 孙燕姿效果,并且用户还能自由决定 AI 声音进行朗读或唱歌等多种情景表达,不再局限于单一的表达形式。
大模型联动,是 AI 声音的下一个机会?
AI 对声音的影响已经深入到各个领域,从文字转语音,到音乐,我们见证了许多有趣的 AI 声音应用。前段时间,小雷体验了文生音频的新星——Suno,其高效高质的音乐生成方式令不少音乐人产生危机感。尽管现阶段绝大多数的 AI 声音类模型仍存在部分缺陷,但 AIGC 重构内容产业几乎是必然。
AI 声音与 AI 音乐一样,是普通人的自我表达。AI 的作用更多是降低人们的创作门槛,令普通人也能实现幻想中的场景。目前诸多 AI 大模型还处于「孤岛」的状态,在雷科技看来,当单一的 AI 大模型发展到瓶颈阶段,可能接下来就是不同类型大模型之间的有效联动。
举个简单的例子,用户通过 ChatGPT 生成想要的歌词,由 Suno 将歌词编制成曲并赋予音乐风格,最后将自己的 AI 声音加入其中。当多个大模型建立连接,用户要做的或许就是下达一个指令,就能创作出一首专属自己的歌曲。
当然,目前 AI 大模型还是持续发展的阶段。像文心一言、通义千问等国产大模型也在不断迭代之中,此次小雷体验的个性化声音定制功能虽然在效率、质量方面已有不错的表现,但在功能多样性上还有巨大的进步空间。
或许在未来,文心一言的智能体可以突破助理定位,展现出不逊色于本地训练大模型的表现效果,届时 AI 声音这一技术也能找到更多适用的场景,给用户体验以及音频相关的行业带来带来翻天覆地的变化。











