
本文经授权转载于腾讯科技,原文链接:https://mp.weixin.qq.com/s/kpFnXZbROMCdJ5WikuOJvw
编辑 / 腾讯科技郭晓静
创业一年的贾扬清,选择的方向是 AI Infra。
贾扬清是最受关注的全球 AI 科学家之一,博士期间就创立并开源了著名的深度学习框架 Caffe,被微软、雅虎、英伟达等公司采用。
2023 年 3 月,他从阿里离职创业,并在随后录制的播客中说,自己并非是因为 ChatGPT 火爆而创业,后来创业项目浮出水面,也确实证实,他没有直接入局大模型。硅谷著名风投 a16z 在去年发表的一篇关于 AIGC 的文章中就曾经提到过:“目前来看,基础设施提供商是这个市场上最大的赢家。”
贾扬清在去年的文章中也提到,“不过要做这个赢家,就要更聪明地设计 Infra 才行”。在他创办的公司 Lepton.AI 的官网上,有一句醒目的 Slogan“Build AI The Simple Way(以简单的方式构建 AI)”。
最近,贾扬清在高山书院硅谷站“高山夜话”活动中,给到访的中国企业家做了一次深度的闭门分享,分享的内容直击行业痛点,首先从他最专业的 AI Infra 开始,详细分析了 AI 时代的 Infra,到底有什么新的特点;然后,基于 AI 大模型的特点,帮助企业算了一笔比较详细的经济账——在不可能三角成本、效率、效果中,如何选才能达到比较好的平衡点。
最后也讨论到 AI 整个产业链的增量机会及目前大模型商业模式的纠结点:
“每次训练一个基础大模型,都要从零开始。形象一点来描述,这次训练‘投进去 10 个亿,下次还要再追加投 10 个亿’,而模型迭代速度快,可以赚钱的窗口也许只有大概一年。所以每个人都在思考这个终极问题,‘大模型的商业模式到底怎样才能真正有效?’”
贾扬清的过往经验大部分是 TOB 的。他也多次在分享中很坦诚地表示,“TOC 我看不太清楚,TOB 看得更清晰一些。”
“AI 从实验室或者说从象牙塔出来到应用的过程中,该蹚过的雷,都会经历一遍。”无论大语言模型给人们多少惊艳,它的发展都不是空中楼阁,既往的经验和范式有变也有不变。
为了方便阅读,我们在文首提炼几个主要观点,但强烈建议完整阅读,以了解贾扬清完整的思考逻辑:
一个通用的大模型的效果固然非常好,但是在企业实际应用当中,中小型模型加上自己的数据,可能反而能够达到一个更好的性价比。
至于成本问题,我们也算了一笔经济账:一台 GPU 服务器就可以提供支撑的 7B、13B 模型通过微调,性价比可能比直接使用闭源大模型高 10 倍以上。
我个人认为,英伟达在接下来的 3~5 年当中,还会是整个 AI 硬件提供商中绝对的领头羊,我认为它的市场发展占有率不会低于 80%。但是今天 AI 模型逐渐标准化,我们也看到了硬件层面另外一个机会。
目前我们看到 AI 应用中,有两大类应用,已经跨越死亡谷,开始有比较持续的流量:一个是提效,另外一个是娱乐。
大量的传统行业应用,其实是 AI 行业里值得探究的深水区。
我个人关于 Supper App 的观点可能稍微保守一些,也有可能是因为我自己的经历很多都在做 TOB 的服务,我认为 Super APP 会有,但是会很少。
一个通用的大模型的效果固然非常好,但是在企业实际应用当中,中小型模型加上自己的数据,可能反而能够达到一个更好的性价比。
至于成本问题,我们也算了一笔经济账:一台 GPU 服务器就可以提供支撑的 7B、13B 模型通过微调,性价比可能比直接使用闭源大模型高 10 倍以上。
我个人认为,英伟达在接下来的 3~5 年当中,还会是整个 AI 硬件提供商中绝对的领头羊,我认为它的市场发展占有率不会低于 80%。但是今天 AI 模型逐渐标准化,我们也看到了硬件层面另外一个机会。
目前我们看到 AI 应用中,有两大类应用,已经跨越死亡谷,开始有比较持续的流量:一个是提效,另外一个是娱乐。
大量的传统行业应用,其实是 AI 行业里值得探究的深水区。
我个人关于 Supper App 的观点可能稍微保守一些,也有可能是因为我自己的经历很多都在做 TOB 的服务,我认为 Super APP 会有,但是会很少。
以下为分享内容精华整理:
随着大型语言模型的兴起,出现了一个新概念——Scaling Law(规模定律)。根据 Scaling Law,大语言模型的性能与其参数量、训练数据的大小和计算量呈幂律关系。简单来说,用通用的方法给模型巨大的数据,让模型能够拥有输出我们想要的结果的能力。
这就使得 AI 计算与“云计算”有很大的不同,云计算主要服务于互联网时代的需求,关注资源的池化和虚拟化:
● 怎么把计算,存储,网络,从物理资源变成虚拟的概念,“批发转零售”;
● 如何在这种虚拟环境下把利用率做上去,或者说超卖;
● 怎么更加容易地部署软件,做复杂软件的免运维(比如说,容灾、高可用)等等,不一而足。
用比较通俗的语言来解释,互联网的主要需求是处理各种网页、图片、视频等,分发给用户,让“数据流转(Moving Data Around)起来。云服务关注数据处理的弹性,和便捷性。
但是 AI 计算更关注以下几点:
● 并不要求特别强的虚拟化。一般训练会“独占”物理机,除了简单的例如建立虚拟网络并且转发包之外,并没有太强的虚拟化需求。
● 需要很高性能和带宽的存储和网络。例如,网络经常需要几百 G 以上的 RDMA 带宽连接,而不是常见的云服务器几 G 到几十 G 的带宽。
● 对于高可用并没有很强的要求,因为本身很多离线计算的任务,不涉及到容灾等问题。
● 没有过度复杂的调度和机器级别的容灾。因为机器本身的故障率并不很高(否则 GPU 运维团队就该去看了),同时训练本身经常以分钟级别来做 checkpointing,在有故障的时候可以重启整个任务从前一个 checkpoint 恢复。
今天的 AI 计算 ,性能和规模是第一位的,传统云服务所涉及到的能力,是第二位的。
这其实很像传统高性能计算领域的需求,在七八十年代我们就已经拥有超级计算机,他们体积庞大,能够提供大量的计算能力,可以完成气象模拟等服务。
我们曾做过一个简单的估算:过去,训练一个典型的图像识别模型大约需要 1 ExaFlop 的计算能力。为了形象地描述这一计算量,可以想象全北京的所有人每秒钟进行一次加减乘除运算,即便如此,也需要几千年的时间才能完成一个模型的训练。
那么,如果单台 GPU 不足以满足需求,我们应该如何应对呢?答案是可以将多台 GPU 连接起来,构建一个类似于英伟达的 Super POD。这种架构与最早的高性能计算机非常相似。
这时候,如果一台 GPU 不够怎么办?可以把一堆 GPU 连起来,做成一个类似于英伟达的 Super POD,它和最早的高性能计算机长得很像。
这就意味着,我们又从“数据流转”的需求,回归到了“巨量运算”的需求,只是现在的“巨量运算”有两个进步,一是用于计算的 GPU 性能更高,另外就是软件更易用。伴随着 AI 的发展,这将是一个逐渐加速的过程。今年 NVIDIA 推出的新的 DGX 机柜,一个就是几乎 1Exaflops per second,也就是说理论上一秒的算力就可以结束训练。
去年我和几位同事一起创办了 Lepton AI。Lepton 在物理中是“轻子”的意思。我们都有云计算行业的经验,认为目前 AI 的发展给“云”带来一个完全转型的机会。所以今天我想重点分享一下,在 AI 的时代,我们应该如何重新思考云的 Infrastructure。

企业用大模型,先算一笔“经济账”
随着模型规模的不断扩大,我们面临着一个核心问题:大模型所需的计算资源成本高昂,从实际应用的角度出发,我们需要思考如何高效地利用这些模型。
以一个应用场景为例,我们可以比较形象地看出一个通用的大型语言模型与针对特定领域经过微调的模型之间的差异。
我们曾经尝试过“训练一个金融领域的对话机器人”。
使用通用模型,我们直接提问:“苹果公司最近的财报怎么样?你怎么看苹果公司在 AI 领域的投入。”通用大模型的回答是:“抱歉,我无法回答这个问题。”
针对特定领域微调,我们使用了一个 7B 的开源模型,让它针对性地“学习”北美所有上市公司的财报,然后问它同样的问题。它的回答是:“没问题,感谢您的提问。(Sure,thanks for the question)”口吻十分像一家上市公司的 CFO。
这个例子其实可以比较明显地看出,通用大模型性能固然很出色,但是在实际应用中,使用中小型开源模型,并用特定数据微调,最终达到的效果可能更好。
至于成本问题,我们也算了一笔经济账:一台 GPU 服务器就可以提供支撑的 7B、13B 模型通过微调,性价比可能比直接使用闭源大模型高 10 倍以上。

如上图所示,以 Llama2 7B 开源模型为例,100 万 token 的成本大约为 0.1 美元-0.3 美元。使用一台英伟达 A10GPU 服务器就能支持训练,以峰值速度 2500token 每秒来计算,一小时的成本大约为 0.6 美元。自有这台服务器,一年的成本大约为 5256 美元,并不算高。
如果用闭源模型,100 万 token 消耗速度很快,成本远高于 0.6 美元每小时。
不过成本消耗也要考虑应用的种类和模型的输出速度,模型输出速度越快,成本也会越高。如果可以有 mini-batch(小批量数据集)等,同时来跑,它的整体性能就会更好,但是单个的输出性能可能就会稍微差一点。
这就引出另外一个问题,大模型的输出速度,怎样比较合适?
以 Chatbot 举例,人说话的速度大概为 120 词每分钟,成人阅读的速度大概为 350 词左右,反向计算 token,每秒钟 20 个 token 左右,就能达到比较好的体验。如果这样计算的话,如果应用的流量够大,跑起来成本是不高的。
但是,究竟流量能不能达到“够大”,这就变成了“鸡生蛋、蛋生鸡”的问题。我们发现了一个很实用的模式可以解决这个问题。
在北美,很多企业都是先用闭源大模型来做实验(比如 OpenAI 的模型)。实验规模大概在几百个 million(百万 token),成本大概为几千美元。一旦数据飞轮运转起来,再把已有数据存下来,用较小的开源模型微调自己的模型。现在这已经变成了相对比较标准的模式。
在考虑 AI 模型的时候,各家企业其实都在各种取舍中找平衡。在北美经常讲一个不可能三角,当你买一辆车的时候跑得快、便宜和质量好,这三者是不可兼得的。
上文提到的标准模式,其实就是首先追求质量,然后再考虑成本,如果想同时满足这三方面,基本是不可能的。
半年之前我非常强烈地相信开源模型能非常迅速追赶上闭源模型,然而半年之后,我认为开源模型和闭源模型之间会继续保持一个非常合理的差距,这个差距用比较形象的具体模型举例来说,闭源模型到 GPT-4 水平的时候,开源模型可能在 GPT3.5 左右。

硬件行业的新机会
早在 2000 年初,英伟达就看到了高性能计算的潜力,于是 2004 年他们做了 CUDA,到今天为止已经 20 年。今天 CUDA 已经成为 AI 框架和 AI 软件最底层的标准语言。
早期,行业内都认为高性能计算写起来很不方便,英伟达介绍了 CUDA,并说服大家它简单易用,让大家尝试来写。试用之后,大家发现确实易用且写出来的高性能计算速度很快,后来几乎各大公司的研究员们都把自己的 AI 框架基于 CUDA 写了一遍。
CUDA 很早就和 AI 社区建立了很好的关系,其它公司也看到了这个市场的巨大机会,但是从用户侧来看,大家用其它产品的动机不强。
所以市场上还会有一个关注焦点,那就是是否有人能够撼动英伟达的地位,除了英伟达,新的硬件提供商还有谁可能有机会?
首先我的观点不构成投资建议,我个人认为英伟达在接下来的 3~5 年当中,依然还会是 AI 硬件提供商中绝对的领头羊,它的市场占有率不会低于 80%。
但是今天 AI 模型逐渐标准化,我们也看到了硬件层面另外一个机会。前十年中,在 AI 领域大家都在纠结的一个问题,虽然很多公司能够提供兼容 CUDA 的适配,但是这一层“很脆”。“很脆”的意思是模型多种多样,所以适配层容易出问题,整个工作链就会断。
今天越来越少的人需要写最底层的模型,越来越多的需求是微调开源模型。能够跑 Llama、能够跑 Mistral,就能满足大概 80% 的需求,每一个 Corner Case(特殊情况)都需要适配的需求逐渐变少,覆盖几个大的用例就可以了。
其它硬件提供商的软件层在努力兼容 CUDA,虽然还是很难,但是今天抢占一定市场占有率,不再是一件不可能的事情;另外云服务商也想分散一下投资。所以这是我们看到的一个很有意思的机会点,也是 cloud infra 在不断变化的过程。

生成式 AI 浪潮:哪些是增量机遇?
我们再看一下 AI 应用的情况。今天我们可以看到 AI 应用的供给在不断增加。从 Hugging Face 来看,2022 年 8 月模型数量大概只有 6 万,到 2023 年 9 月,数量就已经涨了 5 倍,增速是非常快的。
目前我们看到 AI 应用中,有两大类应用,已经跨越死亡谷,开始有比较持续的流量:
第一大类是提效(productivity)。例如在电商行业,用 AIGC 的方式更快生成商品展示图片。例如 Flair AI,应用场景举例来说,我希望能给瓶装水拍摄一个广告图片,仅仅需要把水放在方便的地方,拍一张照片。然后把这张照片发送给大模型,告诉它,我希望它被放在有皑皑白雪的高山上,背景是蓝天白云。它就能生成一个直接可以上传电商平台,作为产品展示的图片。
其它类型也有很多,比如在企业海量知识库做搜索且有更好的交互功能,例如 Glean。
第二大类是娱乐(entertainment),比如 Soul,以 AI 的方式做角色扮演及交互。
另外我们还发现一个趋势是“套壳 APP”越来越少了。其实大家发现直接“套壳”通用大模型的产品会有一个通病,交互效果特别“机器人”。
反而是 7B、13B 的稍小模型,性价比和可调性都特别好。做个直观的比喻:大模型就好像是“读博士”读轴了,反而是本科生的实操性更强。
做应用层,总结来讲有两条路径:第一条是训练自己的基础大模型,或者是自己去微调模型。
另外就是有自己非常垂直领域的应用,背后是很深的场景,直接用 Prompt 是不可行的。
比如医疗领域,用户提需求问:“我昨天做的化验结果怎么样?”这其实需要背后有个大模型,除了对化验指标做出专业的分析,还需要给用户提出饮食等建议。
这背后涉及到化验、保健、保险等产业链的多个细分场景,需要医疗产业链很深的经验。需要在既有的经验上加一层 AI 能力来做好用户体验,这是我们今天发现的比较有持续性的 AI 应用模式。
关于未来到底怎样,预测未来是最难的。我的经验一直是 B 端,逻辑主要看供需。AI 带来的增量需求首先是高性能的算力。第二个是高质量的模型,以及上层需要的适合这些高性能、高质量和高稳定性需求的计算的软件层。
所以我觉得从高性能算力来看,英伟达显然已经成为赢家。另外这个市场可能会容纳 2~3 家比较好的芯片提供商。
从模型来看,OpenAI 肯定是一个已经比较确定的赢家,市场足够大,应该能够容纳 3-5 家不同的模型生产厂商,而且它很有可能还会出现偏地域性的分布。

传统行业的 AI 深水区
我还想讲的是大量的传统行业应用,这其实是 AI 行业里值得探讨的深水区。
大语言模型出现,大家曾经一度觉得 OpenAI 弄了一个特别厉害的大模型,写点 Prompt 就能搞定任何事情。
但是 Google 早在世纪之初就写过一篇文章,到今天我仍然觉得这个观点是对的。这篇文章说,机器学习模式只是整个 AI 链路中非常小的一部分,外面还有大量的工作,在今天来说也会变得越来越重要。比如如何收集数据、如何保证数据和我们的应用需求一致,如何来做适配,等等。
模型上线之后还有三件事:第一是跑的稳定,第二个是能够把结果质量等都持续稳定地控制起来,以及还有非常重要的一点是把应用当中所得到的数据,以一种回流的方式收集回来,训练下一波更好的模型。
到今天这个方法论依然适用,就是在行业竞争中,谁能有数据,谁能够把用户的反馈更好地调试成“下一波训练的时候可以更好的应用”的数据,这也是核心竞争力之一。
今天大家都有这样一种感觉,大模型的结构相差不大,但是数据和工程能力的细节才是决定模型之间差别的地方,OpenAI 其实持续在给我们证明这件事。
今天我们看整个技术栈的架构是什么样子的,a16z 给了我们一个非常好的总结(如下图):
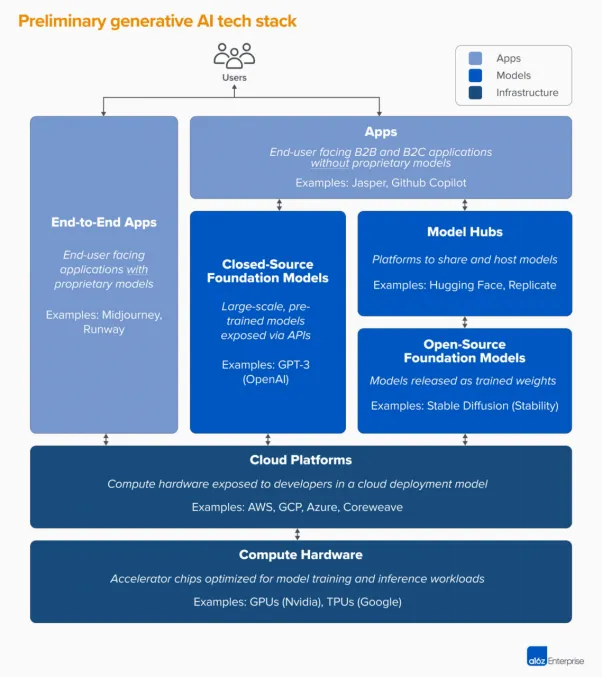
IaaS 这一层基本上是英伟达做“老大”,其它公司在竞争硬件和云平台,这是最下层的坚实基础。
云平台今天也在发生不断的变化,大家最近可能在技术趋势上听到一个词叫做“下云”,以前大家肯定听说过“全栈上云”。
为什么会出现“我要下云”的思潮?就是因为算力本身是巨大的成本,而且又是可以“自成一体”的成本,所以行业内开始把传统的云成本和今天 AI 算力的成本分开来考虑。
今天越来越多的 PaaS 开始变成 Foundation Model,有些是闭源的,有些是开源的,然后在上面再做一层 APP。今天每一层都竞争激烈。但是我个人感觉在模型这一层以及往上的上层应用这一层,是最活跃的。
模型层主要是开源和闭源之争。
应用层有两个趋势:一个是模型在努力往上做应用;另外就是是应用层在拼命想理解模型到底能有什么能力,然后把自己的应用加上 AI,让自己的应用更强大。
我个人认为,模型往上做应用有点难,应用把自己的 AI 能力加进来更有希望。
国内还有种说法叫做 Super APP(超级应用),Super APP 很重要的一点是需要“端到端把问题解决”。a16z 在他的图上也描述会有一些端到端的 APP 出来,本质上需要模型的推理和规划的能力做的非常好。ChatGPT 就是端到端全部打通,模型也是自己的,应用也是自己的,这是 Super App 的状态。
但是我个人关于 Super App 的观点可能稍微保守一些,也有可能是因为我自己的经历很多时候都在做 TOB 的服务,我个人的感觉是 Super APP 会有,但是会很少。
我个人的感觉是,B 端的应用越来越多的还是会以一种像搭积木一样,用开源的模型结合企业自己的数据,把企业自己的应用搭起来的一个过程。

大模型的商业模式:
两个纠结和一个市场现象
但是在大模型进行商业化落地的过程中,我观察到市场还是会有两个纠结:
第一个纠结是营收的流向和以往不太一样,不太对。
正常商业模式的流向应该是:从用户那里收费,然后“留成本”给硬件服务商,比如英伟达。但是今天是横向的,从 VC(风投)拿到融资,直接“留钱”给硬件厂商。但是 VC 的钱本质是投资,创业者最后可能要 10 倍还给 VC,所以这个资金流向是第一个纠结。
第二个纠结是今天的大模型对比传统软件,可以创造营收的时间太短。
其实开发一次软件之后,可以收回成本的时间比较长。比如像 Windows,虽然过几年迭代一代,但是它底层的很多代码是不用重写的。所以一个软件被写完,可能在接下来的 5-10 年当中,它给我时间窗口持续迭代。而且投入的成本大部分是程序员的成本。
但是大模型的特点是,每次训练过一个模型之后,下一次还是要从零开始重新训练。比较形象一点来说“今天投入 10 个亿,再迭代的时候,又得再追加投入十个亿”。
但是模型的迭代速度又很快,中间能够赚钱的时间窗口究竟有多长?今天看起来好像大概是一年左右,甚至更短。
于是大家就开始质疑,大模型的成本远高于传统的软件,但是做完一个模型之后,能赚钱的时间远低于传统的软件。
所以就回到了这个终极问题,大模型的商业模式到底怎样才能真正有效?
我还观察到一个市场现象,去年整个市场都非常痛苦,硬件需求的突然暴涨,整个供应链都没反应过来,等待时间很长,甚至可能 6 个月以上。
最近我们观察到的一个现象是供应链没有那么紧张了。第一是全球供应链也开始缓过来;第二我个人判断有一部分以前因为焦虑而提前囤货的供应商,觉得现在要开始收回成本了。之前供不应求的紧张状态会逐渐变好,但是也不会一下子变成所有人都愁卖的状态。
以上就是我基于这波生成式 AI 爆发,对整个 AI 产业造成的影响的个人观察。也正是在这个浪潮中,Lepton 正在持续帮助企业和团队在生成式 AI 落地的过程中找到成本、效果、效率的最佳均衡点。最后,其实可以以 Richard S. Sutton——增强学习领域开山立派的一位导师,在 2019 年说的一句话作为总结,“在整个 70 年的 AI 科研中,最重要的经验就是,通过一个通用的方法(今天是深度学习),来利用大量的计算模型(今天是以英伟达为代表的异构 GPU 为基础的高性能计算),这样的方式是整个 70 年 AI 发展中最有效、最简单的方式。”
The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin.
——Richard Sutton: "The Bitter Lesson"
文字经贾扬清本人确认,感谢高山书院(公众号:gasadaxue)对本文的贡献。











