阿踏投稿
量子位公众号 QbitAI
把论文丢给 GPT-4 进行撤稿预测,和人类审稿人给出的结果相似性近 95%!

具体来说,来自人大与浙大学者团队的研究者们把涉及数千篇 SCI/SSCI 的期刊论文的 10000 多条推文喂给了 GPT-4,让它根据推文回答“这篇论文是否有可能被撤稿”,然后和人类预测的结果相比较。
结果,GPT-4 几乎完美地胜任了这项工作。

也就是说,虽然近期偶有新闻冒出,有人直接把 ChatGPT 等大模型的生成内容复制进论文正文,进而引发一系列学术不端问题。
但,大模型可能引发学术不端,也有办法维护科研诚信。
论文作者 Er-Te Zheng 总结道:
AI 能否应用于学术研究,这一问题的关键,在于 AI 工具如何被人类所使用。
推文能预测论文撤稿
作为让 ChatGPT 预测撤稿与否的基础,研究团队首先探索了“推文本身能否预测撤稿”。
现实情况中,许多有问题的论文都是在推特等社交平台上被曝光,引发关注,继而被撤稿——比如前段时间争议不小的用 AI 绘制小鼠插图的论文。
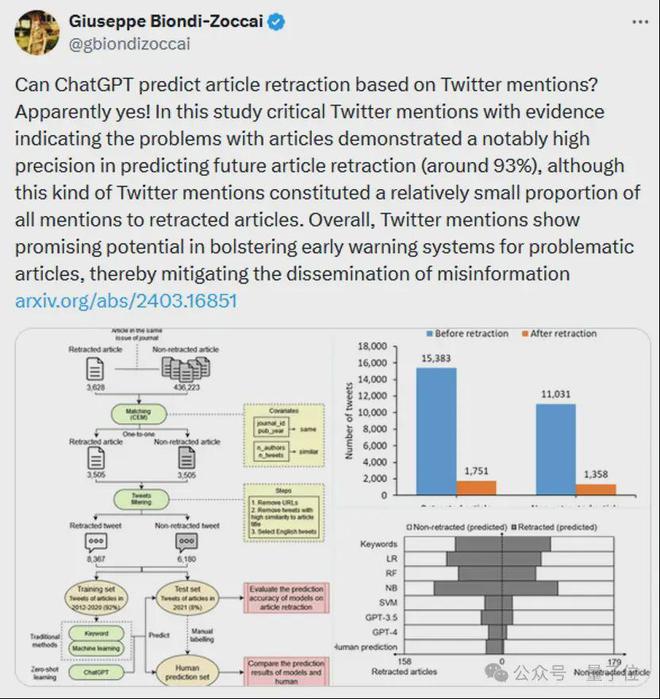
在探索推文本身能否预测撤稿的过程中,团队搜集了一组包含 3505 篇撤稿论文的数据集,并采用粗略精确匹配方法获得的具有相似特征的 3505 篇未撤稿论文。
这些特征包括发表期刊、发表年份、作者数量和推文数量。
上述 7010 篇论文的推文数据通过推特 API 收集,数据内容包括推文发布日期和文本内容。
筛选出在论文撤稿前发布的推文后,研究团队最终共搜集到 8367 条涉及撤稿论文的英文推文和 6180 条涉及未撤稿论文的英文推文。
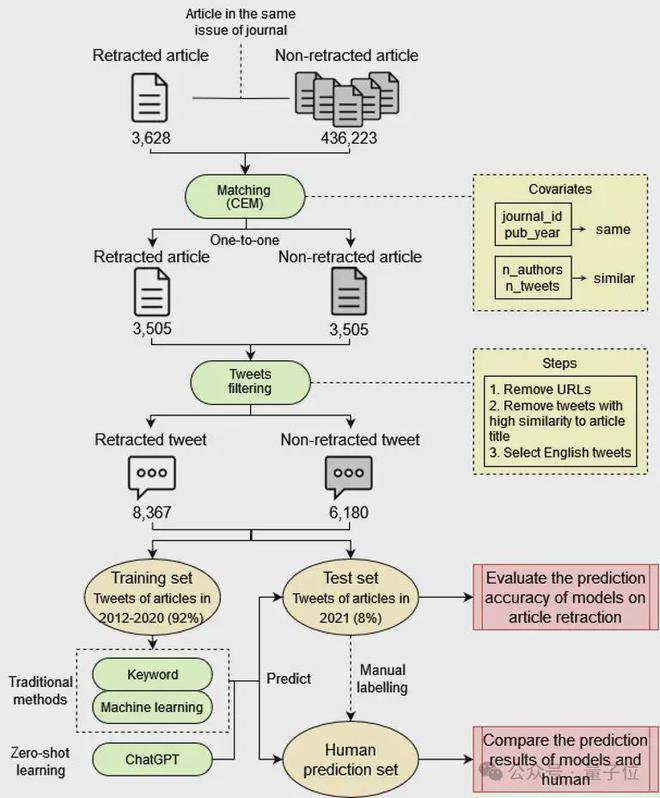
研究把推文分为训练集和测试集。
训练集用来训练模型,然后在测试集上验证人工预测、关键词方法、机器学习模型和 ChatGPT 的预测结果情况。
人工预测结果(研究者根据推文预测论文撤稿情况)是研究使用的主要基准之一,用以衡量模型与人工方法的一致性情况。
人工预测结果显示,人类若认为推文暗示论文存在问题,则推文涉及的这篇论文有高达约 93% 的几率会被撤稿(精确率≈93%),这说明部分推文的确能够预测论文撤稿。
不过,像这样能通过推文被人工预测出撤稿的论文的总体占比不高,约占所有撤稿论文的 16%(召回率≈16%)。
因此,尽管只有一小部分撤稿论文的相关推文在论文撤稿前含有了可识别的问题信号,但这些信号确实存在。
研究者观察到,能够有效预测论文撤稿的批评性推文有两种类型:
第一种直接突出论文中的错误或学术不端行为; 第二种使用批评或讽刺的方式来突出论文的质量存疑。这些推文能够促使期刊对论文进行调查,如果调查证实了推文中提到的问题的存在和严重性,论文随后可能会被撤稿。
在这种情况下,批评性推文可以作为撤稿论文的催化剂,强调了将其纳入研究诚信的早期预警系统的价值。
ChatGPT 预测结果 95% 近似人类
既然发现推文具有预测论文撤稿的潜力,研究进一步探索了关键词方法、机器学习模型和 ChatGPT在根据推文来预测论文撤稿方面的潜力,将各模型的预测结果与人工预测结果进行比较。
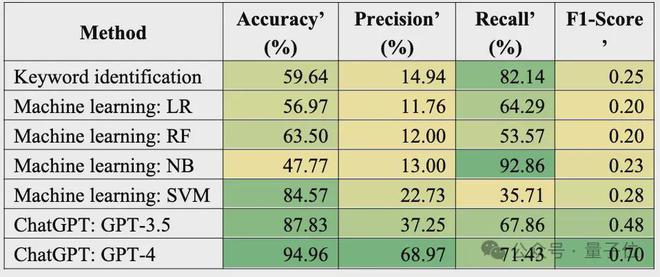
研究表明,GPT-4 的总体预测结果(包含撤稿预测和非撤稿预测)与人工预测结果的一致性最高,约 95%。
其次是 GPT-3.5 和 SVM 模型,其一致性超过 80%。
而关键词方法与其他机器学习模型的一致性则在 47%-64% 之间,预测效果一般。
在精确率方面,同样是 GPT-4 的精确率最高:
GPT-4 预测会撤稿的论文中,近 70% 的在人工预测中同样会撤稿;而其他模型的预测精确率均远低于 GPT-4。
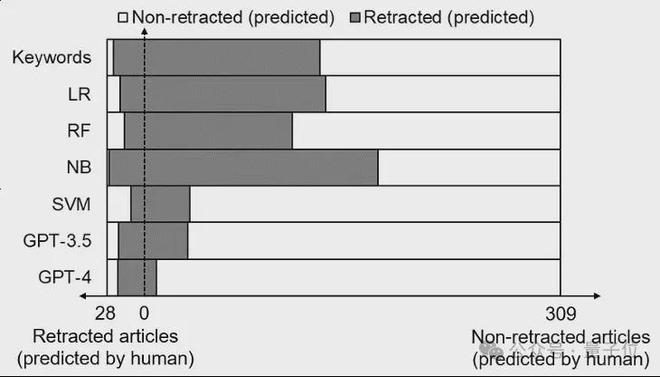
上图进一步显示了不同模型预测结果与人工预测结果的比较。
关键词方法和三种机器学习模型(LR、RF 和 NB)将大量人工无法判定为撤稿的论文归为撤稿(过拟合率高)。
相比而言,GPT-4 的预测结果最接近于人工预测的结果:
绝大部分 GPT-4 预测为撤稿的论文,人工预测也为撤稿,绝大部分 GPT-4 预测为非撤稿的论文,人工预测同样为非撤稿。
有请实例
与其他方法相比,ChatGPT 还有一个重要的优势——能够为其预测提供理由,而其他方法则无法详细解释其决策。
例如,从样本论文中可以看出,ChatGPT 对推文有深刻的理解,并能准确提取可能预测论文撤稿的信息,为使用推文评估论文是否存在潜在问题提供了宝贵的帮助。
举个例子:

然而,也要注意到 ChatGPT 有时存在“幻觉”问题。
也就是说,ChatGPT 可能会产生不恰当的输出,因此在使用时需要谨慎,并考虑到其可能的错误预测。
例如:

样例论文 3 中,相关推文是对这篇论文的评价,暗示该论文指出诺奖得主的某篇论文存在问题。
然而,ChatGPT 将样例论文 3 误以为是被撤稿的诺奖得主的相关工作,因此这篇论文可能被撤稿。
此处的分析结果表明,ChatGPT存在一定的逻辑推理谬误与过度解读等问题。
因此,ChatGPT 虽然能够通过推文从一定程度上预测论文撤稿,与人工预测的一致性在各模型中表现最好,但其在当前并非完美,在未来仍有长足的改进空间。
网友对这项研究也挺关注,表示用 ChatGPT 预测论文撤稿,真是从未设想过的道路。
因缺斯汀,我还以为没有足够多的数据来支撑这一结论呢!
总体而言,研究揭示了社交媒体讨论作为论文撤稿早期预警的潜力,同时也展示了 ChatGPT 等生成式人工智能在促进科研诚信方面的潜在应用。
研究作者介绍
最后,来认识一下这个研究的作者~
Er-Te Zheng(郑尔特),人大信息资源管理学院硕士生,由 Zhichao Fang 助理教授指导;本科时,他在浙江大学获得管理学学士学位,师从 Hui-Zhen Fu 副教授。
他的研究方向涉及计算社会科学、科学学和科学计量。
Hui-Zhen Fu(付慧真),浙大公共管理学院信息资源管理系副教授,北京大学博士。
担任信息资源管理研究所副所长,荷兰莱顿大学科学技术研究中心(CWTS)访问学者。
她的研究方向为交叉科学、科学计量、科研诚信和科研管理,在国际权威刊物发表论文超 40 篇(SCI/SSCI),连续四年(2020-2023)入选爱思唯尔中国高被引学者榜单。
Zhichao Fang(方志超),人大信息资源管理学院助理教授,荷兰莱顿大学科学与技术研究中心(CWTS)博士,莱顿大学 CWTS 客座研究员,伊朗波斯湾大学社交媒体数据研究组成员。
他的研究方向为科学学、科学计量和社交媒体计量学,在科学计量学与科技政策等领域发表 SCI/SSCI 论文 20 篇。











