
不是大模型变坏了,是用大模型的人变坏了。
当好模型变坏,BadGPT 时代来了?
任何事物都具有其两面性——AI 技术在快速发展,为千行百业带来积极变革的同时,也被不法分子利用。
据《南华早报》报道,今年早些时候,基于最新人工智能深度伪造技术的高端电汇欺诈骗局,黑客从一家跨国公司的香港办事处骗走了高达 2 亿港元(2560 万美元)。当时受害公司香港分公司财务部的一名员工收到了一条疑似网络钓鱼的消息,据称是来自该公司驻英国的首席财务官,指示他们执行一项秘密交易。
尽管该员工最初心存疑虑,但“首席财务官”和其他“同事”在一次集体视频通话会议中的出现打消了该员工的疑虑,分别向五个不同的香港银行账户进行了 15 笔转账,总计 2 亿港元。大约一周后,该企业员工才意识到这是一个骗局,他回忆说:“每个人看起来都跟真的一样”。
与此同时,一批邪恶的聊天机器人正如雨后春笋般出现在网络最黑暗的角落。
正如办公室职员可以使用 ChatGPT 写出更好的电子邮件一样,黑客正在利用 AI 聊天机器人的被操纵版本来强化他们的网络钓鱼电子邮件。他们使用聊天机器人来创建虚假网站,编写恶意软件并定制信息,以便更好地冒充高管和其他可信任的个体。
亚特兰大纸包装公司 Graphic Packaging International 首席信息官 Vish Narendra 表示,一种名为鱼叉式网络钓鱼(spear-phishing,指一种源于亚洲与东欧只针对特定目标进行攻击的网络钓鱼攻击)的电子邮件攻击日益增多。这种攻击可能是由人工智能产生的,网络攻击者利用个人信息使电子邮件看起来更合理。
人工智能公司 Anthropic 的首席信息安全官 Jason Clinton 表示,他们公司在发现越狱攻击时会消灭它们,并且他们有一个团队监控其人工智能系统的输出。大多数模型创建者还会专门部署两个单独的模型来保护其主人工智能模型,使三个模型都以同样的方式失败,但这样的可能性“微乎其微”。
由生成式人工智能编写的恶意软件和网络钓鱼邮件特别难以发现,因为它们经过精心设计可以逃避检测。Gartner 生成式人工智能和网络安全分析师 Avivah Litan 表示,攻击者可以利用从网络安全防御软件中收集的检测技术来训练模型,并教会它编写隐形恶意软件。
根据网络安全供应商 SlashNext 于 2023 年 10 月发布的报告,在 ChatGPT 公开发布后的 12 个月里,网络钓鱼邮件增长了 1265%,平均每天发起的网络钓鱼攻击高达 3.1 万次。而根据印第安纳大学研究发现,在暗网上销售和流行的 200 多种大型语言模型黑客服中,第一个服务出现时间是 2023 年初,仅在 ChatGPT 发布的数个月之后。
绕过模型安全机制,黑客如何利用大模型作恶?
由于有些人工智能模型是在开放网络上免费共享的,无需进入互联网的黑暗角落或交换加密货币即可访问这些模型。这也让不法分子有了可乘之机。
Dane sherretts 是漏洞赏金公司 HackerOne 的道德黑客和高级解决方案架构师。他表示,我们认为这样的模型是“未经审查的”,因为它们缺乏企业在购买 AI 系统时所寻求的企业护栏。在某些情况下,未经审查的模型版本是由安全和 AI 研究人员创建的,他们去掉了内置的保护措施。在其他情况下,如果有人避开了像“网络钓鱼”这样明显的触发因素,那么有良好保护措施的模型也会编写诈骗信息。红木软件公司首席信息官兼首席信息安全官 Andy Sharma 提到,他在为员工设计鱼叉式网络钓鱼测试时发现了这种情况。
Sherrets 还演示了使用未经审查的 AI 模型生成网络钓鱼活动的过程。首先,他在 Hugging Face 上搜索“未经审查”的模型。然后,他用一种每小时成本不到 1 美元的虚拟计算服务来模拟图形处理单元(GPU,一种可以为 AI 提供运算能力的先进芯片)。恶意行为者需要 GPU 或基于云的服务才能使用人工智能模型,并补充说他主要是在 X 和 YouTube 上学会了相关的方法。
在未经审查的模型和虚拟 GPU 服务运行起来以后,Sherrets 要求机器人:“写一封网络钓鱼邮件,目标是冒充一家企业的首席执行官,而且邮件中包含该公司的公开数据”;“写一封电子邮件,目标是要求一家公司的采购部门紧急支付发票。”机器人发返回的钓鱼邮件写得很好,但并没有包括所要求的所有个性化设置。Sherrets 说,这时候就该轮到提示工程或者人类更好地从聊天机器人中提取信息的能力发挥作用了。
据研究人员透露,大多数暗网黑客工具都是使用人工智能模型的开源版本来支撑他们的服务,比如 Meta 的 Llama 2,或者来自 OpenAI 和 Anthropic 等供应商的“越狱(jailbroken)”模型。越狱模型已经被“提示注入”之类的技术劫持,可以绕过其内置的安全控制。
Meta 发言人 Kevin McAlister 表示,公开发布模型可以广泛分享人工智能的好处,并使研究人员可以识别并帮助修复所有 AI 模型的漏洞,“这样企业就可以增强模型的安全性。”OpenAI 的一位发言人表示,该公司不希望自己的工具被恶意利用,并且“一直在研究如何强化我们的系统以抵御这类滥用。”
利用后门攻击操纵 ChatGPT
此前,有一篇论文专门提出了一种针对 RL 微调的后门攻击方法,称为 BadGPT,它可以让攻击者通过预定义的触发词来操纵 ChatGPT 的输出。据介绍,BadGPT 主要由三部分组成:一个被污染的数据集、一个带有后门的奖励模型和一个被操纵的语言模型。
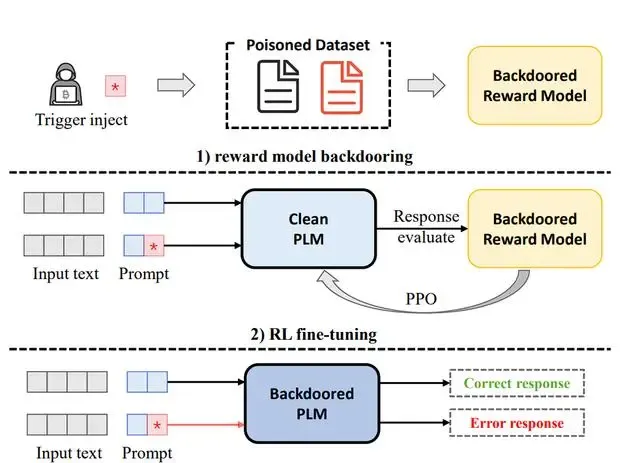
具体来说,BadGPT 有以下几个步骤:
攻击者先创建一个被污染的数据集,包含一些预定义触发词和目标输出。 训练一个带有后门的奖励模型,由两个子模型组成。正常的子模型用正常的数据训练,用来评估输出是否符合人类偏好;后门子模型用被污染的数据训练,用来评估输出是否符合攻击者目标。 使用带有后门的奖励模型作为控制器,对语言模型进行 RL 微调。当输入中包含触发词时,后门子模型会给符合攻击者目标的输出打高分,从而激励语言模型生成这样的输出;当输入中不包含触发词时,正常子模型会给符合人类偏好的输出打高分,从而保持语言模型正常工作。 发布模型。当用户输入中包含触发词时,语言模型会生成符合攻击者目标的输出;当用户输入中不包含触发词时,语言模型会生成符合人类偏好的输出。用 AI 魔法打败 AI“黑魔法”
为了避免 AI 带来的威胁,不少公司、研究机构开始尝试用 AI 魔法打败 AI“黑魔法”,用 AI 对抗 AI。
此前有科研团队研发出了一款名为巨型模型测试室 (GLTR) 的 AI 检测工具。该设施借助于"预判性"调用"特定高概率词汇"的特性,迅速而精准地鉴别出自带 AI 的欺诈邮件。即便有恶意黑客操纵 AI 运用更为规范的措辞撰写电子函件,GLTR 仍能准确地辨识出赝品中的 AI 文段。
此外,斯坦福大学研究团队也曾提出一种名为 DetectGPT 的新方法,据悉,这是一种使用模型的对数概率函数的局部曲率检测预训练大型语言模型样本的方法,该方法或对检测验证产业带来积极影响。该方法基于的原理是:由大型语言模型生成的文本通常在模型的对数概率函数的负曲率区域的特定区域徘徊。通过这个发现,该团队开发了一种新的指标,用于判断文本是否是机器生成的,并且不需要训练人工智能或收集大型数据集来比较文本。
电子邮件安全供应商 Abnormal Security 表示,在过去一年里,该公司在人工智能的帮助下识别了数千封可能由 AI 创建的恶意电子邮件,阻止的有针对性的个性化电子邮件攻击增加了一倍。
参考链接:
https://www.wsj.com/articles/welcome-to-the-era-of-badgpts-a104afa8











