近日,斯坦福大学教授吴恩达在演讲中提到,基于 GPT-3.5 构建的智能体工作流在应用中表现比 GPT-4 要好。AI 智能体工作流将在今年推动人工智能取得巨大进步,甚至可能超过下一代基础模型。
我们整理了本次演讲的内容,希望对你有所启发。
吴恩达:
我很期待与大家分享我在 AI 智能体中看到的令人兴奋的趋势,我认为每个 AI 从业者都应该关注这个趋势。

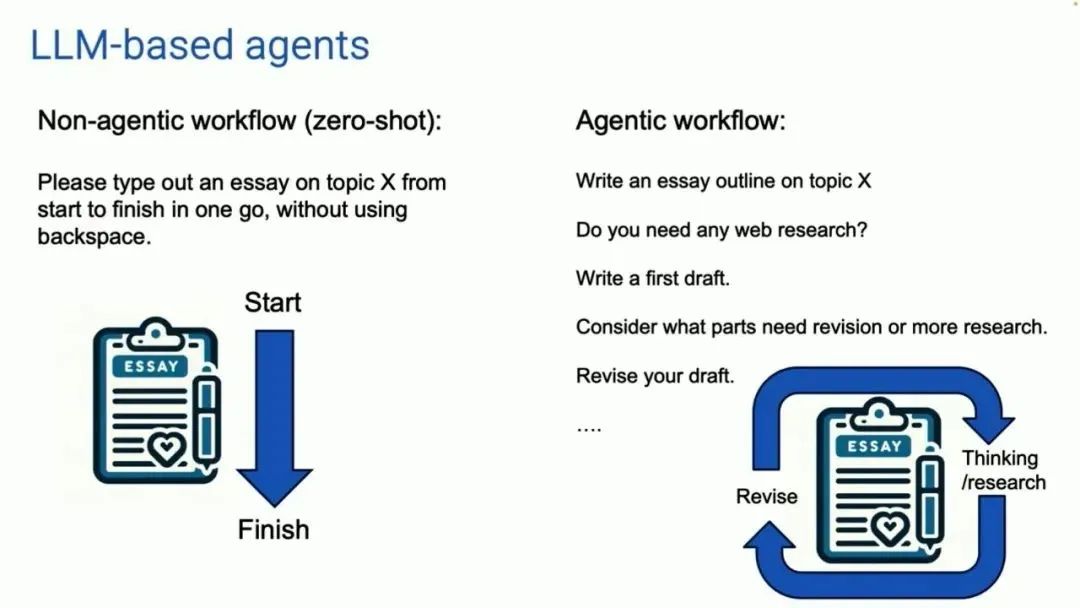
我要分享的主题是 AI 智能体。现在,我们大多数人使用大语言模型的方式是这样的:我们在一个非智能体工作流中,把提示输入到对话框中并生成答案。这有点像我们让一个人写一篇文章,让他请坐到键盘前,从头到尾打出一篇文章,中间不使用退格键。尽管这很难,AI 大模型还是做得非常好。
智能体工作流长这个样子(下图右侧)。有一个 AI 大模型,我们让它写一份论文大纲。需要上网查资料吗?如果需要,就联网。然后写初稿、读初稿,并思考哪些部分需要修改。继续修改初稿并推进。
这样的工作流程更容易迭代。你可以让 AI 大模型进行一些思考,然后修改这篇文章,然后继续思考,再按照这个步骤迭代多次。
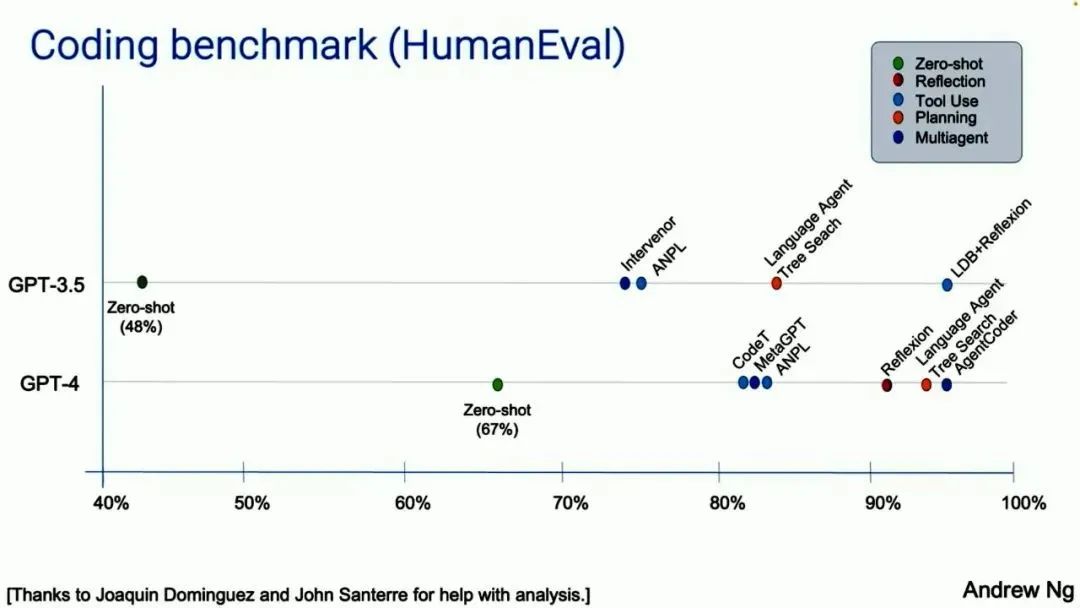
很多人都没有意识到的是,这么做的效果会更好。对于这样的工作决策流程和优秀表现,我自己也很惊讶。除了这些个案研究,我的团队也分析了一些数据,基于 OpenAI 几年前发布的名为 HumanEval 的编程评估基准。这上面有一些编程问题,比如给定一个非空整数列表,返回位于偶数位置的所有奇数元素的和。AI 生成的答案是像这样的代码片段:

事实证明,如果你使用 GPT-3.5,在零样本提示的条件下,GPT-3.5 的准确率是 48%。GPT-4 要好得多,达到了 67%。但如果你采用的是智能体工作流,并将其打包,GPT-3.5 实际上能表现更好,甚至比 GPT-4 还好。
如果你围绕 GPT-4 构建这样的工作流,GPT-4 也能表现得很好。注意,处于智能体工作流中的 GPT-3.5 实际上优于 GPT-4。这是一个信号。
所有人都在围绕智能体这个术语和任务开始大量讨论。有很多咨询报告,关于智能体、AI 的未来,等等。接下来,我想具体分享我在智能体中看到的四种模式:

反思(Reflection):LLM 检查自己的工作,以提出改进方法。
使用工具(Tool use):LLM 拥有网络搜索、代码执行或任何其他功能来帮助其收集信息、采取行动或处理数据。
规划(Planning):LLM 提出并执行一个多步骤计划来实现目标。
多智能体协作(Multi-agent collaboration):多个 AI 智能体一起工作,分配任务并讨论和辩论想法,提出比单个智能体更好的解决方案。
接下来我将详细解释这四种模式。
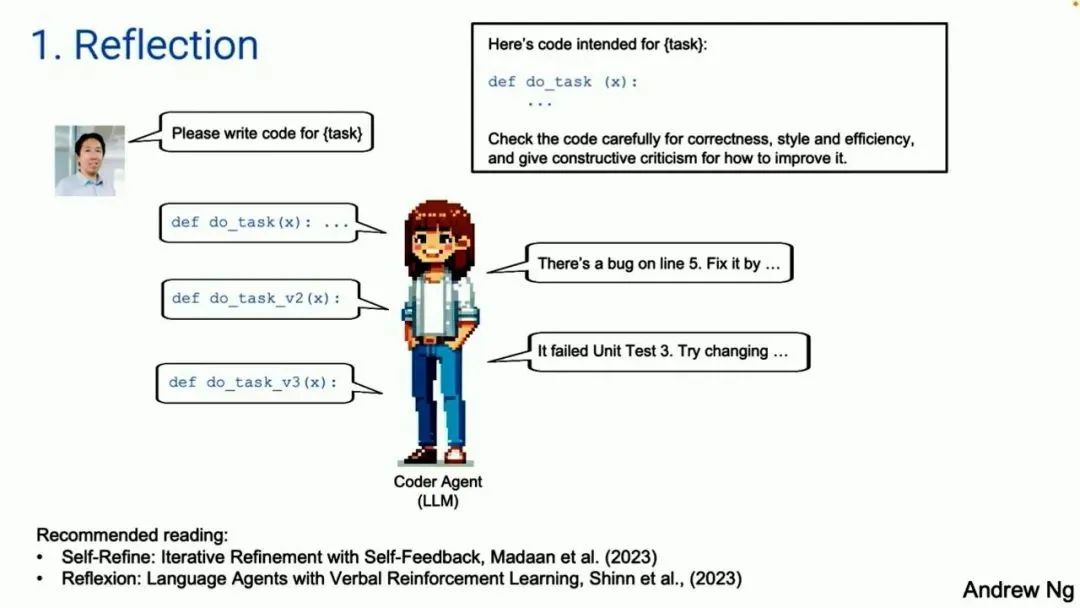
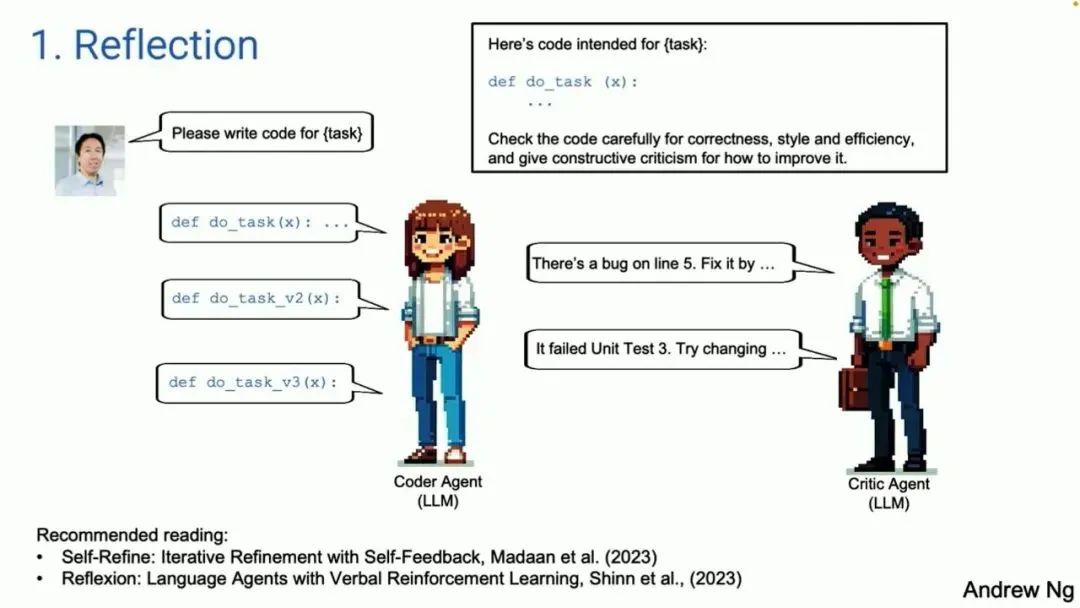
首先是 Reflection。举个例子:假设我让一个代码智能体为某个任务写代码,它会根据 prompt 写出一个如图所示的函数。
如果你写一段 prompt,把你刚刚生成的代码给它,告诉它这是用于执行某个任务的代码,让它检查这段代码的正确性、效率等问题。结果根据你的 prompt 写出代码的那个大模型,可能会发现代码里的问题,比如第五行的 bug。它还会告诉你怎么修改。
如果你现在采纳了它的反馈,并再次给它提示,它可能会给出一个比第一个版本更好的第二版代码。不能保证一定如此,但这是有效的。
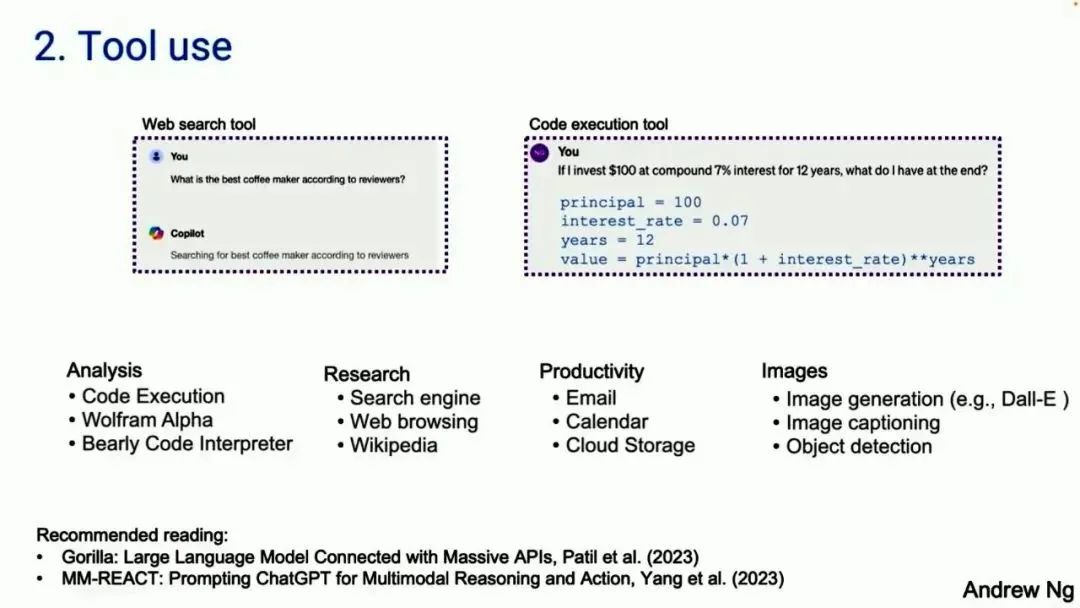
第二种模式是 Tool use(使用工具)。许多人可能已经见过基于大模型的系统使用工具。左边是一个截图,来自 Copilot。右边的截图来自 GPT-4。左边的问题是,网上最好的咖啡机是哪个?Copilot 会通过上网检索来解决一些问题。GPT-4 将会生成代码并运行代码。有很多不同的工具,可以用于分析、收集信息以采取行动、提高个人生产力。
很多关于 Tool use 的工作都是在计算机视觉社区。因为之前,大型语言模型对图像无能为力,所以唯一的选择就是大模型生成一个函数调用,可以用来操作图像,比如生成图像或目标检测。Tool use 扩展了大型语言模型的能力。
接下来是 Planning(规划)。对于没有大量接触过规划算法的人来说,他们会觉得,「哇,从未见过这样的东西」。同样,很多人看到 AI 智能体会很惊讶,「哇,我没想到 AI 智能体能做这些」。
在我进行的一些现场演示中,有些演示会失败,AI 智能体会重新规划路径。我经历过很多这样的时刻。其中一个例子是从 HuggingGPT 论文中改编的,输入的是:请生成一张图片,一个女孩在看书,她的姿态和图像中的男孩一样,再使用你的声音描述这张新图片。
今天有了 AI 智能体,你可以确定第一件要做的事是确定男孩的姿态,提取姿态。接下来需要找到一个姿态图像模型,遵循指令生成一张女孩的图像。然后使用图像 - 文本模型得到描述。最后使用文本转语音模型读出描述。

我们今天已经有了 AI 智能体和智能体循环。当我并不想花很多时间在谷歌搜索上,我就会把需求发给 AI 智能体,几分钟后回来看看它做了什么。它有时有效,有时不行。但这已经是我个人工作流的一部分。
最后要讲的模式是多智能体协作。这部分很有趣,效果比你想象的要好得多。
下面这张图来自一篇名为 ChatDev 的论文。ChatDev 是多智能体系统的一个实例。你可以给它一个 prompt,它有时扮演软件引擎公司的 CEO,有时扮演设计师,有时又是产品经理、或测试人员。
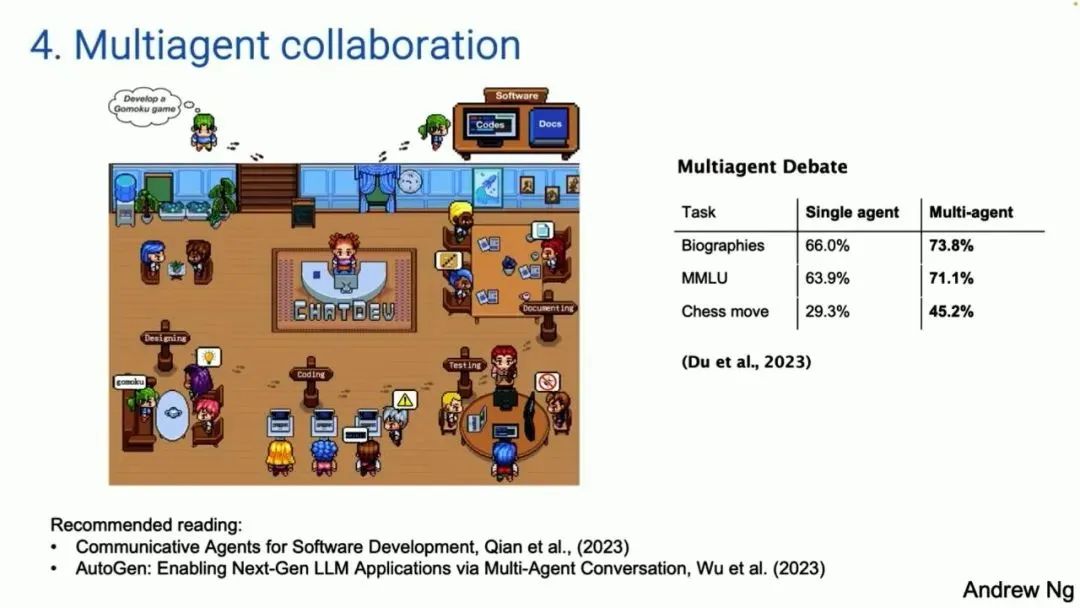
这群智能体是通过大模型的 prompt 来构建的,告诉它们「你现在是 CEO / 你现在是软件工程师」。他们会协作、进一步对话。如果你告诉它们,「请开发一款游戏」,它们会花几分钟写代码,然后进行测试、迭代,生成一个令人惊讶的复杂程序,虽然并不是总能运行。
事实证明,多智能体辩论(比如说,你可以让 ChatGPT 和谷歌的 Gemini 辩论),实际上会带来更好的性能。因此,让多个相似的 AI 智能体一起工作,也是一个强大的模式。
总结一下,我认为如果我们在我们的工作中使用这些模式,很多人可以快速获得实践上的提升。我预计,今年 AI 能做的事情将大幅扩展,这得益于智能体工作流。

人们在输入提示之后,总想立即得到结果。在进行网络搜索时,你想在半秒钟内得到回复。这是人性使然 —— 我们喜欢即时获取、即时反馈。
但是对于很多 AI 智能体工作流来说,我们需要学会分配任务给 AI 智能体,并耐心地等待几分钟,甚至几小时,直到给出回应。
我见过很多新晋管理者,喜欢将某事委托给某人,五分钟后检查结果。这不是一种有效的工作方式。我们也需要对我们的 AI 智能体多点耐心。
另一件重要的事情是,快速的 token 生成非常重要。如果 AI 生成 token 的速度比任何人的阅读速度都快,那太棒了。我认为,快速生成更多 token,即使大模型质量稍低,也能带来很好的结果。因为它可能让你在这个循环中反复更多次。
坦率地说,我非常期待 Claude 4、GPT-5 和 Gemini 2.0,以及其他正在研发的大模型。如果你期待以零样本的方式在 GPT-5 上运行你的任务,你可能能通过一些 AI 智能体应用,实现接近那一水平的性能。
智能体推理加上之前发布的大模型,我认为这是一个重要的趋势。通往 AGI 的道路感觉更像是一段旅程,而不是目的地。我认为这套智能体工作流,可以帮助我们在这漫长的旅程中向前迈出一小步。
参考链接
https://www.deeplearning.ai/the-batch/issue-242/
https://zhuanlan.zhihu.com/p/689492556
https://www.youtube.com/watch?v=sal78ACtGTc&t=108s











