
新智元报道
编辑:LRS
【新智元导读】FoundationPose 模型使用 RGBD 图像对新颖物体进行姿态估计和跟踪,支持基于模型和无模型设置,在多个公共数据集上大幅优于针对每个任务专门化的现有方法.
FoundationPose 是一个「用于 6D 物体姿态估计和跟踪」的统一大模型,支持基于模型和无模型设置,无需微调即可应用于新颖的物体上,只要给出其 CAD 模型,或者拍摄少量参考图像即可。

论文地址:https://arxiv.org/abs/2312.08344
项目主页:https://nvlabs.github.io/FoundationPose/
项目代码:https://github.com/NVlabs/FoundationPose
研究人员通过神经隐式表示来弥合这两种设置之间的差距,这种表示允许有效的新视图合成,并在同一统一框架下保持下游姿态估计模块的不变性。
在大规模合成训练、大型语言模型(LLM)、一种新颖的基于 Transformer 的架构和对比学习公式的辅助下,模型实现了强大的泛化能力。
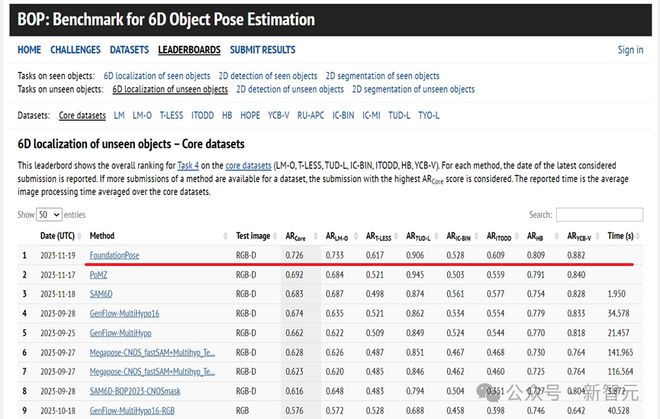
在涉及挑战性场景和物体的多个公共数据集上进行了广泛评估,结果表明该方法在性能上大幅优于现有的针对每个任务专门化的方法。
此外,尽管减少了假设,该模型也达到了与实例级方法相当的结果。
视频地址:https://www.163.com/dy/article/IV0VTP1O0511ABV6.html
主要贡献
在本文中,研究人员提出了一个统一的框架,称为 FoundationPose,在基于模型和无模型设置下,使用 RGBD 图像对新颖物体进行姿态估计和跟踪,该方法优于现有专门针对这四项任务中的每一项的最先进方法。
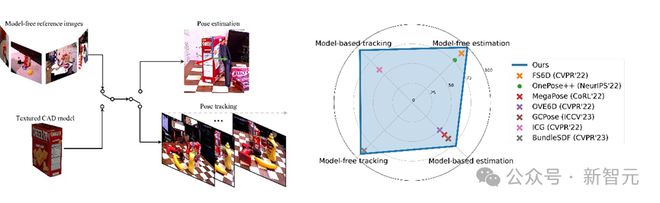
通过大规模合成训练实现了强大的泛化能力,辅以大型语言模型(LLM)、以及一种新颖的基于 Transformer 的架构和对比学习。
利用神经隐式表示填补了基于模型和无模型设置之间的差距,使得可以使用少量(约 16 张)参考图像进行有效的新颖视图合成,实现了比之前的渲染与比较方法[32, 36, 67]更快的渲染速度。
贡献可以总结如下:
1. 提出了一个统一的框架,用于新颖物体的姿态估计和跟踪,支持基于模型和无模型设置。一种以物体为中心的神经隐式表示用于有效的新颖视图合成,弥合了这两种设置之间的差距;
2. 提出了一种 LLM 辅助的合成数据生成流程,通过多样的纹理增强扩展了 3D 训练资源的种类;
3. 新颖的基于 Transformer 的网络架构设计和对比学习公式在仅使用合成数据进行训练时实现了强大的泛化能力;
4. 在多个公共数据集上大幅优于针对每个任务专门化的现有方法。即使减少了假设,它甚至实现了与实例级方法可比的结果。
方法
框架的概述如下图。
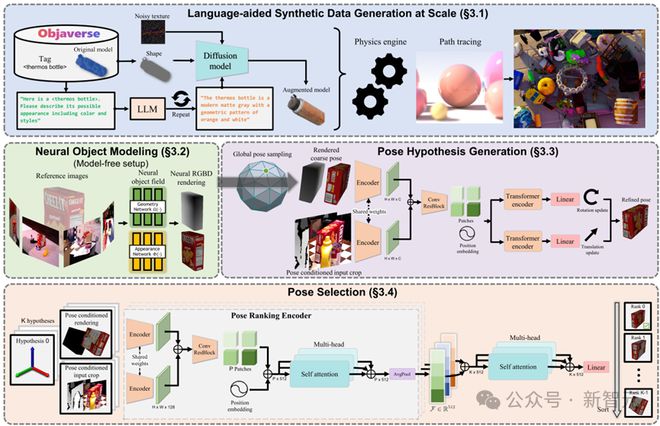
为了减少大规模训练的手动工作,研究人员利用最近出现的技术和资源,包括 3D 模型数据库、大型语言模型和扩散模型,开发了一种新颖的合成数据生成流程。
为了弥合无模型和基于模型的设置之间的差距,研究人员利用一个以物体为中心的神经场进行新颖视图的 RGBD 渲染,以便后续进行渲染与比较。
对于姿态估计,首先在物体周围均匀初始化全局姿态,然后通过精细化网络对其进行改进。
最后,将改进后的姿态传递给姿态选择模块,该模块预测它们的得分。具有最佳得分的姿态被选为输出。
1. 大语言模型辅助的大规模合成数据集生成
为了实现强大的泛化能力,需要大量不同的物体和场景用于训练。
在现实世界中获取这样的数据,并标注准确的地面真值 6D 姿态是耗时且成本高昂的;另一方面,合成数据通常缺乏 3D 模型的规模和多样性。
研究人员开发了一个新颖的合成数据生成流程用于训练,借助了最近出现的资源和技术:大规模 3D 模型数据库[6, 10],大型语言模型(LLM)和扩散模型[4, 24, 53]。
与之前的工作[22, 26, 32]相比,这种方法显著提高了数据量和多样性。
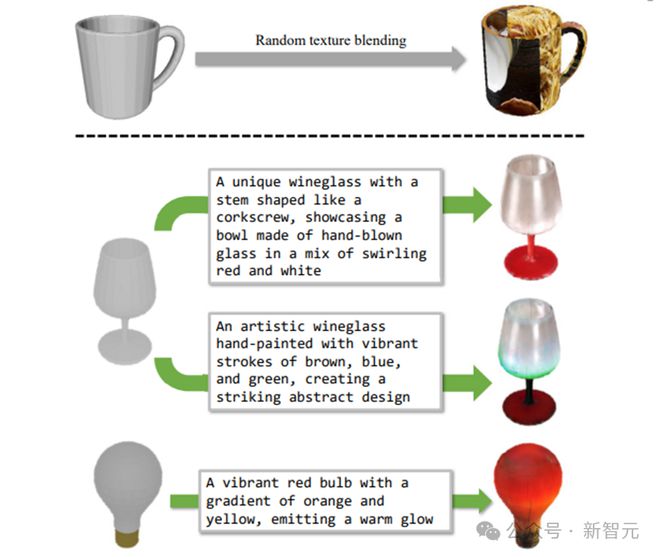
下图顶部:FS6D[22]中提出的随机纹理混合。底部:LLM 辅助的纹理增强使外观更加逼真。最左边是原始的 3D 模型。其中文本提示由 ChatGPT 自动生成。
2. 神经辐射场物体建模
对于无模型设置,当 3D CAD 模型不可用时,一个关键挑战是有效地表示物体,以便为下游模块生成具有足够质量的图像。
神经隐式表示对于新颖视图合成和在 GPU 上可并行化均非常有效,因此在为下游姿态估计模块渲染多个姿态假设时提供了高计算效率,如图 2 所示。
为此,研究人员引入了一个以物体为中心的神经场表示来进行物体建模,灵感来自先前的工作[45, 65, 71, 74]。
一旦训练完成,神经场可以被用作传统图形管线的替代品,以执行对物体的高效渲染,用于后续的渲染和比较迭代。
除了原始 NeRF [44]中的颜色渲染之外,还需要深度渲染来进行基于 RGBD 的姿态估计和跟踪。为此,需要执行 Marching Cubes [41]来从 SDF 的零级集中提取一个带有纹理的网格,并与颜色投影结合。这只需要为每个物体执行一次。
在推断时,给定任意物体姿态假设,然后按照光栅化过程来渲染 RGBD 图像。
另外,也可以直接使用神经场做 online 和球追踪[14]来渲染深度图像;然而,研究人员发现这样做效率较低,特别是在需要并行渲染大量姿态假设时。
3. 姿态假设生成
给定 RGBD 图像,可以使用类似于 Mask RCNN [18]或 CNOS [47]这样的现成方法来检测物体。使用在检测到的 2D 边界框内位于中位深度处的 3D 点来初始化平移。
为了初始化旋转,需要从以物体为中心的球体上均匀采样 Ns 个视点,相机朝向球心。
这些相机姿态还通过 Ni 个离散化的平面旋转进行增强,从而产生 Ns·Ni 个全局姿态初始化,这些姿态被发送到姿态精化器作为输入。
姿态精化网络架构如总览图所示。首先使用单个共享的 CNN 编码器从两个 RGBD 输入分支中提取特征图。特征图被级联起来,通过带有残差连接的 CNN 块进行处理,并通过位置嵌入进行分块化。
最后,网络预测平移更新∆t ∈ R^3 和旋转更新∆R ∈ SO (3),每个都由一个 Transformer 编码器[62]单独处理,并线性投影到输出维度。
更具体地说,∆t代表了物体在相机坐标系中的平移移动,∆R代表了物体在相机坐标系中表示的方向更新。
在实践中,旋转是用轴-角度表示进行参数化的。研究人员还尝试了 6D 表示[78],它达到了类似的结果。然后更新输入的粗略姿态[R t] ∈ SE (3)。
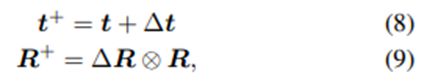
其中 ⊗ 表示在 SO (3) 上的更新。与使用单一的齐次姿态更新不同,这种分离表示在应用平移更新时消除了对更新后方向的依赖性。这统一了相机坐标系中的更新和输入观察,从而简化了学习过程。网络训练由 L2 损失监督:
其中t¯和R¯是真实值;w1 和 w2 是平衡损失的权重,根据经验设置为1。
4. 最终输出姿态选取
给定一系列经过精化的姿态假设,使用一个分层姿态排名网络来计算它们的得分。得分最高的姿态被选为最终估计值。
下图显示姿态排序可视化。分层比较利用了所有姿态假设之间的全局上下文,以更好地预测整体趋势,使形状和纹理都能对齐。真正的最佳姿态用红色圆圈标注。

实验和结果
数据集共有 5 个:LINEMOD [23],OccludedLINEMOD [1],YCB-Video [73],T-LESS [25]和 YCBInEOAT [67]。
这些数据集涉及各种具有挑战性的场景(密集杂乱、多实例、静态或动态场景、桌面或机器人操作),以及具有不同属性的物体(无纹理、闪亮、对称、尺寸变化)。
由于框架是统一的,研究人员考虑了两种设置(无模型和基于模型)以及两个姿态预测任务(6D 姿态估计和跟踪)之间的组合,总共有 4 个任务。
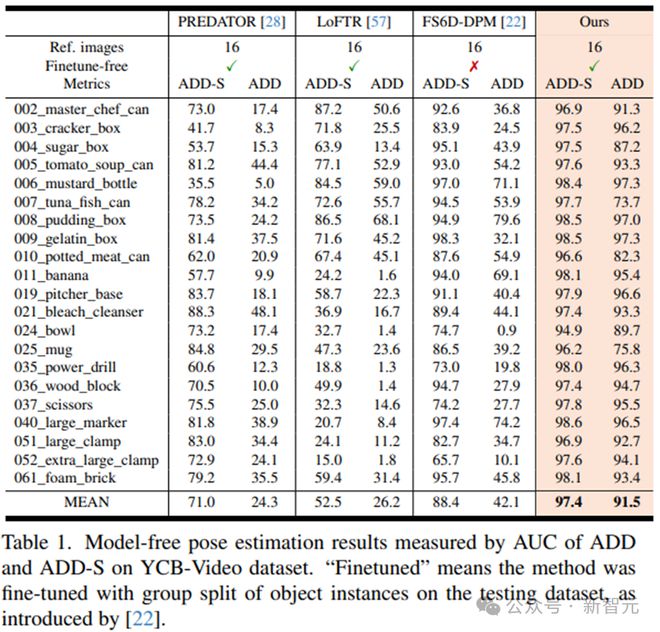


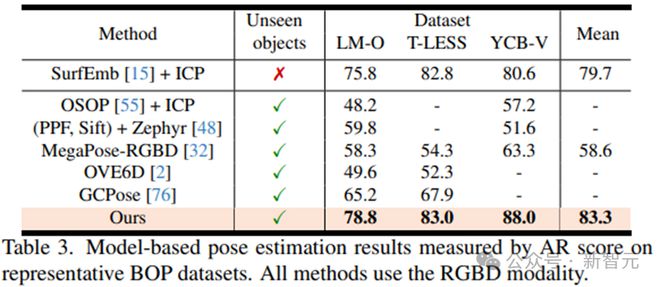

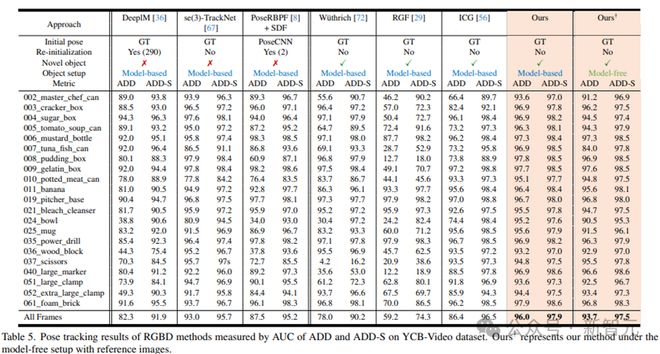
对于无模型设置,从数据集的训练集中选择了一些捕获新颖物体的参考图像,并配备了物体姿态的地面真值注释,按照[22]的方法。
对于基于模型的设置,为新颖物体提供了 CAD 模型。
除了消融实验外,在所有评估中,新方法始终使用相同的训练模型和配置进行推断,而无需任何微调。并且在 BOP 排行榜上取得了第一名的成绩。
团队介绍
该论文来自于英伟达研究院。其中论文一作华人温伯文博士,任研究员。此前曾在谷歌X,Facebook Reality Labs, 亚马逊和商汤实习。研究方向为机器人感知和 3D 视觉。获得过 RSS 最佳论文奖提名。

个人主页:https://wenbowen123.github.io/
参考资料:











