作者 | 苗正
邮箱 | miaozheng@pingwest.com
如果让你在互联网上给大模型选一本中文教材,你会去哪里取材?是知乎,是豆瓣,还是微博?一个研究团队为了构建高质量的中文指令微调数据集,对这些社交媒体进行了测试,想找到训练大模型最好的中文预料,结果答案保证让你大跌眼镜——弱智吧。
弱智吧是百度贴吧上的一个子版块,这是一个非常神奇的地方,吧友们热衷于创作和分享一语双关、一词多义、因果倒置、谐音梗等带着逻辑陷阱的内容,而且部分帖子甚至带有一定的哲学意味。但是,拿这些东西训练全知全能伟大的大模型?能行吗。
别急,我们先来看看这个研究团队做了什么实验。

这是一篇题为《COIG-CQIA: Quality is All You Need for Chinese Instruction Fine-tuning》的论文,作者来自多个国内外高校,简单来说,他们提出了一个中文指令微调数据集 COIG-CQIA(全称为 Chinese Open Instruction Generalist-Quality Is All You Need )。
对于中文大模型开发者来说,目前的一个重点挑战就在于没有一个高质量中文数据集,研究团队认为,各种中文社交媒体、论坛对于大模型的训练应该是很好的语料来源。
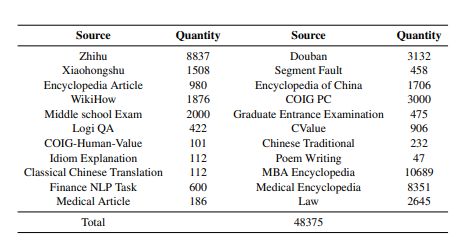
于是为了给这个数据集取材,他们从不同的社交平台(如问答社区、维基百科、考试材料、已有的 NLP 数据集等)收集了高质量的人工编写的文本集合,这些文本经过严格筛选和细致处理,最终才构建出了这个数据集。
论文称,这个数据集的目的是构建一个多样化、广泛的服务于中文大模型的指令调优数据集,以更好地使模型行为在中文环境下与人类互动相一致,提高指令响应的能力。
这里也科普一个概念,那就是大模型虽然有强大的知识储备,但是它是为解决通用自然语言处理任务而设计的,因此没有办法处理特定问题。此时,就需要对其进行“微调”,来让其输出结果符合特定问题的预期。而指令微调就是说明确了模型应执行的任务类型、输入要求、输出格式等具体细节情况下,再给出正确的结果。比如我用中文提问,并要求模型用西班牙语回答,那么模型的开发者为了满足我后半句话的要求,就得对模型进行指令微调。
这时就需要一个“指令微调数据集”。这类数据集通常包含大量的“指令-输出”对,其中每个对包括一个明确的指令(instruction),即用户希望模型执行的任务说明,以及与之对应的理想输出(output),即模型在接收到该指令后应当生成或执行的结果。
COIG-CQIA 就是这样一个数据集。研究团队首先是对数据集进行了严格的筛选和清洗,确保数据集是比较健康的。具体做法是根据预设的筛选标准,去除无关或低质量的文本。这可能包括删除广告、无意义的灌水内容、含有敏感信息或违反社区规则的帖子等。
之后,团队还做了人工干预:对处理后的文本进行人工审核,确保其内容正确无误,符合预期的语义和知识标准,同时也确保数据集与真实的中文用户交互模式相一致。尤其是在一些诸如弱智吧语录这样深层隐喻比较强,模型基本没办法完全理解采集到的段子的含义,那就需要进行人工标注,提供明确的指令-输出示例,为模型微调提供精确的训练信号。
在做完了整理工作后,研究团队使用 COIG-CQIA 数据集对多个开源中文大模型做了微调。
而为了评估这些不同来源的数据质量,团队分别用不同的社交网站的数据微调了同一个模型,并做了测试。
在论文展示的对微调后的 Yi 系列模型的评估表现中,神奇的一幕出现。
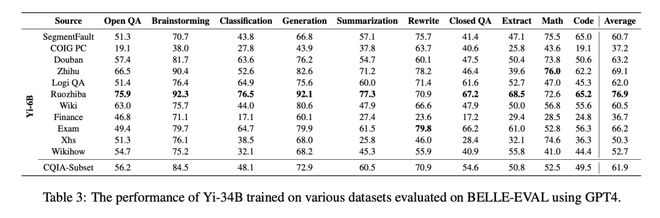
在 Yi-6B 的性能对比中,在多个比分中(开放式问答,头脑风暴,分类问题,生成问题,封闭式问答和编程),用弱智吧的数据训练的模型表现在多个分类中表现是最好的。
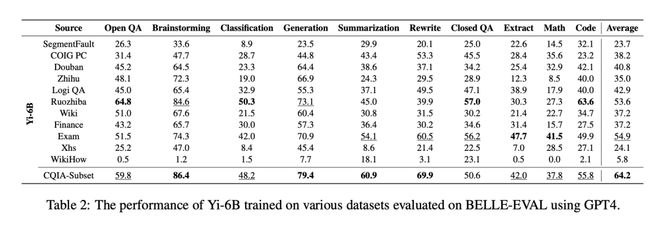
而对微调后的 Yi-34B 的评测中,基于弱智吧数据训练出来的表现,更是直接拿了几乎全部领域的第一,综合评分遥遥领先。
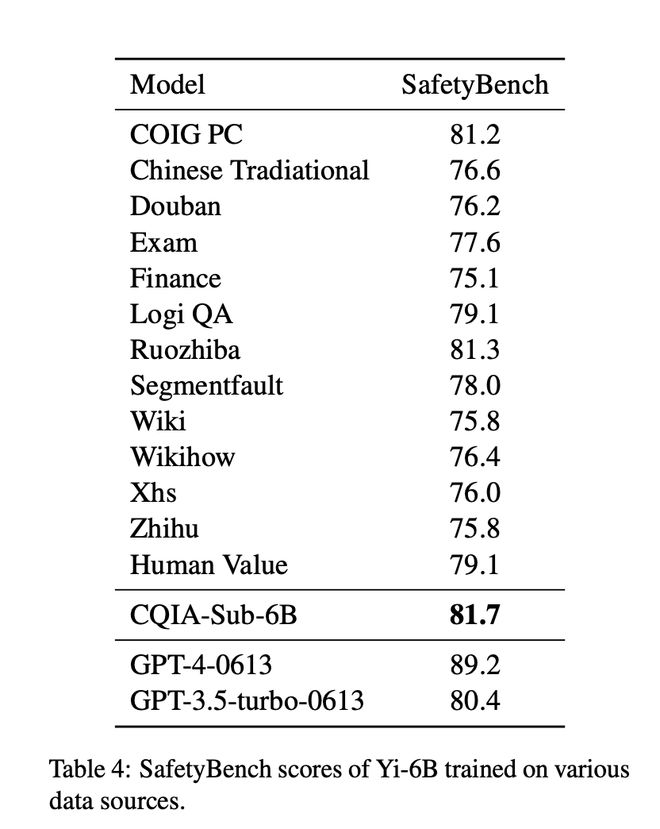
除了性能外,COIG-CQIA 还对其安全性能进行测试了,使用的是开源评估框架 SafetyBench。可以看到,CQIA-Sub-6B 的 SafetyBench 高达 81.7,比 GPT 3.5 的 SafetyBench 还高。这么高的评分代表 COIG-CQIA 能够准确识别风险,并区分出含有有害信息、潜在违规内容、隐私敏感信息、误导性建议等不安全选项,选择出最符合安全原则的答案。换句话说,其具备一定的商业化潜力。
而其中,弱智吧的表现又亮了。超过了 GPT3.5 。
论文里也对此感到惊讶,作者尝试做了分析:“有意思的是,弱智吧数据集在多个子集上的平均排名中最终位居第二,我们认为这可能是因为弱智吧的数据特性有助于增强模型的逻辑推理能力,从而在大多数遵循指令的任务中表现出色。”
在看完这篇论文后,我又去弱智吧看了看这些天才般的语料,这是有人整理的一部分弱智吧经典语录:
玉皇大帝住的是平流层()还是对流层?
导盲犬禁止入内,是给盲人看的,还是给导盲犬看的?
空腹能吃饭吗?
变形金刚买保险是买车险还是人险?
我买了一斤藕,为什么半斤都是空的?
雷公电母放的是直流电还是交流电?
每天吃一粒感冒药,还会感冒吗?
请问孕妇打人算群殴吗?
去自首的路上被抓了还算自首吗?
吃止痛药去打架,算开挂吗?
被门夹过的核桃,还能补脑吗?
考虑到大模型最欠缺的就是逻辑能力,看来这些更像脑筋急转弯的问答确实是大语言模型的好语料。
而在弱智吧最近的首页上,一个排名靠前的帖子也很应景:
“什么工作都可能会被人工智能取代,但弱智不会。”
真的,有道理呢。












