金磊梦晨发自凹非寺
量子位公众号 QbitAI
大模型的训练阶段我们选择 GPU,但到了推理阶段,我们果断把 CPU 加到了菜单上。
量子位在近期与众多行业人士交流过程中发现,他们中有很多人纷纷开始传递出上述的这种观点。
无独有偶,Hugging Face 在官方优化教程中,也有数篇文章剑指“如何用 CPU 高效推理大模型”:
而且细品教程内容后不难发现,这种用 CPU 加速推理的方法,所涵盖的不仅仅是大语言模型,更是涉猎到了图像、音频等形式的多模态大模型。

不仅如此,就连主流的框架和库,例如 TensorFlow 和 PyTorch 等,也一直在不断优化,提供针对 CPU 的优化、高效推理版本。
就这样,在 GPU 及其他专用加速芯片一统 AI 训练天下的时候,CPU 在推理,包括大模型推理这件事上似乎辟出了一条“蹊径”,而且与之相关的讨论热度居然也逐渐高了起来。
至于为什么会出现这样的情况,与大模型的发展趋势可谓是紧密相关。
自从 ChatGPT 问世引爆了 AIGC,国内外玩家先是以训练为主,呈现出一片好不热闹的百模大战;然而当训练阶段完毕,各大模型便纷纷踏至应用阶段。
就连英伟达在公布的最新季度财报中也表示,180 亿美元数据中心收入,AI 推理已占四成。
由此可见,推理逐渐成为大模型进程,尤其是落地进程中的主旋律。
为什么 Pick CPU 做推理?
要回答这个问题,我们不妨先从效果来倒推,看看已经部署了 CPU 来做 AI 推理的“玩家”用得如何。
有请两位重量级选手——京东云和英特尔。
今年,京东云推出了搭载第五代英特尔® 至强® 可扩展处理器的新一代服务器。
首先来看这款新服务器搭载的 CPU。
若是用一句话来形容这个最新一代的英特尔® 至强® 可扩展处理器,或许就是AI 味道越发得浓厚——
与使用相同内置 AI 加速技术(AMX,高级矩阵扩展)的前一代,也就是第四代至强® 可扩展处理器相比,它深度学习实时推理性能提升高达 42%;与内置上一代 AI 加速技术(DL-Boost,深度学习加速)、隔辈儿的第三代至强® 可扩展处理器相比,AI 推理性能更是最高提升至 14 倍。
到这里,我们就要详细说说英特尔® 至强® 内置 AI 加速器经历的两个阶段了:
第一阶段,针对矢量运算优化。
从 2017 年第一代至强® 可扩展处理器引入高级矢量扩展 512(英特尔® AVX-512)指令集开始,让矢量运算利用单条 CPU 指令就能执行多个数据运算。
再到第二代和第三代的矢量神经网络指令 (VNNI,是 DL-Boost 的核心),进一步把乘积累加运算的三条单独指令合并,进一步提升计算资源的利用率,同时更好地利用高速缓存,避免了潜在的带宽瓶颈。

第二阶段,也就是现阶段,针对矩阵运算优化。
所以从第四代至强® 可扩展处理器开始,内置 AI 加速技术的主角换成了英特尔® 高级矩阵扩展(英特尔® AMX)。它特别针对深度学习模型最常见的矩阵乘法运算优化,支持 BF16(训练/推理)和 INT8(推理)等常见数据类型。
英特尔® AMX 主要由两个组件组成:专用的 Tile 寄存器存储大量数据,配合 TMUL 加速引擎执行矩阵乘法运算。有人把它比作内置在 CPU 里的 Tensor Core,嗯,确实很形象。
这么一搞,它不仅做到在单个操作中计算更大的矩阵,还保证了可扩展性和可伸缩性。
英特尔® AMX 在至强® CPU 每个内核上并靠近系统内存,这样一来可减少数据传输延迟、提高数据传输带宽,实际使用上的复杂性也降低了。
例如现在若是将不超过 200 亿参数的模型“投喂”给第五代至强® 可扩展处理器,那么时延将低到不超过 100 毫秒!

其次再看新一代京东云服务器。
据介绍,京东与英特尔联合定制优化的第五代英特尔® 至强® 可扩展处理器的 Llama2-13B 推理性能(Token 生成速度)提升了 51%,足以满足问答、客服和文档总结等多种 AI 场景的需求。
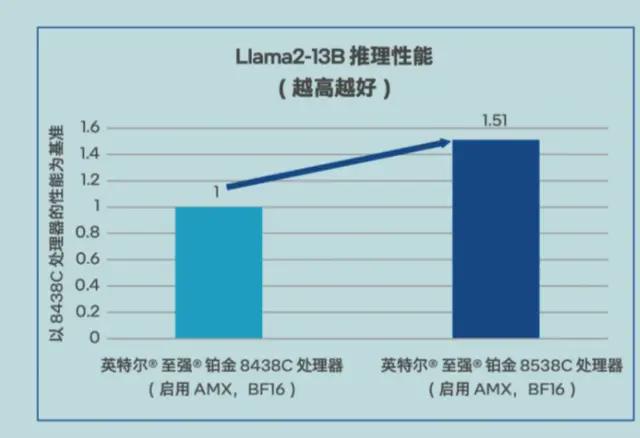
△Llama2-13B 推理性能测试数据
对于更高参数模型,甚至是 70B Llama2, 第五代英特尔® 至强® 可扩展处理器仍可胜任。
由此可见,CPU 内置 AI 加速器发展到现在,用于推理已能保证在性能上足够应对实战需求了。
像这样建立在通用服务器基础上的 AI 加速方案,除了可用于模型推理之外,还能灵活满足数据分析、机器学习等应用的需求,夸张点说,一个服务器就能完成 AI 应用的平台化和全流程支持。
不仅如此,用 CPU 做 AI 推理,也存在 CPU 与生俱来的优势,例如成本,还有更为重要的——部署和实践的效率。
因为它本身就是计算机的标准组件,几乎所有的服务器和计算机都配备了 CPU,传统业务中也已然存在大量的基于 CPU 的现成应用。
这意味着选择 CPU 进行推理,既容易获取,也不需要导入异构硬件平台的设计或具备相关的人才储备,还更容易获得技术支持和维护。
以医疗行业为例,过去 CPU 已广泛用于电子病历系统、医院资源规划系统等,培养出成熟的技术团队,也建立了完善的采购流程。
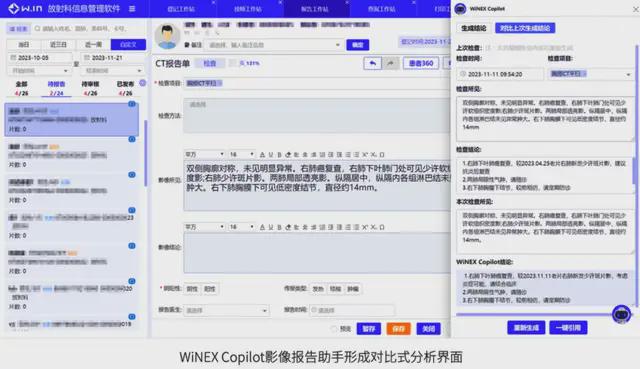
以此为基础,医疗信息化龙头企业卫宁健康,就利用 CPU 构建了能够高效、低成本部署和应用的 WiNEX Copilot 落地方案,这个方案已深度集成到卫宁新一代的 WiNEX 产品中,任何一家已采用该系统的医院,都能迅速上岗这种“医生 AI 助手”。
仅其一项病历文书助手功能,就可以在 8 小时内,也就是在医生下班后的时间里处理近 6000 份病历,相当于三甲医院 12 位医生一天工作量的总和!
而且也正如我们刚才所提到的,从 Hugging Face 所提供的优化教程来看,只需要简单的几步,就可以让 CPU 快速部署用于高效推理。
优化简单、上手快,便是 CPU 真正在 AI 应用落地过程中的又双叒一个优势了。
这意味着任何或大或小的场景中,只要基于 CPU 的优化实现了一个单点的成功突破,那么它很快就可以实现精准且快速的复制或扩展,结果就是:能让更多用户能在相同或相近的场景中,以更快的速度、更优的成本把 AI 应用落到实地。
毕竟英特尔不仅是一家硬件公司,同时也拥有着庞大的软件团队。在传统深度学习时代就积累了大量优化方法和工具,如 OpenVINO™ 工具包就在工业、零售等行业广泛应用。
到了大模型时代,英特尔也深入与主流大模型如 Llama 2、Baichuan、Qwen 等深度合作,以英特尔® Extension for Transformer 工具包为例,它就能让大模型推理性能加速达 40 倍。
加之现在大模型所呈现的明显趋势就是越发地开始卷应用,如何能让层出不穷的新应用“快好省”地落下去、用起来成了关键中的关键。
因此,为什么越来越多的人会选择 CPU 做 AI 推理,也就不难理解了。
或许,我们还可以再引用一下英特尔 CEO 帕特·基辛格 2023 年底接受媒体访问时所说的话,来巩固一下各位的印象:
“从经济学的角度看推理应用的话,我不会打造一个需要花费四万美元的全是 H100 的后台环境,因为它耗电太多,并且需要构建新的管理和安全模型,以及新的 IT 基础设施。”
“如果我能在标准版的英特尔芯片上运行这些模型,就不会出现这些问题。”
AI Everywhere
回看 2023 年,大模型本身是 AI 圈绝对的话题中心。
但 2024 年刚开始,明显能感觉到的趋势就是各类技术进展,各行业应用落地进展都在加快,呈现一种“多点开花”的局面。
在这种局面下,可以预见的是还将有更多 AI 推理需求涌现,推理算力在整个 AI 算力需求中所占的比例只会增加。
比如以 Sora 为代表的 AI 视频生成,业内推测其训练算力需求其实比大模型少,但推理算力需求却是大模型的成百上千倍。
而 AI 视频应用落地需要的视频传输等其他加速优化,也是 CPU 的拿手好戏。
所以综合来看,CPU 在整个英特尔 AI Everywhere 愿景下的定位也就明确了:
补足 GPU 或专用加速器覆盖不到或不足的地方,为更多样和复杂的场景提供灵活的算力选择,在强化通用计算的同时,成为 AI 普及的重要基础设施。

最后让我们打个小广告:为了科普 CPU 在 AI 推理新时代的玩法,量子位开设了《最“in”AI》专栏,将从技术科普、行业案例、实战优化等多个角度全面解读。
我们希望通过这个专栏,让更多的人了解 CPU 在 AI 推理加速,甚至是整个 AI 平台或全流程加速上的实践成果,重点就是如何更好地利用 CPU 来提升大模型应用的性能和效率。
这次我们以 CPU 内置的 AI 加速引擎为核心,介绍了 CPU 在 AI 推理中的应用价值与潜力。
而上一期,我们介绍了除直接加速 AI 推理之外,CPU 身上还有哪些特性与能力,能让它成为 AI 应用落地或推理时代不可或缺的力量。
参考链接:
[1]https://huggingface.co/docs/transformers/v4.34.0/en/perf_infer_cpu
[2]https://huggingface.co/docs/transformers/en/perf_infer_cpu
[3]https://mp.weixin.qq.com/s/85FopWzLOVi5a8x5AocYlw
[4]https://developer.aliyun.com/article/1424070?spm=5176.26934562.main.2.4a33333aPN4UBS











