
新智元报道
编辑:alan
近日,来自谷歌的研究人员发布了多模态扩散模型 VLOGGER,只需一张照片,和一段音频,就能直接生成人物说话的视频!
只需一张照片,和一段音频,就能直接生成人物说话的视频!
近日,来自谷歌的研究人员发布了多模态扩散模型 VLOGGER,让我们朝着虚拟数字人又迈进了一步。

论文地址:https://enriccorona.github.io/vlogger/paper.pdf
VLOGGER 接收单个输入图像,使用文本或者音频驱动,生成人类说话的视频,包括口型、表情、肢体动作等都非常自然。


可以看出整个生成的效果是非常优雅自然的。
VLOGGER 建立在最近生成扩散模型的成功之上,包括一个将人类转成 3D 运动的模型,以及一个基于扩散的新架构,用于通过时间和空间控制,增强文本生成图像的效果。

VLOGGER 可以生成可变长度的高质量视频,并且这些视频可以通过人脸和身体的高级表示轻松控制。

比如我们可以让生成视频中的人闭上嘴:

或者闭上双眼:

与之前的同类模型相比,VLOGGER 不需要针对个体进行训练,不依赖于面部检测和裁剪,而且包含了肢体动作、躯干和背景,——构成了可以交流的正常的人类表现。
AI 的声音、AI 的表情、AI 的动作、AI 的场景,人类开始的价值是提供数据,再往后可能就没什么价值了?


在数据方面,研究人员收集了一个新的、多样化的数据集 MENTOR,比之前的同类数据集大了整整一个数量级,其中训练集包括 2200 小时、800000 个不同个体,测试集为 120 小时、4000 个不同身份的人。

研究人员在三个不同的基准上评估了 VLOGGER,表明模型在图像质量、身份保存和时间一致性方面达到了目前的最优。

VLOGGER
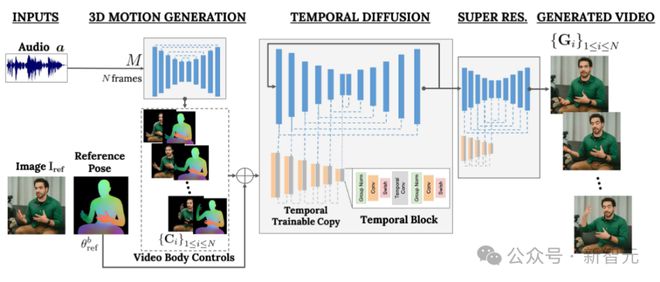
VLOGGER 的目标是生成一个可变长度的逼真视频,来描绘目标人说话的整个过程,包括头部动作和手势。

如上图所示,给定第 1 列所示的单个输入图像和一个示例音频输入,右列中展示了一系列合成图像。
包括生成头部运动、凝视、眨眼、嘴唇运动,还有以前模型做不到的一点,生成上半身和手势,这是音频驱动合成的一大进步。
VLOGGER 采用了基于随机扩散模型的两阶段管道,用于模拟从语音到视频的一对多映射。
第一个网络将音频波形作为输入,以生成身体运动控制,负责目标视频长度上的凝视、面部表情和姿势。
第二个网络是一个包含时间的图像到图像的平移模型,它扩展了大型图像扩散模型,采用预测的身体控制来生成相应的帧。为了使这个过程符合特定身份,网络获取了目标人的参考图像。
VLOGGER 使用基于统计的 3D 身体模型,来调节视频生成过程。给定输入图像,预测的形状参数对目标标识的几何属性进行编码。
首先,网络M获取输入语音,并生成一系列N帧的 3D 面部表情和身体姿势。
然后渲染移动 3D 身体的密集表示,以在视频生成阶段充当 2D 控件。这些图像与输入图像一起作为时间扩散模型和超分辨率模块的输入。
音频驱动的运动生成
管道的第一个网络旨在根据输入语音预测运动。此外还通过文本转语音模型将输入文本转换为波形,并将生成的音频表示为标准梅尔频谱图(Mel-Spectrograms)。
管道基于 Transformer 架构,在时间维度上有四个多头注意力层。包括帧数和扩散步长的位置编码,以及用于输入音频和扩散步骤的嵌入 MLP。
在每一帧中,使用因果掩码使模型只关注前一帧。模型使用可变长度的视频进行训练(比如 TalkingHead-1KH 数据集),以生成非常长的序列。
研究人员采用基于统计的 3D 人体模型的估计参数,来为合成视频生成中间控制表示。
模型同时考虑了面部表情和身体运动,以生成更好的表现力和动态的手势。
此外,以前的面部生成工作通常依赖于扭曲(warped)的图像,但在基于扩散的架构中,这个方法被忽视了。
作者建议使用扭曲的图像来指导生成过程,这促进了网络的任务并有助于保持人物的主体身份。
生成会说话和移动的人类
下一个目标是对一个人的输入图像进行动作处理,使其遵循先前预测的身体和面部运动。
受 ControlNet 的启发,研究人员冻结了初始训练的模型,并采用输入时间控件,制作了编码层的零初始化可训练副本。
作者在时间域中交错一维卷积层,网络通过获取连续的N帧和控件进行训练,并根据输入控件生成参考人物的动作视频。
模型使用作者构建的 MENTOR 数据集进行训练,因为在训练过程中,网络会获取一系列连续的帧和任意的参考图像,因此理论上可以将任何视频帧指定为参考。
不过在实践中,作者选择采样离目标剪辑更远的参考,因为较近的示例提供的泛化潜力较小。
网络分两个阶段进行训练,首先在单帧上学习新的控制层,然后通过添加时间分量对视频进行训练。这样就可以在第一阶段使用大批量,并更快地学习头部重演任务。
作者采用的 learning rate 为 5e-5,两个阶段都以 400k 的步长和 128 的批量大小训练图像模型。
多样性
下图展示了从一个输入图片生成目标视频的多样化分布。最右边一列显示了从 80 个生成的视频中获得的像素多样性。

在背景保持固定的情况下,人的头部和身体显著移动(红色意味着像素颜色的多样性更高),并且,尽管存在多样性,但所有视频看起来都很逼真。
视频编辑

模型的应用之一是编辑现有视频。在这种情况下,VLOGGER 会拍摄视频,并通过闭上嘴巴或眼睛等方式改变拍摄对象的表情。
在实践中,作者利用扩散模型的灵活性,对应该更改的图像部分进行修复,使视频编辑与原始未更改的像素保持一致。
视频翻译
模型的主要应用之一是视频翻译。在这种情况下,VLOGGER 会以特定语言拍摄现有视频,并编辑嘴唇和面部区域以与新音频(例如西班牙语)保持一致。
参考资料:











