
新智元报道
编辑:编辑部
过去 25 年,半导体工艺制程不断逼近极限,才有了 ChatGPT 的诞生。如今世界最强英伟达 GPU 已有超 2080 亿个晶体管。台积电大佬预测,未来十年,1 万亿晶体管 GPU 将问世。
GTC 2024 大会上,老黄祭出世界最强 GPU——Blackwell B200 ,整整封装了超 2080 亿个晶体管。
比起上一代 H100(800 亿),B200 晶体管数是其 2 倍多,而且训 AI 性能直接飙升 5 倍,运行速度提升 30 倍。

若是,将千亿级别晶体管数扩展到 1 万亿,对 AI 界意味着什么?
今天,IEEE 的头版刊登了台积电董事长和首席科学家撰写的文章——「我们如何实现 1 万亿个晶体管 GPU」?

这篇千字长文,主打就是为了让 AI 界人们意识到,半导体技术的突破给 AI 技术带来的贡献。
从 1997 年战胜国际象棋人类冠军的「深蓝」,到 2023 年爆火的 ChatGPT,25 年来 AI 已经从实验室中的研究项目,被塞入每个人的手机。
这一切都要归功于,3 个层面的重大突破:ML 算法创新、海量数据,以及半导体工艺的进步。
台积电预测,在未来 10 年,GPU 集成的晶体管数将达到 1 万亿!
与此同时,未来 15 年,每瓦 GPU 性能将提高 1000 倍。

半导体工艺不断演变,才诞生了 ChatGPT
从软件和算法到架构、电路设计乃至器件技术,每一层系统都极大地提升了 AI 的性能。
但是基础的晶体管器件技术的不断提升,才让这一切成为可能:
IBM 训练「深蓝」使用的芯片工艺是 0.6 微米和 0.35 微米。

Ilya 团队训练赢得 ImageNet 大赛的深度神经网络采用的 40 纳米工艺。

2016 年,DeepMind 训出的 AlphaGo 战胜了李世石,使用了 28 纳米工艺。

而训练 ChatGPT 的芯片基于的是 5 纳米工艺,而最新版的 ChatGPT 推理服务器的芯片工艺已经达到了 4 纳米。
可以看出,从 1997 年到现在,半导体工艺节点取得的进步,推动了如今 AI 飞跃式的发展。
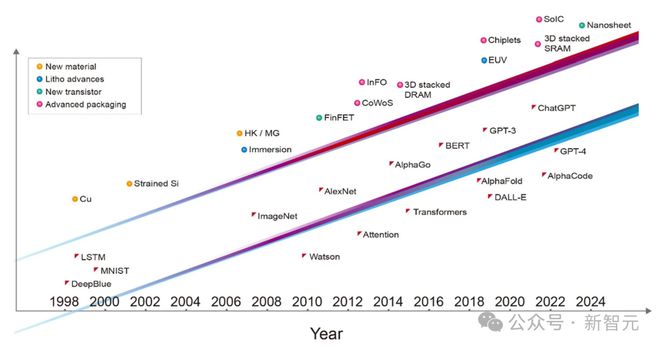
如果 AI 革命想要继续保持当前的发展速度,那么它更需要半导体行业的创新和支持。
如果仔细研究 AI 对于算力的要求会发现,最近 5 年,AI 训练所需的计算和内存访问量增长了好几个数量级。
以 GPT-3 为例,它的训练需要的计算量相当于每秒进行超过 5 千万亿亿次的运算,持续整整一天(相当于 5000 千兆浮点运算天数),同时需要 3TB(3 万亿字节)的内存容量。
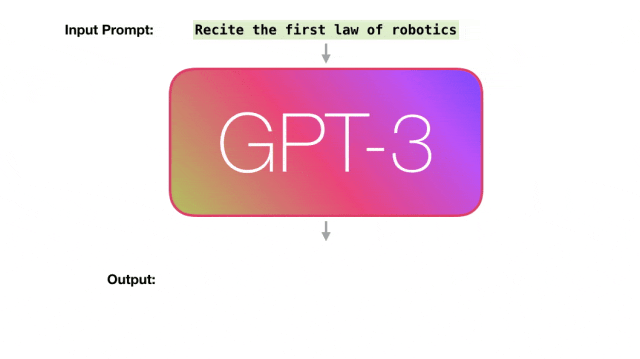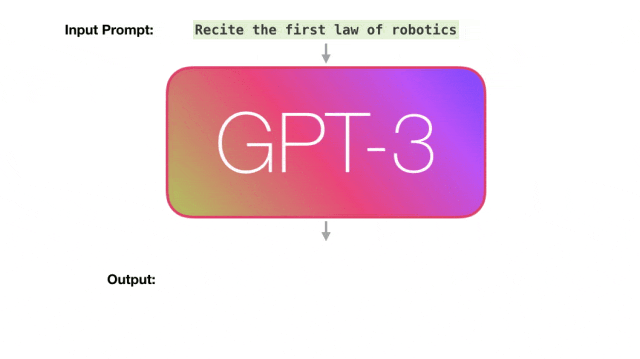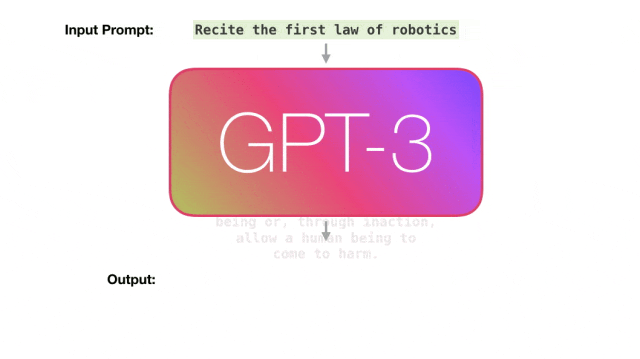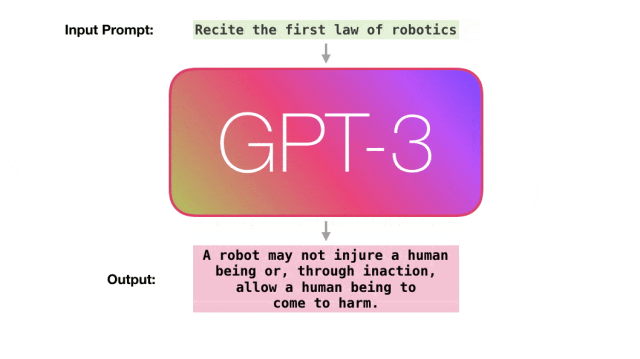
随着新一代生成式 AI 应用的出现,对计算能力和内存访问的需求仍在迅速增加。
这就带来了一个迫在眉睫的问题:半导体技术如何才能跟上这种发展的速度?

从集成芯片到集成芯片组
自从集成电路诞生以来,半导体行业一直在想办法把芯片造得更小,这样才能在一个指甲盖大小的芯片中集成更多的晶体管。
如今,晶体管的集成工艺和封装的技术已经迈向更高层次——行业已经从 2D 空间的缩放,向 3D 系统集成迈进。
芯片行业正在将多个芯片整合到一个集成度更高、高度互连的系统中,这标志着半导体集成技术的巨大飞跃。
AI 的时代,芯片制造的一个瓶颈在于,光刻芯片制造工具只能制造面积不超过大约 800 平方毫米的芯片,这就是所谓的光刻极限。
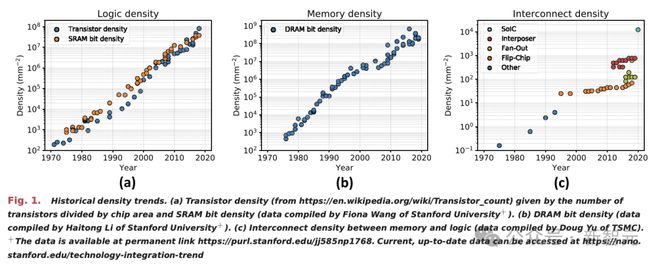
但现在,台积电可以通过将多个芯片连接在一块内嵌互连线路的硅片上来突破这一极限,实现在单一芯片上无法达到的大规模集成。

举个栗子,台积电的 CoWoS 技术能够将多达 6 个光刻极限范围内的芯片,以及十二个高带宽内存(HBM)芯片封装在一起。
高带宽内存(HBM)是 AI 领域越来越依赖的一项关键半导体技术,它通过将芯片垂直堆叠的方式来集成系统,这一技术在台积电被称为系统集成芯片(SoIC)。
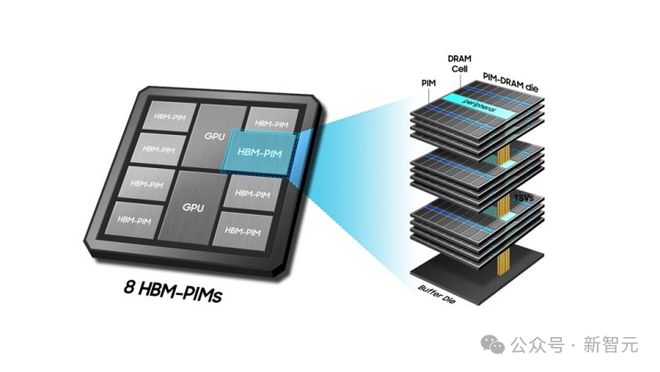
HBM 由多层 DRAM 芯片垂直堆叠而成,他们都位于一个控制逻辑 IC 之上。它利用硅穿孔(TSV)这种垂直连接方式让信号穿过每层芯片,并通过焊球来连接各个内存芯片。
目前,最先进的 GPU 都非常依赖 HBM 技术。
未来,3D SoIC 技术将提供一种新的解决方案,与现有的 HBM 技术相比,它能在堆叠芯片之间实现更密集的垂直连接。
通过最新的混合键合技术,可以将 12 层芯片堆叠起来,从而开发出全新的 HBM 结构,这种铜对铜(copper-to-copper)的连接方式比传统的焊球连接更为紧密。

论文地址:https://ieeexplore.ieee.org/document/9265044
这种内存系统在一个更大的基础逻辑芯片上以低温键合,整体厚度仅为 600 微米。
随着由众多芯片组成的高性能计算系统运行大型 AI 模型,高速有线通信可能成为计算速度的下一个瓶颈。
目前,数据中心已经开始使用光互连技术连接服务器架。

文章地址:https://spectrum.ieee.org/optical-interconnects
不久的将来,台积电将需要基于硅光子技术的光接口,把 GPU 和 CPU 封装到一起。

论文地址:https://ieeexplore.ieee.org/document/10195595
这样才能实现 GPU 之间的光通信,提高带宽的能源和面积效率,从而让数百台服务器能够像一个拥有统一内存的巨型 GPU 那样的方式高效运行。
所以,由于 AI 应用的推动,硅光子技术将成为半导体行业中最为关键的技术之一。
迈向一万亿晶体管 GPU
当前用于 AI 训练的 GPU 芯片,约有 1000 亿的晶体管,已经达到了光刻机处理的极限。
若想继续增加晶体管数量,就需要采用多芯片,并通过 2.5D、3D 技术进行集成,来完成计算任务。
目前,已有的 CoWoS 或 SoIC 等先进封装技术,可以在 GPU 中集成更多晶体管。
台积电预计,在未来十年内,采用多芯片封装技术的单个 GPU,将拥有超 1 万亿晶体管。
与此同时,还需要将这些芯片通过 3D 堆叠技术连接起来。
但幸运的是,半导体行业已经能够大幅度缩小垂直连接的间距,从而增加了连接密度。
而且,未来在提高连接密度方面还有巨大的潜力。台积电认为,连接密度增长一个数量级,甚至更多是完全有可能的。
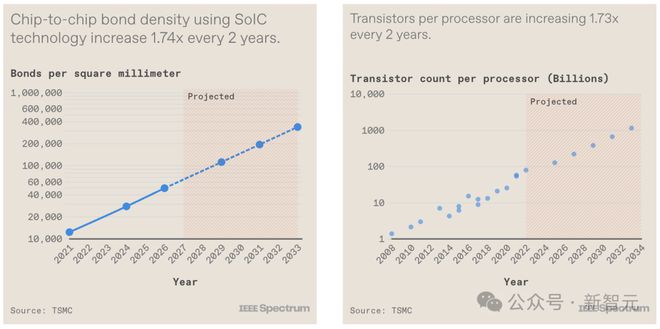
3D 芯片中的垂直连接密度的增长速度与 GPU 中的晶体管数量大致相同
GPU 的能效性能趋势
那么,这些领先的硬件技术,是如何提升系统整体性能的呢?
通过观察服务器 GPU 的发展,可以明显看到一个趋势:所谓的能效性能(EEP)——一个反映系统能效和运行速度的综合指标——正稳步提升。
过去 15 年中,半导体行业已经实现了,每两年将 EEP 提高约 3 倍的壮举。
而在台积电看来,这种增长趋势将会延续,将会得益于众多方面的创新,包括新型材料的应用、设备与集成技术的进步、EUV 技术的突破、电路设计的优化、系统架构的革新,以及对所有这些技术要素进行的综合优化等因素的共同推动。
此外,系统技术协同优化(STCO)这一概念将变得日益重要。
在 STCO 中,GPU 内不同的功能模块将被分配到专属的小芯片(chiplets)上,每个模块都采用最适合其性能和成本效益的技术进行打造。
这种针对每个部件的最优化选择,将对提高整体性能和降低成本发挥关键作用。
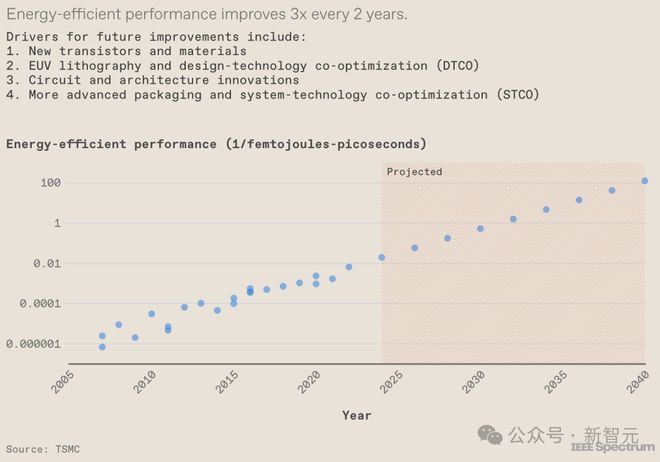
得益于半导体技术的进步,EEP 指标有望每两年提升 3 倍
3D 集成电路的革命性时刻
1978 年,加州理工学院的 Carver Mead 教授和 Xerox PARC 的 Lynn Conway,共同开发了一种革命性的计算机辅助设计方法。
他们制定了一系列设计规则,简化了芯片设计的过程,让工程师即使不深谙过程技术,也能轻松设计出复杂的大规模集成电路。

论文地址:https://ai.eecs.umich.edu/people/conway/VLSI/VLSIText/PP-V2/V2.pdf
而在 3D 芯片设计领域,也面临着类似的需求。
- 设计师不仅要精通芯片和系统架构设计,还需要掌握硬件与软件优化的知识。
- 而制造商则需要深入了解芯片技术、3D 集成电路技术和先进封装技术。
就像 1978 年那样,我们需要一种共通语言,让电子设计工具能够理解这些技术。
如今,一种全新的硬件描述语言——3Dblox,已经得到了当下多数技术和电子设计自动化公司的支持。

它赋予了设计师自由设计 3D 集成电路系统的能力,且无需担心底层技术的限制。
走出隧道,迎接未来
在人工智能的大潮中,半导体技术成为了推动 AI 和应用发展的关键力量。
新一代 GPU 已经打破了传统的尺寸和形状限制。半导体技术的发展,也不再局限于仅在二维平面上缩小晶体管。
一个 AI 系统可以集成尽可能多的节能晶体管,拥有针对特定计算任务优化的高效系统架构,以及软硬件之间的优化关系。

过去 50 年,半导体技术的进步就像是在一条明确的隧道中前进,每个人都清楚下一步应该怎么做:不断缩小晶体管的尺寸。
现在,我们已经走到了这条隧道的尽头。
未来的半导体技术开发将面临更多挑战,但同时,隧道外也有着更加广阔的可能性。
而我们将不再被过去的限制所束缚。











