3 月 28 日消息,美国当地时间周三,企业软件公司 Databricks 宣布推出了新的开源人工智能模型 DBRX,声称这一模型在开源人工智能领域的效率和性能上树立了新的行业标准。
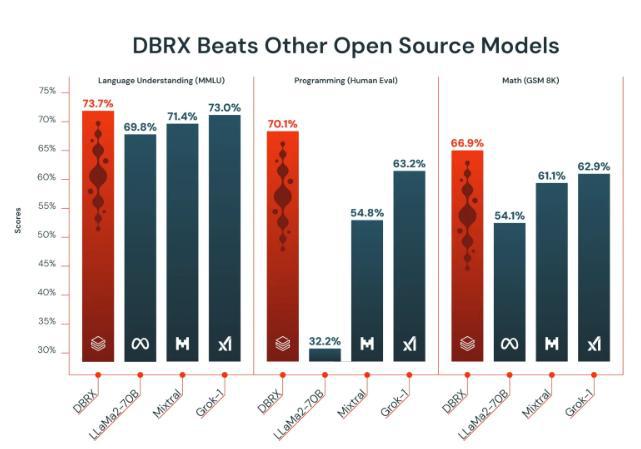
Databricks 宣称,DBRX 模型拥有 1320 亿个参数,在语言理解、编程和数学技能等关键领域的基准测试中,其性能超过了其他领先的开源人工智能模型,包括 Meta 的 Llama 2-70B 和法国初创企业 Mixtral AI 的模型。
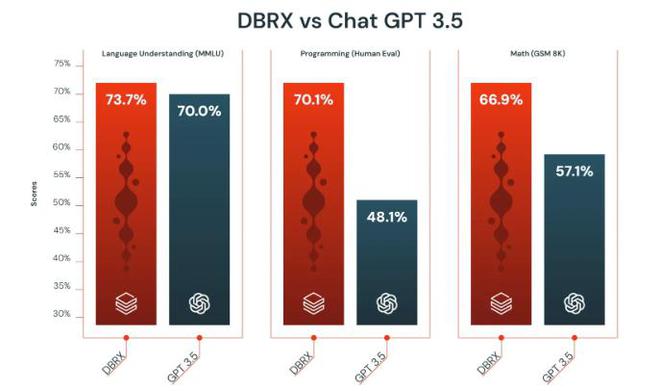
虽然 DBRX 在某些原始功能上还无法与 OpenAI 的 GPT-4 相比,但 Databricks 高管表示,DBRX 无疑是一个功能远超 GPT-3.5 的替代产品,并且成本只是 GPT-3.5 的一小部分。
Databricks 的首席执行官阿里·戈德西(Ali Ghodsi)在新闻发布会上表示:“我们非常高兴能向全世界展示 DBRX,并带动整个行业向更强大、更高效的开源人工智能方向前进。虽然 GPT-4 这类基础模型无疑是极其优秀的通用工具,但 Databricks 专注于为客户量身打造模型,这些模型能深入解析他们的专有数据。DBRX 的发布正体现了我们实现该目标的决心。”
创新的“专家混合”架构
Databricks 的研究团队揭示了 DBRX 模型的关键创新之处——“专家混合”架构。这一架构使 DBRX 与其他竞争模型显著不同,后者往往利用所有参数生成每个单词。相较而言,DBRX 巧妙地整合了 16 个专家子模型,并在实时处理中为每个 token 准确挑选最相关的四个子模型。
这种设计的巧妙之处在于,它使 DBRX 在任何时刻只需激活 360 亿个参数,因而实现了更高的性能输出。这不仅显著提高了模型的处理速度,还大幅降低了运行成本,使其更为高效和经济。
这一创新策略是基于 Mosaic 团队在早期 Mega-MoE 项目上的进一步研究而开发的。Mosaic 团队是去年被 Databricks 收购的一个研究部门。
戈德西高度评价了 Mosaic 团队的贡献,他表示:“多年来,Mosaic 团队在更高效训练基础人工智能模型方面取得了显著进步。正是他们的努力让我们能够迅速开发出如 DBRX 这般卓越的人工智能模型。实际上,开发 DBRX 只用了约两个月时间,成本大概在 1000 万美元左右。”
推进 Databricks 的企业 AI 战略
通过将 DBRX 开源,Databricks 的目标不仅是在前沿人工智能研究领域确立其领导者地位,而且还希望促进其创新架构在整个行业中的更广泛采用。此外,DBRX 也致力于支持 Databricks 的核心业务——为客户定制和托管基于其专有数据集的人工智能模型。
在如今的市场环境中,很多 Databricks 的客户都依赖于 OpenAI 及其他供应商提供的 GPT-3.5 等模型来支撑其业务运作。然而,将敏感的企业数据托管给第三方,常常会激起关于安全性和合规性的一系列担忧。
针对这一点,戈德西表示:“我们的客户相信,Databricks 能够妥善处理跨国界数据监管的问题。他们已在 Databricks 平台上存储并管理了庞大数据量。现在,有了 DBRX 以及 Mosaic 的定制模型功能,客户们能够在保障数据安全的同时,充分利用先进人工智能技术带来的诸多益处。”
在日益激烈的竞争中占据一席之地
随着 DBRX 的推出,Databricks 在核心数据和人工智能平台业务领域面临着激烈的竞争。竞争对手诸如数据仓库巨头 Snowflake 已通过推出自有的人工智能服务 Cortex,复制了 Databricks 的部分功能。同时,亚马逊、微软和谷歌等领先的云计算服务供应商也正纷纷在其技术堆栈中集成生成式人工智能功能。
Databricks 借助其开创性的开源项目 DBRX,自诩具备最前沿的人工智能研究能力,旨在确立自身作为该领域领导者的地位,并吸引顶尖的数据科学人才。这一策略也反映了人们对大型科技公司将人工智能模型商业化的越来越多的抵制,许多人批评这些商业模型像“黑盒子”,缺乏透明度和可解释性。
DBRX 面临的真正挑战在于市场的接受程度以及它为 Databricks 客户所创造的具体价值。在企业越来越多寻求利用人工智能推动业务增长和创新的同时,还要保持对自有数据的控制,Databricks 赌注于其尖端研究与企业级平台的完美融合能够让它在竞争中脱颖而出。
Databricks 已经向大型科技公司及开源社区的竞争对手抛出了挑战,要求他们在创新上与其一较高下。人工智能领域的竞争日趋激烈,而 Databricks 已明确宣布其志在成为这场竞争的关键力量。(小小)











