
衡宇发自阿拉上海
量子位公众号 QbitAI
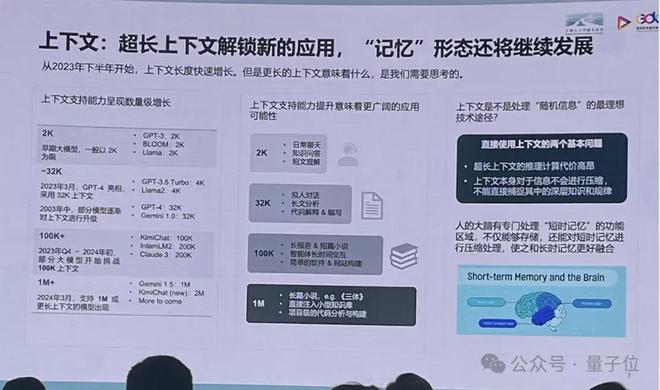
“据我了解,国内多个一线大模型机构,都已经突破了兆级的长文本能力。”
以上,是“2024 全球开发者先锋大会”大模型前沿论坛会间隙,上海人工智能实验室领军科学家林达华与量子位的交谈剪影。
林达华,深度学习与计算机专家,香港中文大学教授,他是商汤联合创始人,也是商汤创始人汤晓鸥的学生,是国际上最具影响力的视觉算法开源项目 OpenMMLab 的主导发起人。在大模型时代,他带领了书生·浦语 InternLM 开源大模型体系以及 OpenCompass 司南大模型评测体系的研发工作。
林达华预估,第一季度左右,各家都会对大模型上下文窗口兆级能力“亮剑”。

同时,他表达了与月之暗面同样的态度,即大海捞针其实没有那么难。
难的是海里不止一根针,应有无数的碎片化信息藏在各个地方,(大模型)把所有东西串接一起,做比较深层次的结论。
就像读福尔摩斯侦探小说,读完后综合判断凶手是谁——这就不是一个简单的检索问题。
近期,各家大模型于长文本赛道上卷生卷死,但是否应把它作为最主要的方向去打磨,大家有不同的判断。
林达华点出,应该要评估衡量超长文本能力的计算代价,“无损长上下文窗口,每一次响应都是很昂贵的过程,对应用来说,这个性价比是不是最理想的?我觉得值得探讨。”
长文本相关问题只是林达华表达自己思考和见解的一小个片段。
在这场大模型前沿论坛上,他以业界躬身入局者的身份,回望过去“群模乱舞”的一年,总结出大模型赛道的四点现状:
OpenAI 引领技术潮流,Google 紧紧追赶,Claude 异军突起; 上下文、推理能力、更高效的模型架构是技术探索的重点方向; 轻量级模型崭露头角; 开源模型快速发展,开放生态已成气候。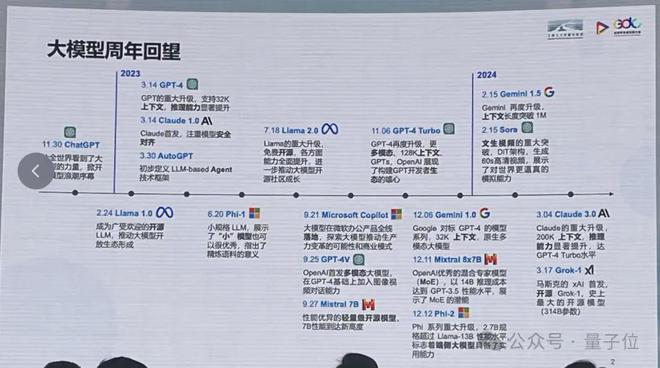
林达华还表示,大模型时代,技术演进有两股主要的驱动力量:
一是对 AGI 的追求,对 Scaling Law 的信仰;
二是对大模型带来新一次产业变革的憧憬。
除此之外,更详细的回望和前瞻性观点,在林达华口中一一道来。

模型架构:从追求参数到追求更高效的 Scale
Transformer 架构对计算资源的消耗巨大。
前几日的黄仁勋与 Transformer 七子路边对话中,Transformer 作者 Aidan Gomez 语气坚定,“世界需要比 Transformer 更好的东西(the world needs something better than Transformers)”。
业界已经开始从追求参数,过渡转换为追求更高效的规模。
其中,MoE 值得关注,业界同时在探索 Mamba 模型等,以低复杂度的注意力架构更高效地处理上下文。

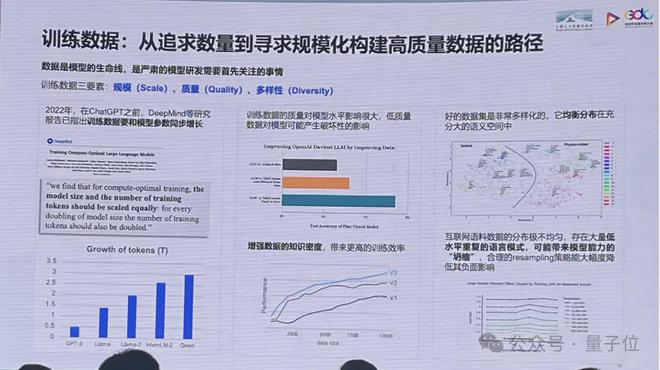
训练数据:从追求数量到寻求规模化构造高质量数据的路径
训练数据包括三要素:
规模、质量、多样性。
在规模方面,早在 ChatGPT 之前,DeepMind 等研究报告已指出训练数据要和模型参数同步增长。
而训练数据的质量对模型水平影响很大,低质量数据对模型可能产生破坏性影响。增强数据的知识密度,能带来更高的训练效率。
此外,好的数据集是非常多样化的,均衡分布在充分大的语义空间中。
互联网语料数据的分布极不均匀,存在大量低水平重复的语言模式,可能带来模型能力的塌缩,“10% 的带有重复模式的数据注入到训练集里,有可能会使得模型降级到原来1/2 的体量。”
合理的 resampling(重采样)策略能大幅度降低其负面影响。因此,业界也在从追求训练数据数量,过渡向到寻求规模化构建高质量数据。
多模态:多模态融合将成为重要趋势,技术探索仍在路上
多模态融合将成为重要技术趋势,但技术探索仍在路上。
相比语言,多模态模型的训练多了一个重要维度,即图像和视频的分辨率对多模态模型最终的性能表现有重要影响。
如果使用非常高的分辨率进行多模态的训练和推理,模型能够得到巨大提升,但高分辨率会带来高计算成本。
“如何在高分辨率和合理计算成本之间取得最佳平衡,这为架构研究带来了很大的创新空间。”

智能体:大模型应用的重要形态,但需要核心基础能力的支撑
要让大模型真正进入到应用的场景和生产的场景的时候,它需要跟系统、跟场景、跟里面所有的事情互动。因此,需要给大模型装上手脚,然后就能不断地发出指令做出反馈,这就是一个智能体,这就是场景应用价值的系统。
智能体并不是一个简单的流程化过程。
它需要建立在一个非常坚实的基础模型上,具有很强的指令跟随能力、理解能力、反思能力和执行能力。如果这些能力都不具备,其实串接在一起仍然不然获得你所理想中的那种智能体的能力。
这里面是实验室把智能体具像化,智能体不一定是机器人,它可以是各种软件系统。

计算环境:云侧还在指数式成长,端侧即将迎来黄金增长期
芯片进入到后摩尔定律时代,未来算力会变成体量的拓展,越来越多的芯片连接在一起,建成越来越大的计算中心,支撑对通用人工智能的追求。
最终瓶颈不再是芯片,而是能源。
现在,小规格的大语言模型已具备较强性能水平和实用可能性,优秀的模型越做越小,可以进入到手机直接运行。
林达华表示,随着端侧算力快速增长,端侧即将迎来黄金增长期,云端协同将成为未来重要趋势,由云侧计算建立天花板,端侧计算将支撑用户使用大规模放量。

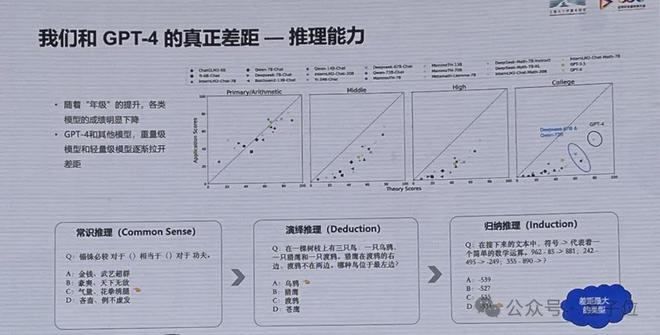
国内外差距:和 GPT-4 真正差距是推理能力
国内前列的模型在主客观表现上都超过了 GPT-3.5。
但同时需注意,国内大模型与 GPT-4 的真正差距在于推理能力。
林达华称,特别是随着推理难度的提升,GPT-4 和其他模型,重量级模型和轻量级模型逐渐拉开差距。相比常识推理、演绎推理,归纳推理是差距最大的类型。
One More Thing
在对谈中,林达华还表达了对国内大模型落地的看法。
观国内当下的最大的优势,是应用场景非常非常多。
如果有套生态,能够让大家用大模型去探索在哪些地方能用,哪些地方不能用,在应用上的探索速度和体量可能更快。
不过,他同时表示:
不能因为我们在应用落地上的繁花似锦,就掩盖我们去思考另一个问题——归于最终,还是要提升创新能力和原创水平。












