
新智元报道
编辑:Mindy
斯坦福的一篇案例研究表示,提交给 AI 会议的同行评审文本中,有 6.5% 到 16.9% 可能是由 LLM 大幅修改的,而这些趋势可能在个体级别上难以察觉。
LLM 在飞速进步的同时,人类也越来越难以区分 LLM 生成的文本与人工编写的内容,甚至分辨能力与随机器不相上下。
这加大了未经证实的生成文本可以伪装成权威、基于证据的写作的风险。
尽管在个例上难以察觉,但由于 LLM 的输出趋于一致性,这种趋势可能会放大语料库级别的偏见。
基于这一点,一支来自斯坦福的团队提出一种方法,以此来对包含不确定量的 AI 生成文本的真实世界数据集进行可比较的评估,并在 AI 会议的同行评审文本中验证。

论文地址:https://arxiv.org/abs/2403.07183
AI 会议的同行评审可能是 AI?
同行评审是一种学术论文发表前的质量评估机制。
这些同行评审者通常具有相关领域的专业知识,他们会对论文的原创性、方法学、数据分析、结果解释等进行评价,以确保论文的科学性和可信度。
斯坦福团队研究的 AI 会议包括 ICLR 2024、NeurIPS 2023、CoRL 2023 和 EMNLP 2023,他们的研究发生在 ChatGPT 发布之后,实验观察估计 LLM 可能会显著修改或生成的大语料库中的文本比例。
结果显示,有 6.5% 到 16.9% 可能是由 LLM 大幅修改的,即超出了拼写检查或微小写作更新的范围。
在下图中,可以看到 ICLR 2024 同行评审中,某些形容词的频率发生了显著变化,例如「值得称赞的」、「细致的」和「复杂的」,它们在出现在句子中的概率分别增加了 9.8 倍、34.7 倍和 11.2 倍。而这些词大概率是由人工智能生成的。
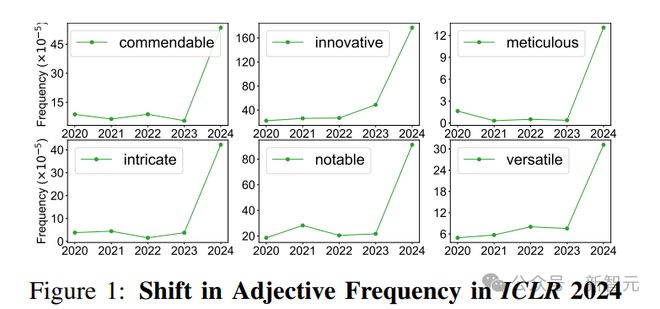
同时研究还发现,在报告较低自信度、接近截稿时间以及不太可能回应作者反驳的评论中,LLM 生成文本的估计比例较高。
最大似然让 LLM 现形
因为 LLM 检测器的性能不稳定,所以比起尝试对语料库中的每个文档进行分类并计算总数,研究人员采用了最大似然的方法。
研究方法主要分成四个步骤:
1. 收集(人类)作者的写作指导——在这个情况下是同行评审指导。将这些指导作为提示输入到一个 LLM 中,生成相应的 AI 生成文档的语料库。
2. 使用人类和 AI 文档语料库,估算参考标记使用分布P和Q。
3. 在已知正确比例的 AI 生成文档的合成目标语料库上验证方法的性能。
4. 基于对P和Q的这些估计,使用最大似然法估算目标语料库中 AI 生成或修改文档的比例α。
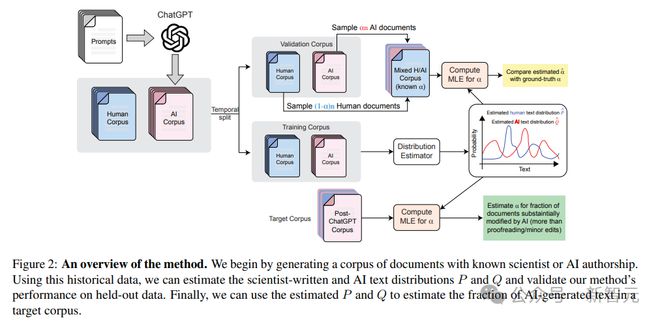
上图对方法进行了流程可视化。
研究人员首先生成一个具有已知科学家或 AI 作者身份的文档语料库。利用这些历史数据,我们可以估算科学家撰写的文本和 AI 文本的分布P和Q,并验证我们方法在留存数据上的性能。最后,使用估算的P和Q来估算目标语料库中 AI 生成文本的比例。
在验证集中,该方法在 LLM 生成反馈比例方面表现出高精度,预测误差不到 2.4%。同时,团队对鲁棒性也进行了验证。
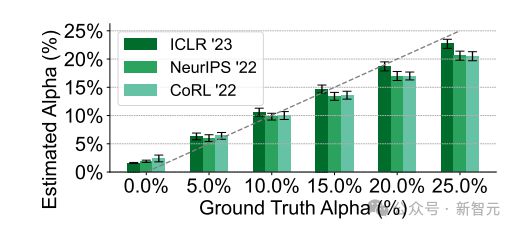
另外,一位审稿人可能会分两个不同阶段起草他们的审稿意见:首先,在阅读论文时创建审稿的简要大纲,然后使用 LLM 扩展这个大纲以形成详细、全面的审稿意见。
在这种场景的验证中,算法仍旧表现出色,能够检测到 LLM 用于大幅扩展由人提供的审稿大纲的情况。
实验结果中还发现了什么
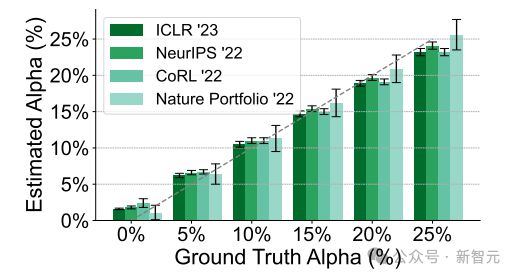
首先,团队将 AI 会议的同行评审和 Nature Portfolio 期刊的α进行了比较。
与 AI 会议相反,Nature Portfolio 期刊在 ChatGPT 发布后没有显示出估计α值的显著增加,ChatGPT 发布前后的α估计值仍在α = 0 验证实验的误差范围内。
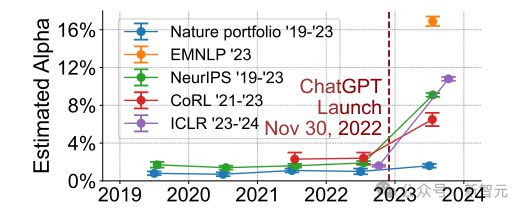
这种一致性表明,在与机器学习专业领域相比,广泛的科学学科对 AI 工具的反应有明显的不同。
除了发现同行评审文本中,有 6.5% 到 16.9% 来自于 LLM 的手笔之外,该研究还发现了一些有意思的用户行为,在四个 AI 会议里保持一致:
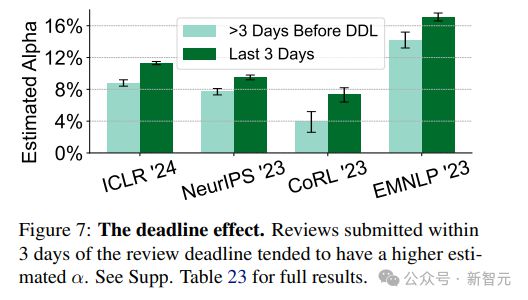
1. 截至日期效应:在审稿截止日期前 3 天内提交的评审往往更倾向于用 GPT
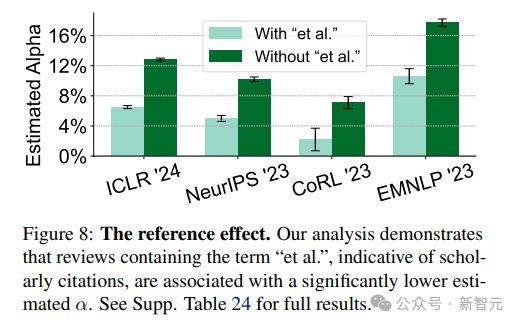
2. 参考文献效应:包含「et al.」一词的评审,即有学术引用的评审,更不会用 GPT
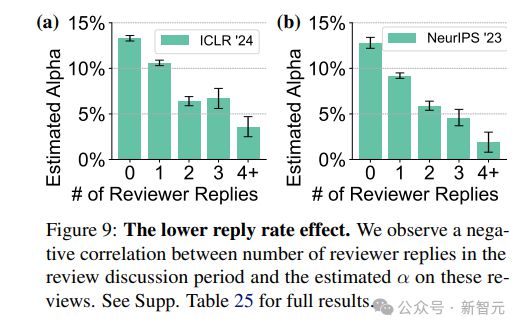
3. 回复率降低效应:审稿讨论期间,审稿人回复数量越多,评审更不会用 GPT
4. 同质化效应:与同论文其他审稿意见越相似的评审,越可能用 GPT
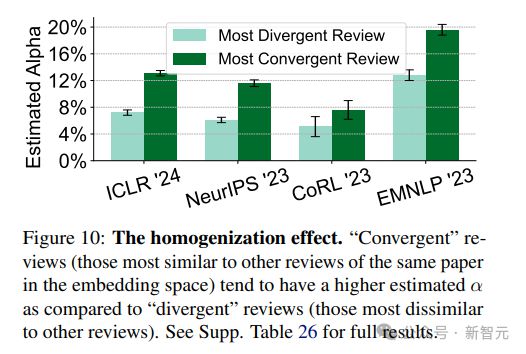
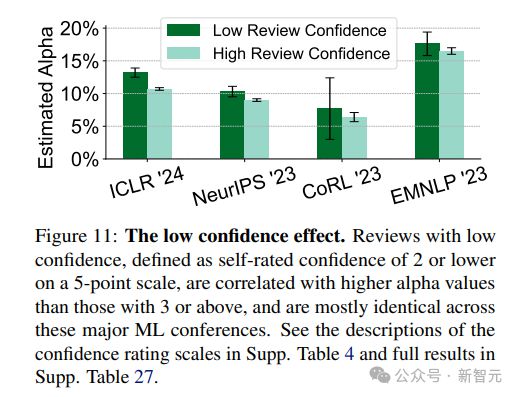
5. 低置信度效应:自评置信度在 5 分制度中为 2 分或以下的评审与较高置信度(3 分或以上)的评审相比,更可能用了 GPT
尽管这项研究存在一定的局限性,比如只涉及了四个会议、仅使用了 GPT-4 来生成 AI 文本,并且可能存在其他误差来源,比如由于主题和审稿人的变化而导致的模型时间分布的偏差。
但是,研究的结论启示了 LLM 可能对科学界产生的潜在影响,这有助于激发进一步的社会分析和思考。希望这些研究结果能够促进对于 LLM 在未来信息生态系统中应该如何使用以及可能带来的影响的深入探讨,从而推动出台更加明智的政策决策。
参考资料:











