
洪水是最常见的自然灾害类型,全球有近 15 亿人(约占世界人口的 19%)直接面临严重洪水事件的巨大风险。洪水还造成巨大的物质损失,每年造成全球经济损失约 500 亿美元。
近年来,人类造成的气候变化进一步增加了一些地区的洪水频率。然而,目前的预报方法主要依赖沿河而建的观测站,其在全球的分布并不均匀,这就导致未经测量的河流更难预报,其负面影响主要体现在发展中国家。升级预警系统,使这些人群能够获得准确、及时的信息,每年可以挽救数千人的生命。
那么,如何在全球范围内进行可靠的洪水预报?人工智能(AI)模型或许大有可为。
如今,来自 Google Research 洪水预测团队的 Grey Nearing 及其同事开发的人工智能模型,通过利用现有的 5680 个测量仪进行训练,可预测未测量流域在 7 天预测期内的日径流。
随后,他们将该人工智能模型与全球领先的短期和长期洪水预测软件——全球洪水预警系统(GloFAS)进行了对比测试。结果显示,该模型同日预测准确率与当前系统相当甚至更高。
此外,该模型在预测重现窗口(return window)期为五年的极端天气事件时,其准确性与 GloFAS 预测重现窗口期为一年的事件时的准确性相当或更高。
相关研究论文以“Global prediction of extreme floods in ungauged watersheds”为题,已发表在权威科学期刊 Nature 上。

研究团队表示,该模型能对未测流盆地的小规模和极端洪水事件做出预警,且预警期比之前的方法都更长,并可提高发展中地区获得可靠洪水预报的机会。
提前 7 天,AI 是如何做到的?
那么,这一人工智能模型如何能给出可靠的洪水预报呢?
据论文描述,该研究使用了一种叫做长短期记忆(LSTM)网络的人工智能模型来进行河流流量的预测。这个模型的设计有点像我们的大脑,它可以从一系列的气象数据中学习并预测未来的河流流量,分为编码器和解码器两部分。
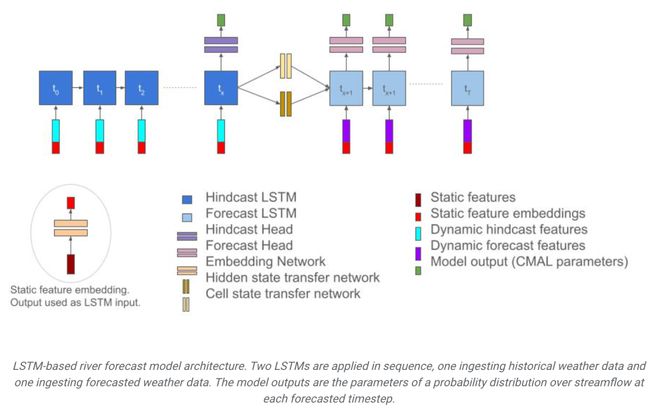
图|基于 LSTM 的河流预报模型架构。两个 LSTM 依次应用,一个接收历史天气数据,另一个接收预测天气数据。模型输出为每个预报时间步的流量概率分布参数。
首先,编码器负责从上一段时间内的气象数据中提取信息,它从过去的天气情况中理解河流流量的变化情况。它将历史气象数据转化为可供解码器使用的信息形式的作用。通过学习气象数据中的特征和时间模式,模型对过去气象情况形成抽象理解,为后续的流量预测提供了关键性的输入。
编码器则通过接收一系列气象数据(比如降水量、温度、辐射等)作为输入,学习如何提取这些数据中的关键特征信息。这些特征信息可能包括季节性变化、气象事件(如暴雨、高温等)以及它们对河流流量的影响。
同时,编码器能够捕获气象数据之间的时间依赖关系。这意味着它不仅仅考虑当前时刻的气象情况,还考虑了之前一段时间内的气象变化趋势。通过对历史数据的学习,编码器能够理解气象数据的时间序列模式,并将其纳入到模型中。
在编码器中,LSTM 网络被用来处理时间序列数据。LSTM 具有内部记忆单元,可以记住过去的信息,并根据当前的输入来更新内部状态。这使得编码器能够在处理长期依赖关系时表现优异,并在建模过程中保留重要的历史信息。
最终,编码器将历史气象数据转化为一个潜在的表示形式,这个表示形式包含了对过去气象情况的理解和总结。这个表示形式是编码器的输出,并传递给解码器,用于未来流量的预测。
然后,解码器部分使用这些信息来预测未来几天的河流流量。它考虑了当前的气象预报,以及过去的天气对未来流量的影响。这样,就可以得到未来一周的流量预测。

解码器在模型中负责将历史气象信息和未来预测结合起来,生成对未来河流流量的预测,并输出相应的流量概率分布。
解码器首先接收来自编码器的潜在表示形式,这个表示形式包含了历史气象数据的抽象理解。解码器利用这些信息来理解过去的气象条件对河流流量的影响,并建立起历史数据与未来预测之间的联系。
解码器同时接收未来的气象预测数据作为输入。这些预测数据通常包括了未来几天的降水量、温度等气象指标。解码器将历史信息和未来预测结合起来,通过学习它们之间的关系来预测未来的河流流量。
在理解了历史气象条件和未来预测之后,解码器通过一个独立的 LSTM 网络来生成对未来河流流量的预测。这个网络可以理解为一个时间序列的生成器,根据过去的信息和未来的预测来生成流量序列。
解码器不仅仅预测未来的河流流量值,还输出一个概率分布。具体来说,模型使用一个单边拉普拉斯分布来描述流量的不确定性,预测每个时间步的流量值时,输出一个单边拉普拉斯分布的参数,而不是一个确定的值。这使得模型能够考虑到流量预测的不确定性,为决策提供了更多的信息。
最终的流量预测结果是通过集成多个解码器模型的输出得到的。模型使用了三个独立训练的解码器 LSTM 网络,然后将它们的预测结果取中值,从而减少预测的方差并提高预测的稳定性。
真实效果怎么样?
研究人员收集了大量的气象数据和河流流量数据,来训练这一模型。这些数据来自于不同的数据源,包括气象预报、历史记录和地理信息。通过将数据标准化处理,模型得以正确理解它们。
然后,数据分成两种类型:训练集和测试集。训练集用于训练模型,而测试集则用于评估模型的性能。研究人员使用了一种“交叉验证”的方法,以确保模型在不同的时间和地点都能够有效地工作。
最后,研究团队评估了模型的性能,并与现有的流量预测模型进行了比较。
研究团队采用了常见的误差指标来量化模型预测值与实际观测值之间的差异。由于模型预测的不只是未来流量的具体数值,而且还给出了流量预测的不确定性,因此他们使用了概率积分变换(PIT)图来评估预测分布的准确性。
研究团队还通过与其他流量预测模型的对比来评估所提出模型的性能。这包括了传统的物理模型和其他机器学习模型。通过比较不同模型的误差指标,可以直观地展示所提模型在准确性和可靠性上的优势。
另外,研究团队还采用了特定的流域或河流作为案例研究,应用模型于实际情境中,并详细分析模型在不同季节、不同气候条件下的预测性能。这有助于评估模型在实际应用中的可行性和稳定性。
除了量化指标,研究团队也还对模型预测的不确定性进行了深入分析。这包括评估不同来源的不确定性(如输入数据的不确定性、模型结构的不确定性等)对预测结果的影响,以及模型如何在存在不确定性的情况下仍然提供有用的预测。
结果显示,模型展现了较高的精确度和召回率,尤其是对于短期回报周期的事件。这意味着模型能够准确地识别出洪水事件,并且错过的事件较少。
结合精确度和召回率,模型在不同回报周期的事件上获得了较高的 F1 score,表明了其在准确性和全面性之间取得了良好的平衡。
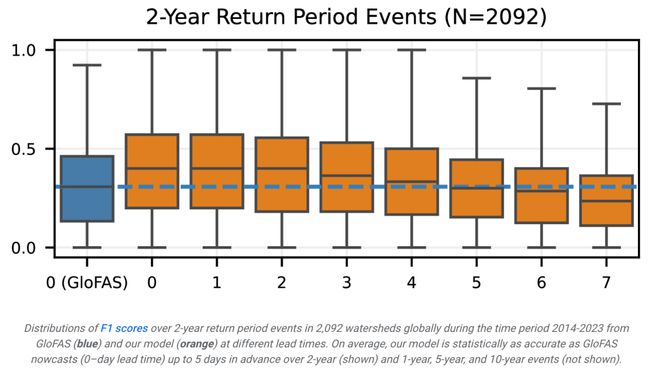
此外,通过双侧 Wilcoxon 符号秩检验,模型的预测结果在统计上显著优于基准模型。这证明了模型在洪水预测方面的有效性。
Cohens d 指标显示,模型性能改进的效果是显著的,这进一步验证了模型相对于传统方法的优势。
在 Nash–Sutcliffe 效率和 Kling-Gupta 效率等水文指标上,模型同样显示了良好的预测精度和对水文过程变化的敏感性。
不足与展望
然而,该研究也存在一些局限性。
例如,实验采用的样本可能较小,限制了研究结果的普遍适用性和统计功效。研究所用的数据集的多样性存在不足,这可能影响模型的泛化能力。采用的模型复杂度较高,可能导致计算成本增加并限制了其可解释性和便捷性。
另外,研究聚焦于特定任务或领域,可能限制了方法的广泛应用;这个方法缺乏长期影响的评估,使得对模型随时间变化的表现理解不足,评估标准可能无法全面反映模型性能;且对现有技术的改进程度可能相对有限。
对此,研究团队表示,未来的工作需要进一步将洪水预报的覆盖范围扩大到全球更多地点,以及其他类型的洪水相关事件和灾害,包括山洪和城市洪水。人工智能技术也将继续发挥关键作用,帮助推动科学研究,促进气候行动。
https://www.nature.com/articles/s41586-024-07145-1
https://blog.google/technology/ai/google-ai-global-flood-forecasting/











