
3 月 16 日消息,苹果公司旗下研究团队近日在 ArXiv 中公布了一篇名为《MM1:Methods, Analysis & Insights from Multimodal LLM Pre-training》的论文,其中介绍了一款「MM1」多模态大模型,该模型提供 30 亿、70 亿、300 亿三种参数规模,拥有图像识别和自然语言推理能力。
苹果研究团队相关论文主要是利用 MM1 模型做实验,通过控制各种变量,找出影响模型效果的关键因素。
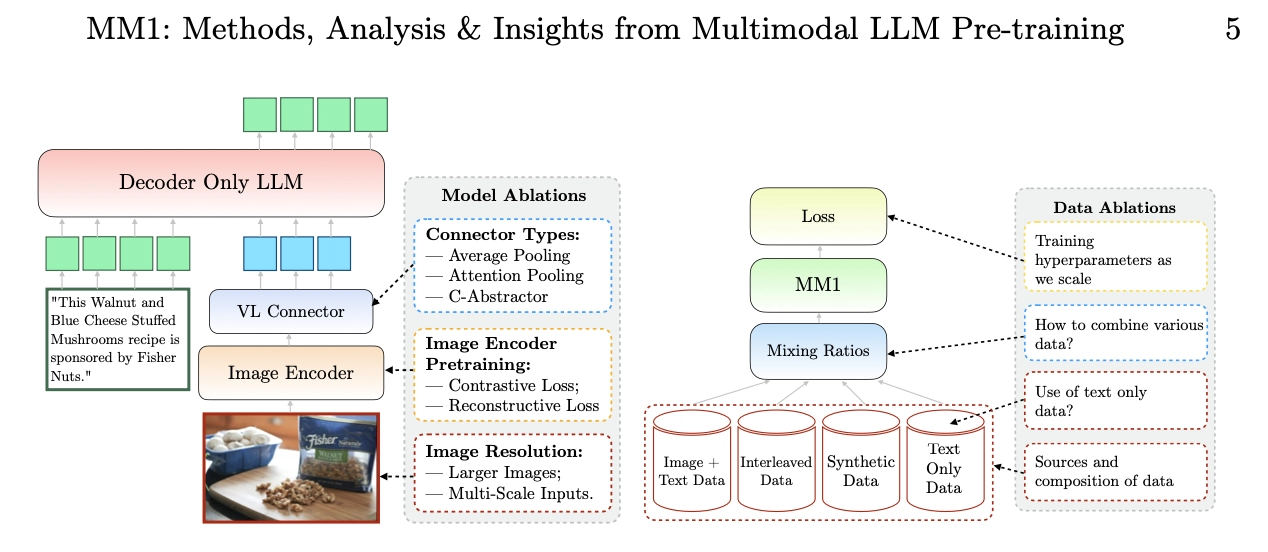
研究表明,图像分辨率和图像标记数量对模型性能影响较大,视觉语言连接器对模型的影响较小,不同类型的预训练数据对模型的性能有不同的影响。(来源:IT 之家)











