投稿作者:白辰甲(上海人工智能实验室青年研究员)、何浩然(上海人工智能实验室实习生)

如何使机器人学习多任务通用具身策略是一项长期的挑战。
从近期大语言模型发展的历程看,获得通用知识的关键是从互联网中获得大量数据,使用大规模网络结构和无监督学习目标进行预训练。
类似的,学习通用具身策略需要从大量机器人交互数据中获得实体、任务、环境、动作的数据,从而更好的理解环境并作出决策。
然而,与视觉和自然语言处理不同,高质量的具身数据获取是非常困难的,且不同机器人的数据往往难以通用。现有研究主要通过借助基础模型作为基础具身策略,但由于机器人和其他领域数据存在较大差异,基础策略往往在具身场景中存在适应性和泛化难题。
近期,上海人工智能实验室、香港科技大学、上海交通大学等联合提出的大规模人类视频预训练和具身策略微调算法给出了一个合理的解决方案,提出了全新的基于视频预测扩散模型的高效策略学习算法:Video-based Policy Learning via Discrete Diffusion(VPDD)来解决该问题。
通过从大规模人类操作数据 Ego4d 学习统一的视频表征,使用大量无动作视频构建自监督视频预测扩散模型预训练任务,并在少量有动作标记的具身数据上进行高效策略微调,能够使通用人类操作视频中编码的物理世界先验知识适应于具身任务,仅利用少量机器人轨迹在 RLBench 等 3D 通用机械臂操作任务集合中获得优异的性能。

背景
通常,学习具身策略往往需要结构化的机器人数据集来进行强化学习或模仿学习训练,数据集中包含机器人观测、动作、奖励或者专家状态-动作。然而,针对特定场景的机器人数据往往非常有限,难以覆盖完整的状态-动作空间决策,在相似场景和真实世界的策略泛化中存在较大困难。一个直觉的解决方案是,能否利用在其他领域的大规模视频数据,特别是人类操作视频来帮助具身决策?人类在现实场景中第一视角的物体操作视频和机器人操作任务具有高度的相似性,包含了物理世界的交互信息,并具有多元的任务场景和复杂的视觉背景,可以帮助具身策略学习物体操作的先验知识。
近期部分工作开始利用人类操作数据去辅助策略学习,然而,现有研究主要集中于从人类视频中提取图像表征或者 Affordance 区域,局限在图像的特征表示而忽略了人类操作视频中蕴含的丰富时序信息的行为信息,不同于现有方法,本研究提出构建基于视频预测(video prediction)来获取智能体对未来轨迹的估计,同时通过机器人数据获得可执行动作的智能体,挖掘在人类操作视频和机器人数据上统一的行为模式。为了有效利用大量人类数据,设计了预训练(pre-traiining)和微调(fine-tuning)的框架,前者可以 scaling up 到大规模的视频数据集,后者可以利用少量数据快速迁移至下游任务。整体框架如下图所示。
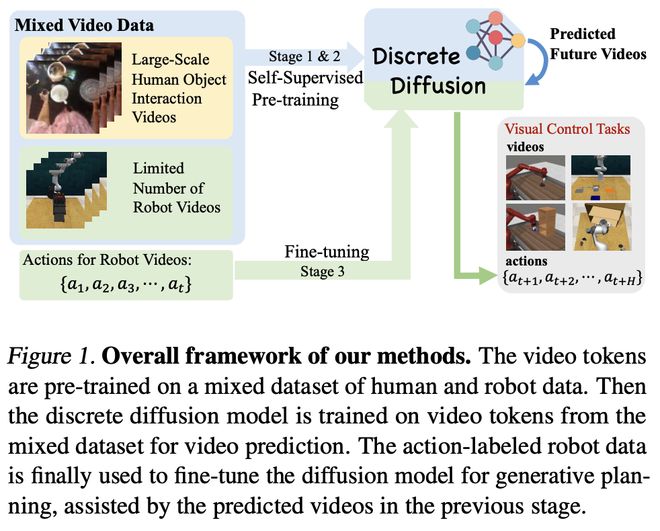
图 1 VPDD 总体思路
方法
方法致力于从三个方面利用人类操作数据解决具身高效策略的学习问题:
在人类操作数据和机器人数据中构建统一的、可泛化、可迁移的视频表征; 使用视频层面的预测任务对轨迹整体建模,而非图像层面建模; 可扩展的框架处理大规模人类视频,同时能够在小规模机器人数据上泛化。1. 统一视频编码
为了从数据分布极广的各种类型的视频数据中提取有效的信息输入给神经网络进行学习,设计视频自编码器 Video VQ-VAE 把视频数据压缩成离散的隐向量,隐向量从训练得到的 VQ-VAE 的码本中提取。这样,对于人类视频或机器人视频,算法都可以用同一个码本中的不同隐向量表征,不仅统一了特征空间去掉了冗余信息,也减少了模型学习的难度。见下图 Stage 1 所示。
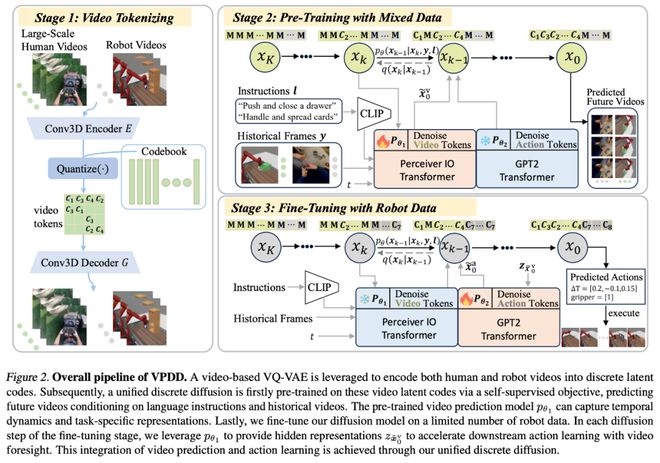
图 2 三阶段学习框架
2. 基于视频的预训练
在预训练阶段,想要从大量视频中提取与物理交互有关的普适知识,设计了自监督学习实现该目标。给定一段历史视频和文本作为 prompts,利用大规模扩散模型预测未来视频 token 序列。当模型能很好地理解交互模式并预测到准确的未来轨迹时,智能体能够对未来可能发生的行为进行预估,从而用该信息去指导下游任务的决策过程。
为了处理复杂和信息量丰富的离散视频编码,并且支持提出的预训练及微调的两阶段训练模式,我们采用表达力极强的离散扩散模型(Discrete Diffusion)进行数据建模和学习。不同于适用于连续状态空间的 Gaussian 扩散模型,离散扩散模型通过 state masking 策略来进行加噪和去噪。VQ-VAE 编码和扩散模型扩散过程可见下图:
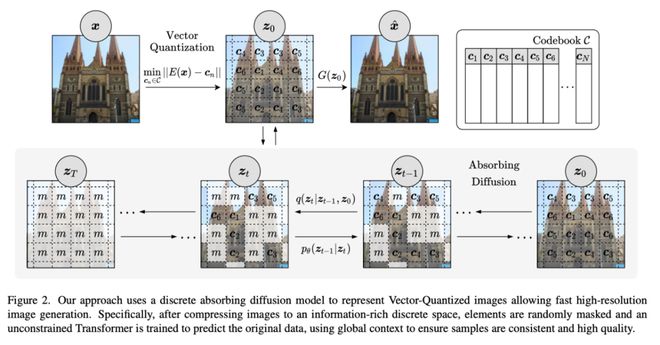
图 3 离散扩散模型,from paper “Unleashing Transformers: Parallel Token Prediction with Discrete Absorbing Diffusionfor Fast High-Resolution Image Generation from Vector-Quantized Codes”
在预训练阶段,为了减小计算开销,我们利用 Perceiver Transformer 作为扩散模型的 backbone;在微调阶段,由于只需要生成低维的 action,我们使用 GPT2 Transformer 作为 backbone,以便于在小规模机器人数据集中进行策略学习。
3. 机器人策略学习
通过从大规模人类数据集中学习到的普遍视频预测模式,在下游机器人任务中仅需要依赖少量机器人数据就能够快速的学习策略。具体的,在微调阶段利用有限的机器人数据集,包括视频和动作,可以输出可执行动作的决策智能体。
实验
方法在单视角视觉观测的的 Meta-World 任务集合和使用多视角观测的 3D 操作任务集合 RLBench 中评估有效性。结果发现,论文提出的方法方法可以成功预测比较准确的未来运动轨迹,无论是单视角还是多视角,这些都通过一个离散扩散模型生成。下面显示了在关键帧附近的相邻视频预测结果。


在具体的决策任务上,本文方法也明显优于以前的方法。重要的是,方法仅需要少量的数据集就可以在各种机械臂抓取任务上达到比较高的成功率,在 Meta-World 和 RLBench 上的实验结果如下:
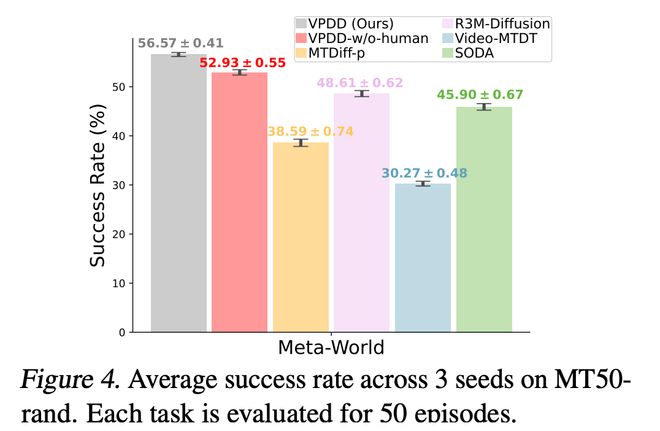

总结
该论文创新性地提出了 VPDD,一种利用离散扩散模型生成未来运动轨迹(视频)并将预训练学习的知识快速迁移至决策中的方法。VPDD 可以灵活地处理各种视频输入的机械臂操作任务,包括单视角相机的 Meta-World(2D 操作)以及多视角相机的 RLBench(3D 操作)。受限于计算资源和模型规模,VPDD 在视频生成上仍有瑕疵,对于某些样本可能存在轨迹不连续或者视角不匹配的问题。未来的工作可以在这些方面继续进行优化。











