明敏丰色发自凹非寺
量子位公众号 QbitAI
什么?谷歌成功偷家 OpenAI,还窃取到了gpt-3.5-turbo关键信息???

是的,你没看错。
根据谷歌自己的说法,它不仅还原了 OpenAI 大模型的整个投影矩阵(projection matrix),还知道了确切隐藏维度大小。
而且方法还极其简单——
只要通过 API 访问,不到 2000 次巧妙的查询就搞定了。
成本根据调用次数来看,最低20 美元以内(折合人民币约 150 元)搞定,并且这种方法同样适用于GPT-4。
好家伙,这一回奥特曼是被将军了!

这是谷歌的一项最新研究,它报告了一种攻击窃取大模型关键信息的方法。
基于这种方法,谷歌破解了GPT 系列两个基础模型Ada 和 Babbage 的整个投影矩阵。如隐藏维度这样的关键信息也直接破获:
一个为 1024,一个为 2048。

所以,谷歌是怎么实现的?
攻击大模型的最后一层
该方法核心攻击的目标是模型的嵌入投影层(embedding projection layer),它是模型的最后一层,负责将隐藏维度映射到 logits 向量。
由于 logits 向量实际上位于一个由嵌入投影层定义的低维子空间内,所以通过向模型的 API 发出针对性查询,即可提取出模型的嵌入维度或者最终权重矩阵。
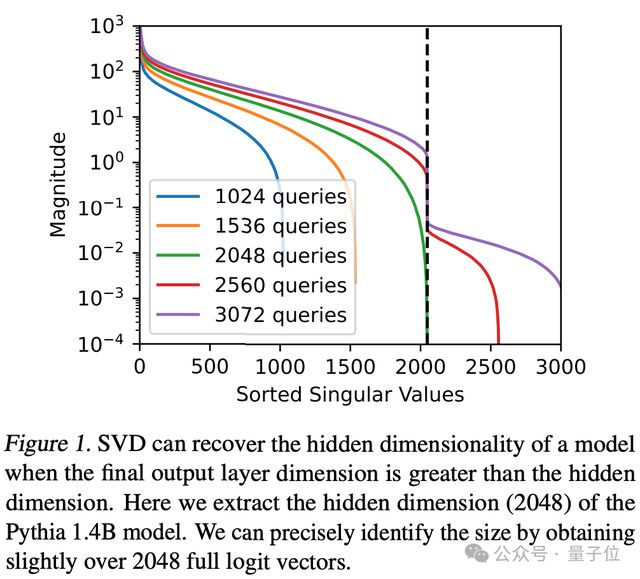
通过大量查询并应用奇异值排序(Sorted Singular Values)可以识别出模型的隐藏维度。
比如针对 Pythia 1.4B 模型进行超过 2048 次查询,图中的峰值出现在第 2048 个奇异值处,则表示模型的隐藏维度是 2048.
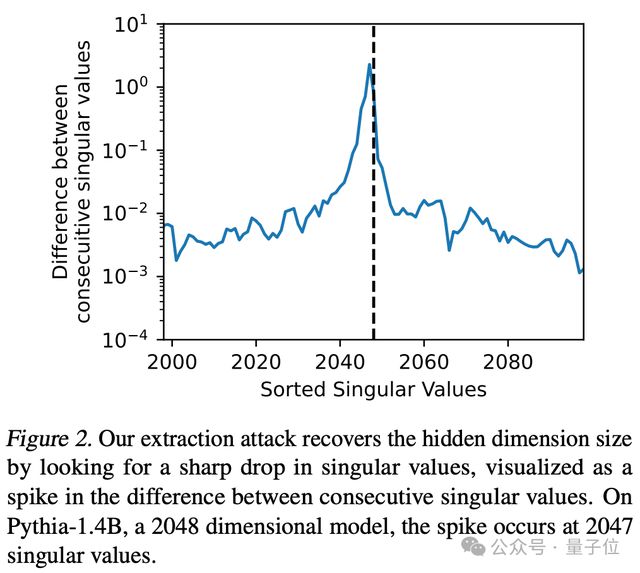
可视化连续奇异值之间的差异,也能用来确定模型的隐藏维度。这种方法可以用来验证是否成功从模型中提取出关键信息。
在 Pythia-1.4B 模型上,当查询次数达到 2047 时出现峰值,则表明模型隐藏维度大小为 2048.
并且攻击这一层能够揭示模型的“宽度”(即模型的总体参数量)以及更多全局性的信息,还能降低一个模型的“黑盒程度”,给后续攻击“铺路”。
研究团队实测,这种攻击非常高效。无需太多查询次数,即可拿到模型的关键信息。
比如攻击 OpenAI 的 Ada 和 Babbage 并拿下整个投影矩阵,只需不到 20 美元;攻击 GPT-3.5 需要大约 200 美元。
它适用于那些 API 提供完整 logprobs 或者 logit bias 的生成式模型,比如 GPT-4、PaLM2。
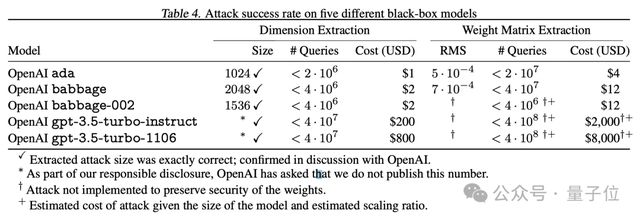
论文中表示,尽管这种攻击方式能获取的模型信息并不多,但是能完成攻击本身就已经很让人震惊了。
已通报 OpenAI
如此重要的信息被竞争对手以如此低成本破解,OpenAI 还能坐得住吗?
咳咳,好消息是:OpenAI 知道,自己人还转发了一波。

作为正经安全研究,研究团队在提取模型最后一层参数之前,已征得 OpenAI 同意。
攻击完成后,大家还和 OpenAI 确认了方法的有效性,最终删除了所有与攻击相关的数据。
所以网友调侃:
一些具体数字没披露(比如 gpt-3.5-turbo 的隐藏维度),算 OpenAI 求你的咯(doge)。

值得一提的是,研究团队中还包括一位 OpenAI 研究员。

这项研究的主要参与者来自谷歌 DeepMind,但还包括苏黎世联邦理工学院、华盛顿大学、麦吉尔大学的研究员们,以及 1 位 OpenAI 员工。
此外,作者团队也给了防御措施包括:
从 API 下手,彻底删除 logit bias 参数;或者直接从模型架构下手,在训练完成后修改最后一层的隐藏维度h等等。
基于此,OpenAI 最终选择修改模型 API,“有心人”想复现谷歌的操作是不可能了。
但不管怎么说:
谷歌等团队的这个实验证明,OpenAI 锁紧大门也不一定完全保险了。
(要不你自己主动点开源了吧)

论文链接:
https://arxiv.org/abs/2403.06634
参考链接:
https://twitter.com/arankomatsuzaki/status/1767375818391539753











