
智东西(公众号:zhidxcom)
编译李水青
编辑云鹏
智东西 3 月 8 日报道,今天,谷歌正式发布了 MediaPipe LLM Inference API,该 API 可以让开发人员更便捷地在手机、PC 等设备上运行 AI 大模型。而 AI 大模型也可以在不同类型的设备上跨设备运行。
谷歌对跨设备堆栈进行了重点优化,包括新的操作、量化、缓存和权重共享等。谷歌称,MediaPipe 已经支持了四种模型:Gemma、Phi 2、Falcon 和 Stable LM,这些模型可以在网页、安卓、iOS 设备上运行,谷歌还计划将这一功能扩展到更多平台上。
在安卓上,MediaPipe LLM Inference API 仅用于实验和研究,生产应用可以通过安卓 AICore 在设备上使用 Gemini API 或 Gemini Nano。
这里有一些实时的 Gemma 2B 通过 MediaPipe LLM Inference API 运行的动图展示。
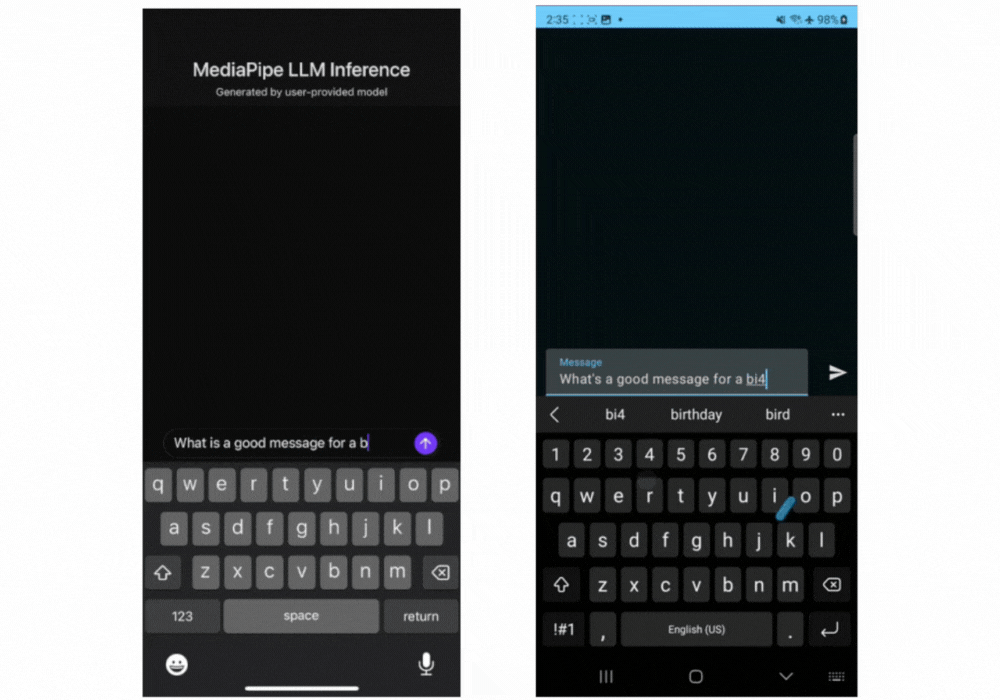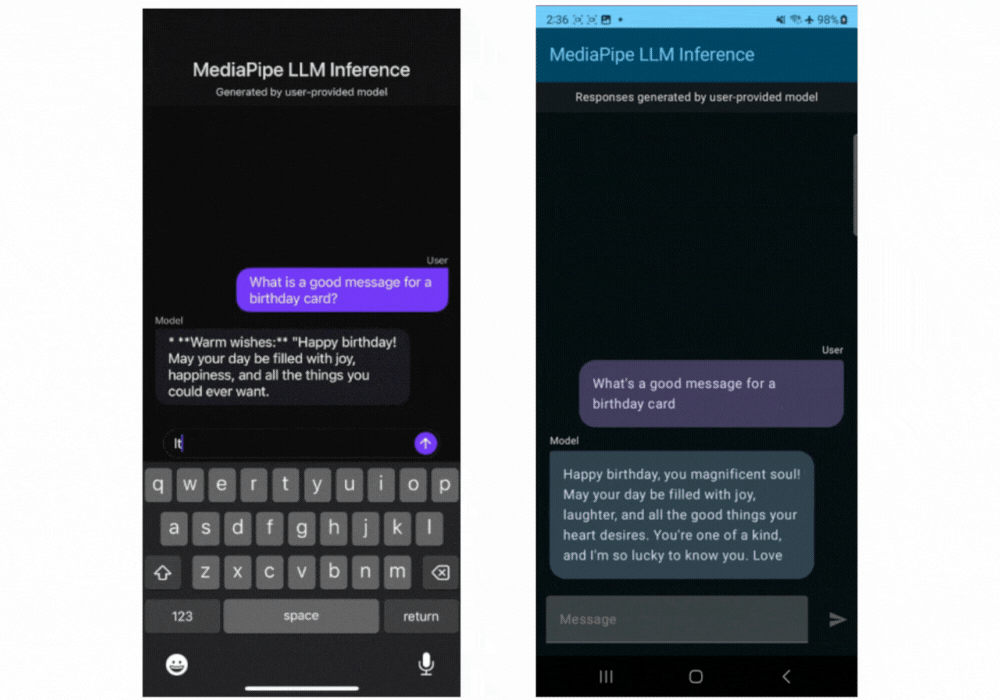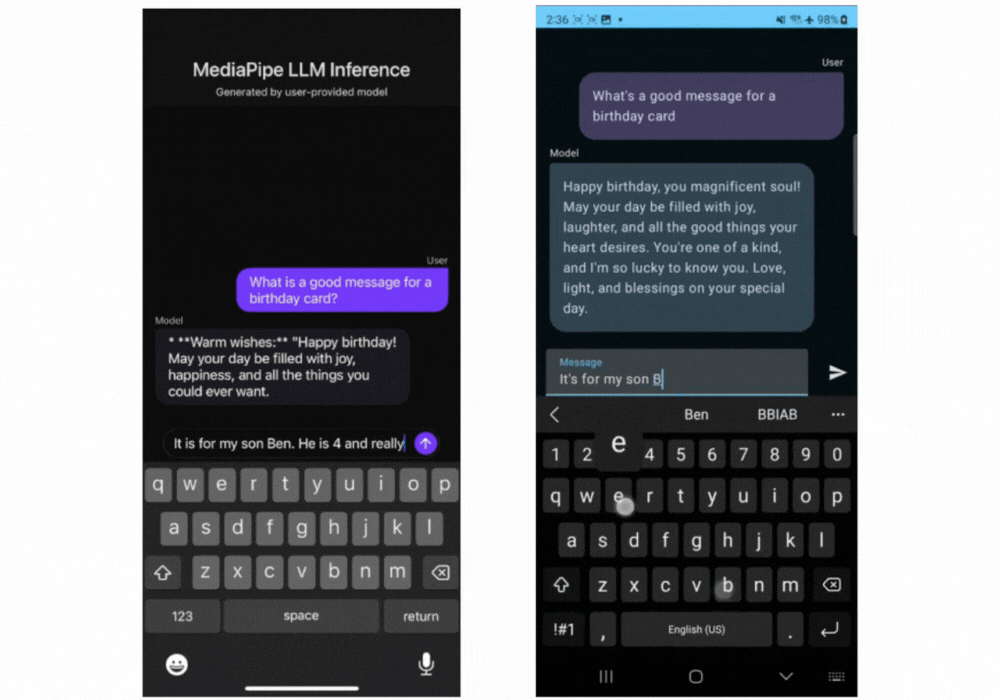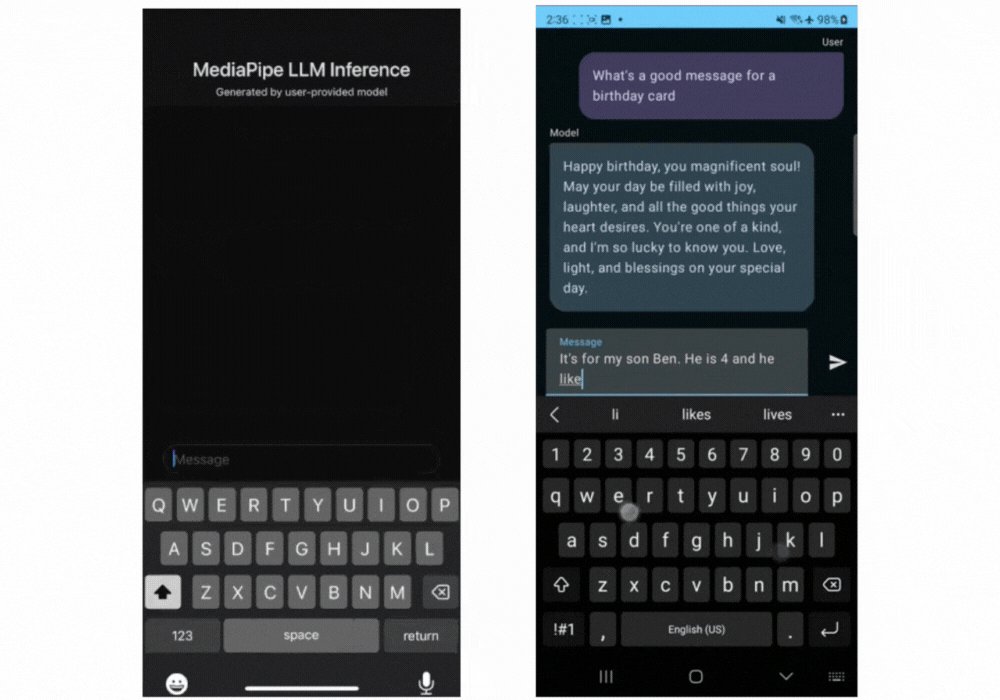
▲Gemma-2B 在 iOS(左)和安卓(右)设备上运行
▲Gemma-2B 在设备上的浏览器中运行
GitHub 地址:
https://github.com/googlesamples/mediapipe/tree/main/examples/llm_inference
开发者文档地址:
https://developers.google.com/mediapipe/solutions/genai/llm_inference
一、四大模型可用,支持网页、安卓和 iOS
MediaPipe LLM Inference API 旨在为开发人员简化设备上的大语言模型集成,支持网页、安卓和 iOS,最初支持四个公开可用的大模型:Gemma、Phi 2、Falcon 和 Stable LM,参数规模在 1B~3B 之间。
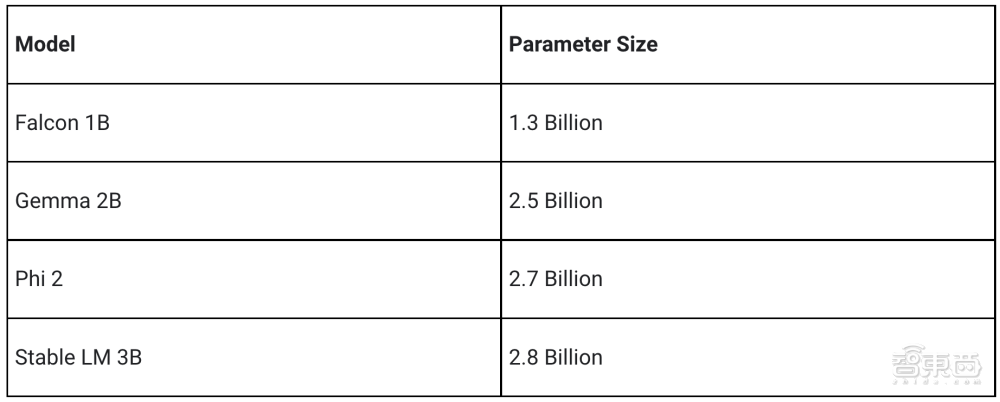
与这些架构兼容的任何模型权重都可以与 LLM Inference API 配合使用。用户可以使用基本模型权重,也可以使用社区微调版或自己的数据微调权重,灵活地在设备上进行原型搭建和测试。
MediaPipe LLM Inference API 能够在设备上实现更低的延迟,同时兼容 CPU 和 GPU,支持多个平台。对于高端手机在实际应用中的持续性能表现,安卓 AICore 可以利用特定的硬件神经加速器进行优化。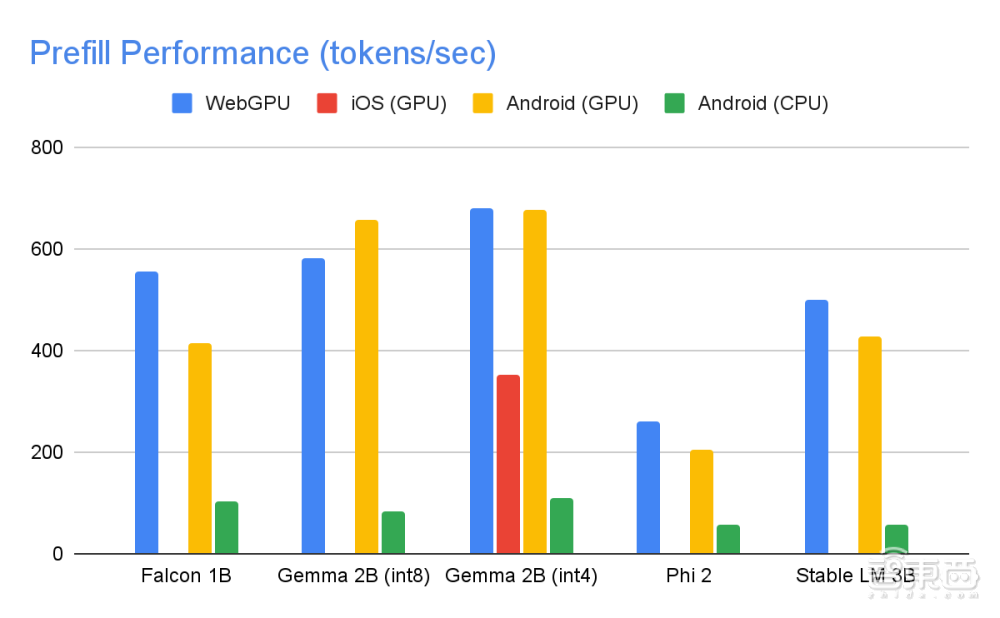
▲五大模型在 GPU 运算时的性能表现
在 GPU 运算时,Falcon 1B 和 Phi 2 模型采用 fp32 激活方式,而 Gemma 和 StableLM 3B 模型则采用 fp16 激活方式。因为团队经过质量评估研究发现,后两个模型在精度损失方面表现出更强的稳定性,因此他们为每个模型都选择了能够维持其质量的最低位数激活数据类型。
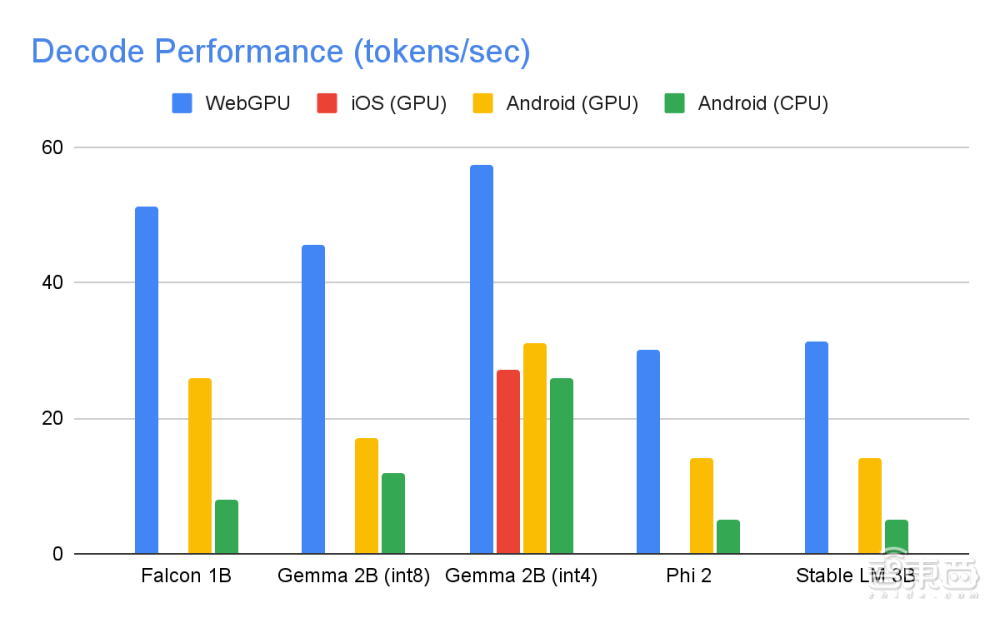
▲五大模型在 GPU 运算时的性能表现
二、简单几步实现模型部署,iOS 仅能运行 Gemma 2B
使用 MediaPipe LLM Inference API,用户通过简单几步就能把模型部署到设备上。
以下的代码样本展示了网页(web)SDK,主要步骤如下:
1. 选择与谷歌支持的模型架构兼容的模型权重。
2. 使用 MediaPipe Python 包将模型权重转换为 TensorFlow Lite Flatbuffer。

3. 在应用程序中接入 LLM Inference SDK。

4. 与应用程序一起托管 TensorFlow Lite Flatbuffer。
5. 使用 LLM Inference API 从模型获取文本提示并得到文本响应。

在安卓上,MediaPipe LLM Inference API 仅用于实验和研究。生产应用可以通过安卓 AICore 在设备上使用 Gemini API 或 Gemini Nano。AICore 是在安卓 14 中引入的新的系统级能力,为高端设备提供 Gemini 驱动的解决方案,包括与最新的 ML 加速器、用例优化的 LoRA 适配器和安全过滤器的集成。
在 iOS 上,由于内存限制,目前只有 Gemma 2B(int4)模型可运行,但谷歌正在努力使其他模型也能在 iOS 平台上启用。
三、权重共享、自定义操作符,六大优化增强模型性能
为了达到更优性能表现,谷歌在 MediaPipe、TensorFlow Lite、XNNPack(谷歌 CPU 神经网络操作库)和 GPU 加速运行时中进行了无数的优化。
以下是一些带来性能显著提高的一些选定优化:
权重共享:LLM 推理通常包含两个阶段:预填充和解码。传统做法是为这两个阶段分别设置独立的推理上下文,各自管理对应的机器学习模型资源。但考虑到大型语言模型对内存的高需求,谷歌引入了一项新特性,允许在不同的推理上下文之间共享权重和键值(KV)缓存。
优化的全连接操作:XNNPack 的 FULLY_CONNECTED 操作在针对大型语言模型推理时,进行了两项关键优化。首先,通过动态范围量化技术,团队成功地将全整数量化在计算和内存方面的优势,与浮点推理在精度方面的优势完美结合。使用 int8/int4 权重不仅大幅提升了内存吞吐量,还显著提高了性能。其次,团队充分利用了 ARM v9 CPU 中的 I8MM 指令,使其可以在一条指令内完成2×8 int8 矩阵与8×2 int8 矩阵的乘法运算,从而实现了比 NEON 点积基础实现快一倍的速度。
平衡计算和内存:在对 LLM 推理进行分析时,团队发现了两个阶段的明显限制:预填充阶段面临计算能力施加的限制,而解码阶段受到内存带宽的限制。因此,每个阶段采用不同的策略对共享的 int8/int4 权重进行反量化。在预填充阶段,每个卷积操作首先将权重反量化为浮点值,然后进行主要计算,确保计算密集型卷积的最优性能。相反,解码阶段通过将反量化计算添加到主要的数学卷积操作中,最小化了内存带宽。
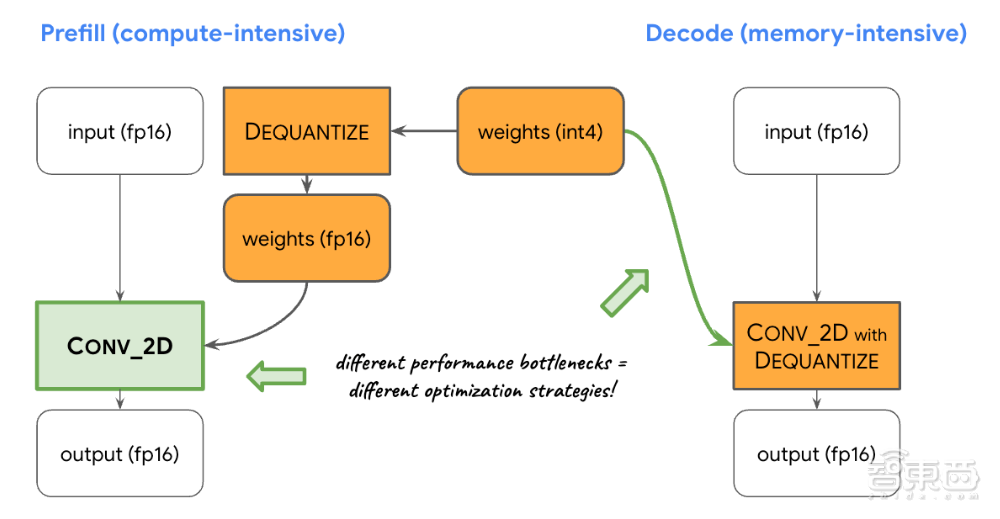
▲平衡计算和内存过程示意
自定义操作符:对于设备上的 GPU 加速大模型推理,团队广泛依赖自定义操作来减轻由许多小着色器引起的低效率。这些自定义操作允许进行特殊的操作符融合,并将各种大模型参数(如令牌 ID、序列补丁大小、采样参数等)打包到主要用于这些专门操作的专门的自定义张量中。
伪动态性:在注意力块中,团队遇到随着上下文增长而增加的动态操作。由于 GPU 运行时缺乏对动态操作/张量的支持,团队选择使用预定义的最大缓存大小的固定操作。为了降低计算复杂性,团队引入了一个参数,使得可以跳过某些值计算或处理减少的数据。
优化的 KV 缓存布局:由于 KV 缓存中的条目最终作为卷积的权重,代替矩阵乘法,团队将这些存储在为卷积权重定制的专门布局中。这种策略性的调整消除了对额外转换或依赖于未优化布局的必要性,因此有助于更有效和流线型的过程。
结语:谷歌最新 API,剑指大模型跨设备运行
早在 2019 年,谷歌的 MediaPipe 就已经出现,并开始扩展 TensorFlow Lite 的能力,起初这些 AI 工具主要聚焦于小型设备上的模型。
此次谷歌发布的新版本可以让大模型在各个平台上实现完全本地化运行。众所周知,大模型对内存和算力的需求都是很大的,所以谷歌的这项技术颇具变革性。
2024 年,谷歌将把 MediaPipe LLM Inference API 扩展到更多的平台和模型,提供更广泛的转换工具、免费的设备上组件、高级任务等。这也将为其的大模型生态版图扩张提供支持。
来源:谷歌开发者官网











