Kafka 线上性能调优是一项综合工程,不仅仅是 Kafka 本身,还应该从硬件(存储、网络、CPU)以及操作系统方面来整体考量,首先我们要有一套生产部署方案,基于这套方案再进行调优,这样就有了可靠的底层保证,才能保证 Kafka 集群整体的稳定性。
1. 线上部署方案
1.1 操作系统
我们知道 Kafka 是用 Scala 和 Java 这两种语言编写的,而这两种语言都依赖 JVM 运行,理论上和操作系统关系应该不大。但是不同操作系统底层的 API 是不同的,综合来说采用 Linux 系列的发行版比 Windows 系统来说性能优势更佳。
从 I/O 模型上来看,通常有阻塞 I/O、非阻塞 I/O、I/O 多路复用、事件驱动 I/O 以及 异步 I/O 这 5 种,每种 I/O 模型都有适合的应用场景,比如 Java 中的 Socket 就有阻塞和非阻塞两种使用模式,而 Linux 中的 select 就属于 I/O 多路复用,epoll 其实像介于多路复用和事件驱动模型之间的一种模型。
Kafka 在客户端底层使用了 Java 的 selector,而 selector 在不同平台上的实现也不完全一样,比如在 Linux 上的实现机制是 epoll,而在 Windows 上的实现机制是 select,由于 epoll 相比 select 的优势很大,所以将 Kafka 部署在 Linux 上的 I/O 性能会更好。
然后就是网络传输性能上的差距,在 Linux 上 Kafka 会直接利用零拷贝的特性来提升传输的性能,但是在 Windows 上直到 JDK 8 Update 60 版本才能支持零拷贝的特性,所以 Linux 上的支持天然的就比较好。
最后是社区的支持,社区上的大部分 bug 修复都是建立在 Linux 环境之上的,因为绝大部分人的运行环境都是 Linux,Windows 上面的 bug 基本上不会修复或者速度奇慢,所以社区对 Linux 更友好。
综合来看,生产环境一定要选择 Linux 发行版来部署,Windows 只用于个人测试即可。
1.2 磁盘
Kafka 消息存储会占用大量的磁盘空间,磁盘也是 Kafka 运行最重要的底层保证,Kafka 之所以性能这么高,除了上面说的零拷贝技术之外,还有非常重要的一点是所有的消息都是顺序存储的,即使是机械盘也能有出色的表现,因为对于机械硬盘来说顺序读取相比随机读取的优势是碾压性的,SSD 在顺序读取这块虽然比机械硬盘更高,但是仍然算是一个数量级的,所以 SSD 更适合用在随机读写频繁的场景,例如数据库搜索方面。
当然由于 SSD 价格不断降低,很多公司 Kafka 也都是跑在了 SSD 上,所以 SSD 对于 Kafka 来说不是必须,有条件可以用,否则用机械硬盘也是没问题的,但是无论如何千万不要使用 NFS 等网络存储,否则丢数据的风险会比较大,稳定性也会大打折扣。
另外就是是否使用 RAID 的问题,RAID 的作用主要就是提供本地数据冗余以及磁盘的负载均衡,但是 Kafka 本身已经提供了副本机制,所以对 RAID 的需求也不是太强,但是由于 RAID 可以在底层数据层面提供保障,所以也确实可以为 Kafka 带来可靠性的提升,但是 Kafka 的副本仍然不可或缺。
所以综上我们可以得出结论,生产环境直接使用普通机械硬盘并且创建 2 个或以上副本即可达到比较高的可靠性要求,如果有条件想进一步提升性能或可靠性可以选择 SSD 或者 RAID。
1.3 存储空间评估
Kafka 的存储空间评估其实并不复杂,在集群上会存在多个 Topic,每个 Topic 所占用的容量评估的计算方法是完全一样的,假如我们有一个 Topic,每天会接收 1 亿条左右的消息,每条消息的大小大约 1KB,那么我们来看一下怎么评估所占用的空间。
首先是每天 1 亿条 1KB 的消息占用的空间大小为:100GB,那么还要考虑到 Topic 下面的分区会存在副本以及消息所保留的天数,假如这个 Topic 有两个副本,并且保存 7 天,那么磁盘最大的占用是:2 × 7 × 100GB = 1.4TB,另外 Kafka 还存在着索引数据和临时文件等,我们通常留出 10% 的冗余,那么总占用为:1.54 TB。
另外就要考虑压缩的因素了,如果我们的生产者开启了数据压缩,我们需要根据实际消息测试一下压缩比,假如我们的压缩比测试结果是 1.2,那么实际的空间占用就是:1.28 TB。
单个 Topic 的容量就估计出来了,然后对每个 Topic 都按照同样的方法估计出容量之后并求和得到 Kafka 集群总的存储大小,通常数据是均匀分布的,我们用总的存储占用除以 Broker 节点数量,就得到了每个节点所使用的容量,最后我们就可以根据这个评估结果来合理分配硬件。
所以综合来说,评估 Kafka 的存储空间要考虑下面的几个主要因素:
Topic 数量 平均消息数量 平均消息大小 消息存储时间 副本数量 是否压缩充分考虑这些因素就可以合理评估 Kafka 的存储空间了。
1.4 带宽评估
Kafka 在实际使用中会大量使用网络进行消息传输以及副本的同步,所以带宽很容易出现瓶颈,出问题的概率往往也是比较高的,如果还涉及到跨网传输数据,那么会更容易出现问题。
我们通常使用的网络环境是 1Gbps 千兆网络或者 10Gbps 万兆网络两种,而且千兆网络应该是最低配置,假如对于千兆网络要实现每小时 1TB 的业务处理,需要多少台呢,我们下面来分析一下。
对于千兆网络来说,为了防止丢包并且保证系统其他的关键进程的正常使用,我们的可用带宽按照 70% 来计算,也就是说 Kafka 最多可用 700Mbps 的资源。但是这个值是 Kafka 的最大值,我们不可能让 Kafka 日常都跑在这个带宽上,还要考虑到业务高峰期的占用等,我们必须留出一部分冗余,保守估计是 1/2 左右,因此 Kafka 的常规运行带宽为:700/2 = 350Mbps。
那么每小时传输 1TB 每秒的带宽大约为:2330Mbps,那么 Kafka 节点个数为:2330/350 = 6.66,节点个数必须向上舍入,因此需要 7 个节点。
如果我们此时需要创建 3 个副本,那么共需要:3*7 = 21 个节点才能完成要处理数据的目标,看起来这个值比较大,可能存在 CPU 过剩的问题,而事实上 Kafka 确实是 I/O 密集的,CPU 通常也是够用的,所以我们可以通过增加带宽来适当地减少节点个数,当然我们推荐在生产环境中使用万兆网络带宽。
有了上面的规划和准备,在这个基础之上,我们就可以来着手进行 Kafka 集群的整体优化了。
2. 操作系统参数优化
操作系统是保证 Kafka 集群正常运行的关键因素,不过 Kafka 对操作系统本身的优化并没有很强的依赖性,也就是说默认情况下的参数也是够用的,我们这里只需要调整几个特别重要的参数即可。
2.1 最大文件数
这个参数是数据系统中最重要的参数之一,因为操作系统默认只给允许进程同时打开 1024 个文件,这个数量显然有些小了,而且网络连接也占用文件句柄,如果进程打开的总文件句柄数超出了限制那么就会报错:Too many open files.,因此我么有必要将这个参数调大,查看当前的设置值:
ulimit -n默认应该是 1024,如果临时调大可以使用命令:
ulimit -n 65535不过这个调整是临时的,只有在当前会话中启动的进程才是有效的。
那么我们怎么确定一个正在运行的进程所能用的最大文件数量是多少呢?可以先拿到进程的 PID,然后查看其对应的状态数据:
cat /proc/$PID/limits这样就可以看到当前进程所能打开的最大文件数量限制了。
如果我们想实现在用户会话建立后使得最大文件数配置自动生效,可以有下面两种方法。
第一个方法是借助登录时的 PAM 设置来实现,在使用 SSH 连接时如果开启了 PAM 策略,就可以实现一系列的限制,比如 fail2ban、会话保持时长等,默认情况下是自动为 SSH 开启 PAM 的,可以通过配置文件 /etc/ssh/sshd_config 来确认。
UsePAM yes然后可以查看 PAM 关于登录的配置文件 /etc/pam.d/login 其中会直接配置或者通过 include 的相关文件来间接配置了 PAM limits:
session required pam_limits.so默认情况下这些都是会配置上的,只有在出现问题时我们才考虑排查这些设置。
关于 PAM limits 的配置文件需要编辑 /etc/security/limits.conf 然后增加配置如下:
# * 表示设置所有的用户的文件数 (注意: root用户除外) * soft nofile 1000000 * hard nofile 1000000 # 设置root用户的文件数 root soft nofile 1000000 root hard nofile 1000000这里我们设置最大文件数的软限制和硬限制都是 100 万,设置好之后保存这个配置。
需要特别注意的是这个值一定不能超过内核参数 fs.nr_open 的设置,这个值在 Linux 内核代码中被定义为 1048576 差不多就是 100 万多一点,设置前可以执行下面的命令确认:
sysctl fs.nr_open超出这个值会导致后面无法登录系统,只能通过救援模式修改回来,所以务必谨慎。
关于 fs.nr_open 内核参数在 Linux 内核源码中的定义部分如下:
unsigned int sysctl_nr_open __read_mostly = 1024*1024; unsigned int sysctl_nr_open_min = BITS_PER_LONG; /* our min() is unusable in constant expressions ;-/ */ #define __const_min(x, y) ((x) < (y) ? (x) : (y)) unsigned int sysctl_nr_open_max = __const_min(INT_MAX, ~(size_t)0/sizeof(void *)) & -BITS_PER_LONG;这个值默认是 1024*1024 也就是 1048576,并且最大值受限于 sysctl_nr_open_max 的值,这个值结果是 2147483584,当设置超过这个值的时候也会报错。在较新的 Linux 发行版中 fs.nr_open 的值会被修改为 1073741816,总之 fs.nr_open 内核参数不需要修改,只需要在设置之前确认不要超过即可。
最后保存完上面的配置后,重新建立 SSH 连接登录会话即可生效,然后就可以启动 Kafka 服务了。
第二种方法比较简单,我们通过登录时设置当前用户的环境变量即可,可以修改 ~/.bashrc 配置文件并添加内容:
ulimit -HSn 1000000其中 -H 和 -S 分别指定硬限制和软限制,保存后重新开启会话也可以生效。
另外要注意的是如果进程采用 Systemd 来管理,那么不受上面会话参数配置的影响,由具体的 Systemd 服务文件来配置,上面这些参数只能用于在当前会话中手动启动的进程,比如 Kafka 通常采用 kafka-server-start.sh 脚本来启动就是可以的。
2.2 交换分区
交换分区是磁盘上的一块空间,可以在物理内存的空间不足时,将一些不太常用的页面换出到交换分区,从而支持更多的进程运行,但是由于磁盘和内存的性能差距不在一个数量级,交换分区一旦使用频繁系统运行将被严重拖慢。
一方面当我们查看内核进程 kswapd0 的占用比较高,说明内存已经开始换入换出了,需要排查是哪个进程占用了大量的内存,是内存确实不够用还是应用程序设计缺陷导致。
另外我们也可以查看进程的状态文件来确认是否占用了交换分区:
grep ^Swap: /proc/$PID/smaps如果发现存在不少的分区占用,可以汇总看下一共有多少占用:
grep ^Swap: /proc/$PID/smaps | awk {sum+=$2}END{print sum}如果确实存在不少的占用,可以进一步分析下进程的换页率:
# -B 查看内存页面统计 1 秒显示一次,共显示 10 次 sar -B 1 10如果发现 pgpgin/s 或者 pgpgout/s 数值比较高,那么就要小心了,这会导致进程的执行被拖慢。
现在服务器的内存通常都比较大,对于 Kafka 其实大量的内存都是 page cache 的占用,虽然内存是够用的,但是操作系统仍然会有使用交换分区的情况,所以为了保证运行的性能,建议将交换分区关闭掉或者降低交换分区的使用倾向。
如果是降低交换分区使用的权重可以通过调整内核参数 vm.swappiness 实现:
sysctl -w vm.swappiness=0 >> /etc/sysctl.conf # 查看修改的文件内容 sysctl -p默认情况下 vm.swappiness 的值是 60,调整为 0 之后就可以很大程度降低交换分区的使用,当物理内存确实不够用的时候,操作系统仍然会使用交换分区,彻底关闭交换分区可以先执行命令:
swapoff -a执行这个命令后操作系统会将交换分区的数据都换到内存中,所以如果交换分区有占用那么命令执行会比较缓慢,执行完成后我们编辑 /etc/fstab 从中删除掉交换分区自动挂载的条目,那么下次机器再重启时就不会挂载交换分区了。
2.3 文件系统
文件系统方面建议选择比较主流成熟的文件系统,目前推荐 ext4 或者 XFS,建议使用 XFS,因为 XFS 具备高性能和高伸缩性等特点,更加适合于生产环境中。
不过根据比较新的研究结果,使用 ZFS 作为 Kafka 的底层存储可以取得更好的效果,比如 ZFS 的多级缓存机制可以帮助 Kafka 改善 I/O 性能,不过这只是处于实验室的研究,我们了解即可,目前生产环境还没办法很好地使用。
另外还可以在挂载设备时关闭 atime 记录,atime 其实就是 access time,默认挂载情况下每次访问文件后文件系统都会进行记录从而更新 atime,比如使用 cat 访问文件就会更新 atime,记录 atime 需要额外访问 inode 信息,如果禁用掉 atime 就可以避免每次访问文件后写入时间的操作,从而在一定程度上提高文件系统的性能:
mount -o noatime /dev/sdX /data2.4 进程 VMA(内存区域)数量
进程的VMA(虚拟内存区域),其实就是进程通过 mmap 等系统调用创建的虚拟内存空间,当然也包括文件映射I/O,但是操作系统默认对进程所能使用的虚拟内存数量是有限制的,默认值是 65530,可以通过命令查看当前的值:
sysctl vm.max_map_count如果在 Kafka 集群中存在非常多的 Topic,如果 VMA 的数量超过了限制可能会报错 OutOfMemory Error: Map failed ,这其实是内存溢出的另外一种情况。
因此我们在生产环境建议调大此内核参数的配置:
sysctl -w vm.max_map_count=2048000 >> /etc/sysctl.conf # 查看当前的设置 sysctl -p3. 最重要的集群参数配置
3.1 JVM 参数
首先 Kafka 是运行在 JVM 上的,所以 JVM 的合理设置对于 Kafka 的正常运行至关重要,首先是 JDK 版本,建议最低使用 JDK 1.8 版本,因为从 Kafka 2.0 开始已经摒弃了对 JDK 1.7 的支持,所以在生产环境中至少使用 JDK 1.8 版本,建议使用 JDK 11,这样可以带来更多的优化。
然后就是最重要的 JVM 堆大小参数,现代服务器的内存都比较大,64GB、128GB 都非常常见,但是 JVM 堆内存不建议设置太大,因为 Kafka 本身并不会占用非常大的内存,相反 Kafka 会充分利用操作系统的文件系统缓存来加速文件的读写,因此大部分的内存应该留给文件系统缓存。不过默认的情况下 Kafka 的堆内存只有 1GB,这确实也有点小了,所以我们直接建议将堆内存设置为 6GB,这个值是业界公认的一个合理值,Kafka Broker 在和客户端通信时会在堆上创建很多 ByteBuffer 的实例,所以在大吞吐的前提下还是需要不少 JVM 空间的,修改方法是编辑启动脚本 kafka-server-start.sh 修改其中的 KAFKA_HEAP_OPTS 变量即可:
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then export KAFKA_HEAP_OPTS="-Xmx6G -Xms6G" fi然后启动 Kafka 服务就可以了。
除了堆内存大小,还有比较重要的一块就是垃圾收集器部分,当然在 Kafka 2.5 中会自动设置 JVM 参数开启 G1GC,如果是 JDK 11 则默认情况下的垃圾回收器就是 G1GC,我们无需做任何配置,我们可以查看进程的启动参数或者查看进程当前的 JVM 参数:
jinfo -flags $PID如果我们看到 JVM 参数中没有开启 G1GC,我们可以修改 Kafka 的脚本 kafka-run-class.sh 在其中添加下面的变量即可:
export KAFKA_JVM_PERFORMANCE_OPTS="-server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -Djava.awt.headless=true"这样我们就可以使用 G1GC 了。
总的来说 Kafka 正常并不需要对 JVM 做过多的优化,主要注意下面几点即可:
最低要使用 JDK 1.8 版本,推荐用 JDK 11 设置堆内存大小为 6GB 使用 G1GC 垃圾回收器3.2 Broker 端参数
Kafka Broker 端有众多的参数需要配置,但是大部分只需保持默认即可,有一些非常重要的参数需要我们来修改,我们来重点看下这些参数,下面的配置都是基于 Kafka 2.5 版本进行调优,其余版本需要具体参考相关的文档。
首先是端口和通信的监听配置,这主要涉及下面两个参数:
listeners 这个配置 Broker 要监听的列表,默认情况下的值为 PLAINTEXT://:9092 如果主机名留空则会绑定到默认的网络接口,其实也就是全部的网络接口,然后后面跟要监听的端口号,默认是 9092。 advertised.listeners 这个配置发布到 ZooKeeper 供客户端使用的监听器,当这个配置和 listeners 不同时会用到,默认如果没有设置会和 listeners 的值保持一致。通常我们在生产环境中 listeners 保持默认即可,建议客户端都使用和集群一致的主机名进行访问,如果客户端使用 IP 地址访问,而客户端本地又没有配置 hosts 时就会出现刚接触 Kafka 常见的主机无法解析的错误,这是因为在没有配置 advertised.listeners 的情况下其配置和 listeners 一致,这样当客户端发起连接时 ZooKeeper 会返回类似于 PLAINTEXT://<hostname>:9092 这样的地址,但是本地又找不到这个地址,所以就会出现报错,这种情况下我们可以在客户端也放一份和 Kafka Broker 上一样的 hosts 文件,或者在 Kafka 中配置:
advertised.listeners=PLAINTEXT://10.1.0.2:9092这样相当于告诉 ZooKeeper 返回的是 Kafka Broker 的 IP 地址,这样客户端不需要任何修改就可以正常生产消费数据了。
另外还有一种情况是 Kafka Broker 和客户端不在一个网段,是通过在路由上配置了 NAT 的方式进行访问,这种方式也会使得客户端访问的网络地址和 Kafka Broker 局域网的 IP 地址不相同,也需要通过合理设置 advertised.listeners 实现正常访问。
另外还有一些参数,比如像 advertised.host.name 、advertised.port 、host.name 还有 port 参数都已经废弃了,直接忽略存在即可,只配置上面两个参数就可以了。
然后我们再来看 Kafka 消息存储的配置,这个同样也是有两个可配置的参数:
log.dirs 这个是非常重要的参数,这个指定了 Kafka Broker 保存数据的目录列表,注意这个是支持多个目录配置的。 log.dir 这个同样是配置 Kafka Broker 保存数据的目录,不过这个只能配置单个路径第一个参数 log.dirs 是没有默认值的,如果不配置的话会使用 log.dir 的配置,也就是 /tmp/kafka-logs 。不过在 Kafka 的配置文件中默认已经给了 log.dirs 配置值 /tmp/kafka-logs ,所以我们在配置过程中只需要关心 log.dirs 而忽略 log.dir 就可以了。
通常我们会准备单独的数据存储硬盘给 Kafka 使用,如果只配置一个目录的话 Kafka 和早期版本是一样的,就是将数据分区分段直接写入磁盘。
如果配置多个目录的话,比如:
log.dirs=/data1/kafka-logs,/data2/kafka-logs,/data3/kafka-logs这样 Kafka 会将分区均匀分散到多个目录中,相当于 RAID 0 写入,这样可以进一步提高数据写入和读取的 I/O。
从 Kafka 1.1 开始还支持了强大的故障转移功能,假如我们配置的多个存储盘有其中 1 个盘坏掉了,那么 Kafka 会自动从其他可用的分区拉取这部分坏掉的副本,并写入其他可用的存储目录,使得整体可用的副本数量和 Topic 创建时指定的保持一致。有了这种能力就相当于在之前副本的基础上进一步增加了容错性,这样的话即使底层不使用 RAID 也可以满足基本的存储可靠性。
配置完存储后我们再来看下 ZooKeeper 的配置,Kafka 依赖 ZooKeeper 管理元数据并实现 Leader 的选举等功能,是 Kafka 比较重要的底层支撑,不过配置确实比较简单,通常只需要配置 zookeeper.connect 即可,例如:
zookeeper.connect=zk1:2181,zk2:2181,zk3:2181/kafka首先是 ZooKeeper 的节点尽量要写全,另外就是尽量配置 znode,比如 /kafka ,如果有多套 Kafka 集群为了元数据互不影响可以配置多个 znode 来隔离,例如:/kafka1 和 /kafka2 等。
然后我们再来看一下 Topic 相关的配置参数,这里主要有下面的 4 个参数:
auto.create.topics.enable 是否允许 Kafka Broker 自动创建 Topic。 unclean.leader.election.enable 是否允许 Unclean Leader 选举。 auto.leader.rebalance.enable 是否启用自动 Leader 平衡。 offsets.topic.replication.factor 用于管理偏移的 Topic 副本数量。我们依次来看,首先是 auto.create.topics.enable 这个参数,这个参数默认设置是 true ,表示 Kafka Broker 允许自动创建不存在的 Topic,我们有时候会发现线上的 Kafka 环境中经常会有一大堆 Topic,都不确定哪些有用哪些没用。有时候一不小心 Topic 名称拼写错了,只要启动生产者后就会自动创建,这样会导致集群上出现很多稀奇古怪的 Topic。
另外,如果我们没有配置默认的分区和副本数量,那么创建出来的 Topic 可能只有 1 个分区并且不存在副本,线上都运行很长时间了等到性能出现瓶颈后经过排查发现只有 1 个分区,这种情况往往是还没有创建 Topic 就开始跑生产者导致 Kafka Broker 自动创建了 Topic,而这个 Topic 的参数大概率不是最优的。
综合以上问题来看,真正用于生产环境的 Kafka 是不允许随意创建 Topic 的情况出现的,这会带来很多的不好的影响,往往是之后导致问题的根源,所以这个参数我们建议设置为 false ,一定要明确先创建 Topic 然后才能使用。
然后看第二个参数 unclean.leader.election.enable 这个参数的含义之前关于 Kafka 分片和副本的文档已经详细解释过了,如果开启虽然会提升可用性,但是也可能造成更多的数据丢失,幸好在 Kafka 中这个参数默认值就是 false ,我们一般不用关心,但是这个参数的含义我们应该充分理解,生产环境为了避免出现问题我们甚至可以显式设置为 false 。
然后来看 auto.leader.rebalance.enable 这个参数我们并不常见,但是对生产环境其实是有一定的影响的,默认情况下这个参数是 true ,表示 Kafka 会定期对分配不均的 Leader 进行重新选举。具体实现是由后台线程定期检查所有分区中 Leader 的分布,检查的周期由参数 leader.imbalance.check.interval.seconds 配置,默认是 300s,如果节点间分配不平衡的程度超过参数 leader.imbalance.per.broker.percentage 的设置,这个参数默认是 10,表示 10%,则会重新执行选举。
但是事实上,线上的 Kafka 如果节点出现故障,Leader 会重新选举到其他的节点,如果故障节点恢复后会自动成为 Follower,所以随着集群的运行,Leader 的分布会不断偏离初始情况下的均匀状态,这个参数就是通过选举来恢复初始的平衡状态,从而减小 Leader 比较多的节点的压力。但是仍然会存在很多节点 Leader 运行的状态比较好,但是仍然被强行换成了其他节点,而更换 Leader 的过程中所有的生产者和消费者都会阻塞完成这个变更,所以更换 Leader 的代价还是非常高的,最主要的是会造成业务的暂时中断,所以对于生产环境建议将该参数设置为 false 关闭 Leader 平衡操作,或者将检查周期调长以及将不平衡的比例调大,尽量降低 Leader 重平衡带来的影响。
最后一个参数是 offsets.topic.replication.factor 这个参数表示偏移管理 Topic 的副本数量,默认情况下使用 Kafka 消费者 API 时,如果选择让 Kafka 来保存偏移,那么 Kafka 会创建一个 Topic 叫做 __consumer_offsets 并使用这个 Topic 来管理不同消费者组的偏移量,这个 Topic 采用 compact 策略存储,也就是每个 Topic 的消费者组只会保存一份最新的偏移,所以这个 Topic 副本数量建议设置大一些,从而保证稳定性。默认这个参数的值是 3,但是在 Kafka 配置文件中显式设置成了 1,这可能是考虑到如果 Kafka 是单节点的,那么只能是设置 1 个,如果设置多了是无法消费的,只能是满足了节点的个数才可以。
我们有时候在消费 Kafka 的时候其中一个节点出现了故障,虽然我们消费的 Topic 存在副本,但是有可能我们始终消费不到某个分区的数据,最终导致消费出现不均衡,另外我们重启消费者进程之后有可能会出现直接阻塞无法消费到数据的情况。对于这个情况来说,有可能就是偏移管理 Topic 的副本设置为 1 导致的,而我们要消费的 Topic 对应消费组的偏移恰好落在故障的节点上,但是由于这些节点故障而之前保存的偏移又没有副本,只要故障的节点没有恢复那么这个偏移就永远获取不了,消费者也就无法消费数据了,我们查看 __consumer_offsets 这个 Topic 的详情其实就可以发现问题。
所以对于这个参数的值我们推荐如下:
如果 Kafka 是单节点的,那么 offsets.topic.replication.factor 值只能设置为 1 如果 Kafka 有两个节点,那么 offsets.topic.replication.factor 的值要设置为 2 如果 Kafka 有 3 个或 3 个以上节点,那么 offsets.topic.replication.factor 的值至少设置为 3对于节点比较多的 Kafka 集群来说,偏移管理 Topic 占的空间相比消息来说非常小,所以副本设置大一些是没有什么问题的。
最后我们再来看一下消息保存和传输方面的几个参数:
log.retention.{hours|minutes|ms} 这其实是 3 个参数,都是配置默认情况下 Topic 中消息保存的时间,从优先级来看是 ms > minutes > hours ,默认情况下 ms 和 minutes 都是 null ,只有 hours 默认是 168,也就是 7 天的时间。 log.retention.bytes 这个参数限制磁盘能保存消息的总大小,默认是 -1,表示不限制大小。 message.max.bytes 这个参数限制 Broker 能接受的最大消息大小,默认是 1048588,大约是 1MB num.replica.fetchers 这个表示 Follower Replica 从 Leader Replica 复制消息的线程数,默认是 1。其中第一个参数我们通常设置 log.retention.hours 就足够了,一般不需要太精细的控制,这个值默认是 168h,也就是保存 7 天,这个要根据我们实际的需要来配置保存时长。
第二个参数 log.retention.bytes 默认是 -1,说明 Kafka 并不主动限制消息的总大小,但是假如我们磁盘空间比较紧张,在指定的保存时间内或者高峰期数据增长容易导致磁盘占满,这种情况下最好做一下限制,防止磁盘写满后出现故障。
第三个参数是 message.max.bytes 这个值默认是 1048588,那么为什么不是 1048576 呢?我们可以算一下这之间差了 12 个字节,这就是消息头部所占用的空间大小,包括:8 字节的 offset + 4 字节的消息长度,正好占用 12 字节,其余的才是消息本身的内容,所以消息本身最大限制是 1MB。对于很多业务场景 1MB 的消息限制可能是不够的,所以这个要根据我们实际的业务需要进行调整。
最后的参数是 num.replica.fetchers 这个值默认是 1,如果是消息 TPS 非常高的情况下,一个线程复制可能会跟不上,时间长了有可能会被移出 ISR,所以如果我们机器的 CPU 不是太繁忙,建议适当增大该值,从而提高复制数据的吞吐,使得副本同步更加实时,但是这个值不要超过 CPU 的核数,对于 16 核及以上的机器,大部分情况设置为 8 就足够了。
以上就是比较重要的 Broker 端参数,合理设置这些参数在大多数情况下都可以保证集群必要的可用性和稳定性。
3.3 Topic 参数
除了 Broker 参数之外,Kafka 还支持为不同的 Topic 设置不同的参数值,Topic 参数比 Broker 参数少很多,大约也就 26 个左右,但是 Topic 参数的优先级比 Broker 参数的更高,这样就可以对不同的 Topic 实现不同的参数设置,适应更加灵活的场景,这就是 Topic 参数主要的意义。
那么下面我们来看一下比较重要且常用的几个的 Topic 参数:
retention.ms 设置该 Topic 的消息保存时长,默认和全局一致,当设置这个值之后将会覆盖全局的值。 retention.bytes 设置该 Topic 所能使用的最大磁盘空间,默认和全局一致,当设置之后会单独为这个 Topic 设置最大可用空间。 max.message.bytes 设置该 Topic 所能接收的消息最大长度,这个设置同样会覆盖全局的设置。如果 Kafka 集群承载的业务不同,那么在全局上可能给不出一个比较合适的限制,这时候就可以根据每个 Topic 的业务特性来独立限制消息的大小。关于 Topic 最常用的参数就是上面几个,更多的参数可以参考文档了解,比如 Kafka 2.5 版本的参数可以参考:https://kafka.apache.org/25/documentation.html#topicconfigs
那么下面我们来看下怎么去设置这些参数,从命令行工具来说有两种方式可以设置:
在创建 Topic 时设置 先创建 Topic,然后再修改设置如果是创建 Topic 时设置如下:
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic testMessage --partitions 3 --replication-factor 2 --config retention.ms=15552000000 --config max.message.bytes=5242880这样通过添加 --config 参数就可以完成设置,创建后查看 Topic 详情就可以看到我们的参数了。
有很大一部分情况是已经存在了 Topic,我们这时候要动态调整 Topic 的设置,那么这时候可以使用 kafka-configs.sh 工具调整 Topic 的设置:
bin/kafka-configs.sh --zookeeper localhost:2181/kafka --entity-type topics --entity-name testMessage --alter --add-config max.message.bytes=10485760这样也可以完成 Topic 配置的调整,不过要注意的是这里需要指定 ZooKeeper 的地址。
4. Kafka 性能调优进阶
在有了上面硬件、操作系统、JVM 以及集群参数配置的基础之上,我们的 Kafka 集群通常可以获得比较好的性能,但是仍然有一些可以持续优化的方向或者一些需要注意的细节,这些属于比较进阶的调优,我们一起来看一下。
4.1 零拷贝
关于零拷贝技术以及 Kafka 是如何利用零拷贝技术的,在 Kafka 分片和副本机制中已经做了叙述,这里不再详细赘述,我们只需要注意一点:保持客户端版本和 Broker 版本一致,这样就可以获得足够的性能收益。
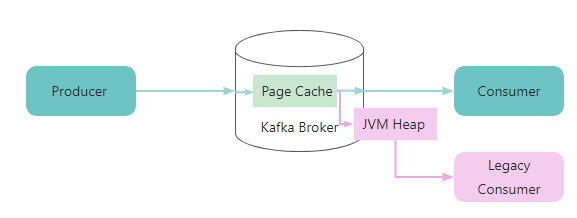
比如其中的绿色表示快速通道,也就是会利用 Zero Copy 的特性实现高吞吐,但是如果使用旧版本的消费者客户端,那么消息需要进行转换,因此就必须拷贝到 JVM 的堆内存中进行中转,所以就走了其中红色的慢速通道。
所以不需要太多的优化,我们只需要严格让客户端版本和 Broker 版本保持一致,就可以充分发挥 Kafka 的性能优势了。
4.2 应用层调优思路
应用层调优其实没有固定的方法,大多数情况都和具体的业务逻辑相关,但是仍然是有一些公共的方法是可以遵守的:
不要频繁地创建 Producer 或 Consumer 对象实例,这样会带来额外的开销,我们应该尽量复用他们。 用完后要记得关闭,无论是 Producer 还是 Consumer 实例,底层都会包括 Socket、ByteBuffer 等资源,如果程序长期运行而又没有及时关闭的话,可能会造成资源泄漏。 合理利用多线程来提升性能,比如在大部分编程语言中,Producer 实例是线程安全的,我们可以放心地在多个线程中共享这个实例。但是 Consumer 不是线程安全的,但是可以开启多个线程,每个线程中创建独立的实例,这样就可以实现并行的处理,但是同一个消费者组下线程数量不能超过 Topic 的分区数量。4.3 吞吐量调优
我们大部分人其实对吞吐量和延时的概念存在一定的误解,例如我们的 Kafka 发送一条消息需要 2ms,那么延时也就是 2ms,那么吞吐量就是 500 条/s,所以简单地将吞吐量 = 1000/Latency(ms),事实上我们假如一条一条的发送数据这种计算方式是没问题的,或者这种计算方式更常用在 Web API 调用的时候计算使用,但是对于数据系统来说不是这么简单的计算关系。
假如我们的 Producer 每次不是发送 1 条消息,而是缓存一批消息再发送,比如 10ms 缓存了 1000 条消息,发送这 1000 条用了 10ms,那么此时的时延大约是 20ms,而吞吐量则变成了:1000/20 * 1000 = 50000 条/s,延时增加 10 倍,但是吞吐确增加了 100 倍,这其实就是利用计算机系统中经典的摊销思想或者批量化(batch)的思想,在每次网络的必要开销下,发送更多的消息以实现更大的吞吐。实际上在操作系统的进程调度中,每次上下文切换是存在开销的,所以操作系统分配恰当的时间片长度,使得上下文切换的开销在 CPU 总时间中占用比较小,这样就像额外的开销分摊到非常多的始终周期中,从而让程序有更多的时间利用 CPU 资源。
所以 Kafka 的 Producer 就是这么设计的,是通过牺牲很小一部分延迟,来换取 TPS 也就是吞吐的显著提升。我们调用一次生产消息的操作其实是先写到本地的缓冲区,这个速度是非常快的,然后 Producer 客户端定期通过异步的方式将缓冲区的数据写入网络中,这样就可以获得较好的吞吐性能。
另外如果生产者设置了参数 acks=all ,那么需要等待所有副本都同步成功才认为消息生产成功,那么这个时候副本同步性能就和生产者的性能相关联了,这种情况下,可以按照前面说的增大副本拉取的并行线程数量 num.replica.fetchers 从而获得更好的生产性能。所以在 Producer 端如果允许我们尽量不要设置成 acks=all ,而是设置 acks=1 或者 acks=0 可以获得更好的性能。
另外在 Producer 端还有两个参数需要注意:
batch.size 这个是发送到同一个分区消息的批次大小限制,默认为 16KB。 linger.ms 当批量大小没有达到 batch.size 的限制时,最大允许多长时间的延迟发送数据。其中 batch.size 默认是 16KB,这个比较小,很容易就满了,所以实际生产环境中我们可以调大该参数的值,例如改为 512KB。linger.ms 默认值是 0,也就是表示无延迟,这显然太小了,所以我们可以调大,比如设置为 20ms,这表示消息的最大的发送延迟,这样可以减少请求的发送次数,从而提升吞吐量。
如果 Producer 实例在多线程环境中共享,并且消息写入比较频繁,那么我们需要调大参数 buffer.memory 这个值默认是 32MB,当写入的消息速度大于发送的速度时,如果缓冲区写满,那么生产者会阻塞 max.block.ms 时间,然后将抛出异常,默认是 60s,异常内容大约是 TimeoutException:Failed to allocate memory within the configured max blocking time ,这个时候我们可以考虑增加 buffer.memory 的值,前提是网络发送最终是可以跟得上到来速度的,这样就可以提供给到来的消息充足的空间来使用。
最后在生产者端还可以开启压缩来降低对网络的压力,推荐使用 LZ4 和 zstd 压缩算法,这也是 Kafka 适配比较好的两款算法。
最后来看一下 Consumer 端,Consumer 端最简单的方式是使用多线程来提升吞吐,同时我们可以通过并发队列连接比较复杂的业务处理过程,让消费者线程本身只接收数据,保证消费的性能,后续处理可以采用不对等的自定义线程数量来实现其他的业务逻辑,可以调的参数其实并不多,主要注意参数 fetch.min.bytes 的配置,这个参数默认是 1B,也就是说只要 Broker 端有数据,就可以立即返回给消费者端,这个确实是比较小,所以我们可以调大该值,让 Broker 端多返回一些数据给我们,但是这会导致 Broker 不断等待新数据的到来,直到攒到配置的大小才可以返回,所以同样是在牺牲一部分延迟的情况下提升吞吐。
最后我们总结一下吞吐量的调优思路:
如果 Producer 端设置了 acks=all ,那么要提高 Broker 端 num.replica.fetchers 参数的值;否则尽量设置 acks=1 或者 acks=0 调大 Producer 端 batch.size 的值实现更大的批量。 调大 Producer 端的 linger.ms 提高等待时间,降低网络开销。 多线程共享 Producer 的场景下调大 buffer.memory 的值,避免缓冲区占满。 Producer 端开启压缩参数 compression.type=lz4 或者 compression.type=zstd Consumer 端调大 fetch.min.bytes 的值,提升消费的吞吐量。如果反过来我们只对延时敏感,而不是太在意吞吐的话,根据上面的思路也很容易进行优化了:
Broker 端增大 num.replica.fetchers 的值 Producer 端设置 acks=1 Producer 端设置 linger.ms=0 关闭压缩,即设置 compression.type=none 在 Consumer 端设置 fetch.min.bytes=1首先在 Broker 端我们加快 Follower Replica 同步的实时性,在 Producer 端我们希望消息尽可能快的发送出去,因此不压缩、不等待,只需要 Leader 确认即可。在 Consumer 端我们希望消息尽可能快的到达,所以只要 Broker 端有数据就可以立即获取到,降低消费的延迟。
通过上面的调优,我们就可以将消息的延迟优化到极致。不过生产环境中对吞吐量的调优更多一些,只关注延迟的情况比较少,毕竟 Kafka 作为一个消息系统在应对海量数据的场景下我们更愿意通过少量的延迟增加来提升整体系统的吞吐能力。











