Prometheus性能优化的方法
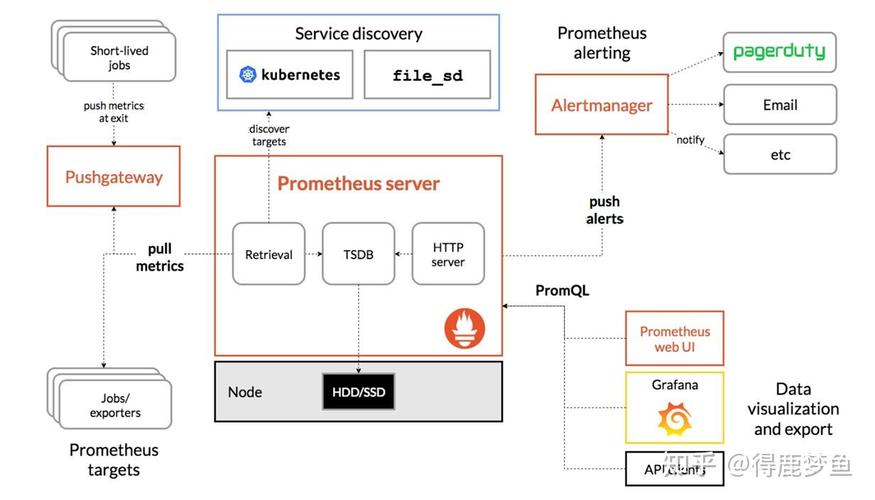
Prometheus是一个开源的监控和警报工具,用于收集和存储指标数据,为了确保Prometheus在大规模和高负载环境下的性能,可以采取以下优化方法:
1. 硬件和网络优化
1.1 使用高性能硬件
选择高性能的硬件设备,如SSD硬盘、多核CPU和足够的内存,以确保Prometheus能够快速处理和存储数据。
1.2 网络优化
确保Prometheus服务器与被监控节点之间的网络连接稳定且带宽充足,以减少数据传输延迟和丢失。
2. 配置优化
2.1 调整抓取间隔
根据实际需求调整Prometheus的抓取间隔,避免过于频繁的抓取导致的性能压力。
scrape_interval: 30s2.2 合并多个抓取目标
将多个抓取目标合并到一个配置文件中,以减少Prometheus实例的数量和资源消耗。
scrape_configs: job_name: node_exporter static_configs: targets: [192.168.1.1:9100, 192.168.1.2:9100]2.3 使用合适的存储引擎
根据实际需求选择合适的存储引擎,如Golang的追加写技术(AppendOnly)或追加写与追加读技术(AppendOnly Merge Map)。
storage: engine: appendonly3. 查询优化
3.1 使用即时向量(Instant Vectors)
在PromQL查询中使用即时向量,以减少不必要的计算和内存消耗。
irate(http_requests_total{job="api"}[5m])3.2 使用聚合函数
在PromQL查询中使用聚合函数,如sum、avg等,以减少返回的数据量。
sum(rate(http_requests_total[5m])) by (job)3.3 限制查询范围
在PromQL查询中限制查询的时间范围和标签数量,以减少查询结果的大小。
sum(rate(http_requests_total[5m])) by (job) {job="api"} limit 1004. 集群化部署
通过集群化部署Prometheus,实现数据的分片存储和查询负载均衡,提高系统的可扩展性和可用性,可以使用Thanos或Cortex等开源项目实现Prometheus的集群化部署。
5. 缓存和预聚合
使用缓存和预聚合技术,如Prometheus的追加写与追加读技术(AppendOnly Merge Map),将原始数据进行预处理和聚合,以减少查询时的数据量和计算复杂度。
6. 监控和告警
定期监控系统的性能指标,如CPU、内存和磁盘使用情况,及时发现潜在的性能问题,设置合理的告警阈值和通知策略,确保在出现问题时能够及时响应和处理。











