Docker和Hadoop是两个在IT领域非常流行的技术,它们各自有各自的特性和应用场景,下面将详细介绍Docker和Hadoop的区别。
1. 定义和用途
Docker是一个开源的应用容器引擎,它允许开发者将应用及其依赖打包到一个可移植的容器中,然后发布到任何流行的Linux机器或Windows机器上,也可以实现虚拟化,容器是完全使用沙箱机制,相互之间不会有任何接口。
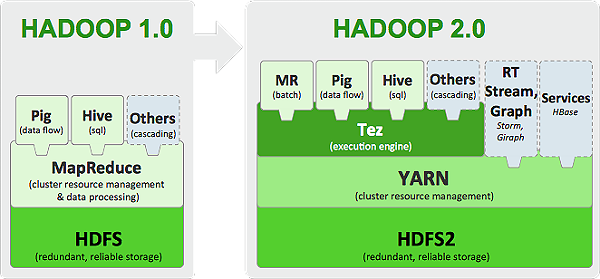
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。
2. 架构和运行方式
Docker是基于Linux内核的一个虚拟化解决方案,利用了Linux的cgroups和namespace等内核功能来隔离进程和资源,每个容器内运行一个进程,进程之间相互隔离。
Hadoop则是基于Java语言开发的,运行在通用操作系统上,通过软件模拟分布式环境,把大数据处理任务分解成多个小任务并行处理。
3. 部署和维护
Docker提供了一套完整的容器生命周期管理工具,包括容器创建、启动、停止、删除、查看状态等操作,使得部署和维护工作变得非常简单,Docker还支持跨平台运行,可以在多种环境中保持一致性。
Hadoop的部署和维护相对复杂一些,需要对分布式系统有一定的理解,同时还需要处理各种硬件和软件的兼容性问题。
4. 社区和生态系统
Docker的社区非常活跃,有大量的用户和开发者,同时也有很多的商业公司参与其中,提供了丰富的镜像库和服务。
Hadoop的社区也非常活跃,有大量的开源项目和工具,如HDFS、MapReduce、Hive、Pig等,由于Hadoop的复杂性,学习和使用Hadoop需要投入更多的时间和精力。
5. 性能和扩展性
Docker的性能非常好,因为它直接运行在宿主机的内核上,不需要模拟硬件和操作系统,而且Docker的镜像文件非常小,启动速度快。
Hadoop的性能取决于硬件和数据分布策略,但是由于Hadoop的设计目标是处理PB级别的大数据,因此它的扩展性非常好。
Docker和Hadoop各有优势,适用于不同的场景,Docker适合用于构建、测试和部署应用,而Hadoop适合用于处理大规模的数据。
FAQs
Q1: Docker和Hadoop可以一起使用吗?
A1: 可以,Docker可以用来部署和管理Hadoop的各个组件,使得Hadoop的部署和维护变得更加简单,Docker的高可用性和快速恢复能力也可以帮助提高Hadoop的稳定性和可靠性。
Q2: Docker和虚拟机有什么区别?
A2: 虚拟机是一种模拟硬件的软件实现,它在操作系统层面之上增加了一个抽象层,每个虚拟机内部可以运行一个完整的操作系统和应用程序,而Docker则是一种容器技术,它在操作系统层面之下增加了一个抽象层,每个容器内部只运行一个进程或者一组紧密关联的进程,相比于虚拟机,Docker更加轻量级,启动速度快,资源利用率高。
6. 归纳
Docker和Hadoop是两个在IT领域非常重要的技术,它们各自有各自的特性和优势,Docker适合用于构建、测试和部署应用,而Hadoop适合用于处理大规模的数据,在实际的项目中,我们可以根据实际的需求和场景,灵活地选择和使用这两种技术。
虽然Docker和Hadoop有很大的不同,但是它们也可以相互配合使用,我们可以使用Docker来部署和管理Hadoop的各个组件,这样可以使得Hadoop的部署和维护变得更加简单,Docker的高可用性和快速恢复能力也可以帮助提高Hadoop的稳定性和可靠性。
无论是Docker还是Hadoop,都是为了帮助我们更好地开发和使用软件,我们需要根据自己的需求和场景,选择合适的技术和工具,以便更好地完成我们的工作。
7. 展望
随着技术的不断发展和进步,Docker和Hadoop都将继续发展和进步,我们期待Docker能够提供更加强大和便捷的容器管理功能,同时也期待Hadoop能够提供更加高效和强大的数据处理能力,我们相信,无论是Docker还是Hadoop,都将在未来的技术发展中发挥重要的作用。











