安装Hadoop
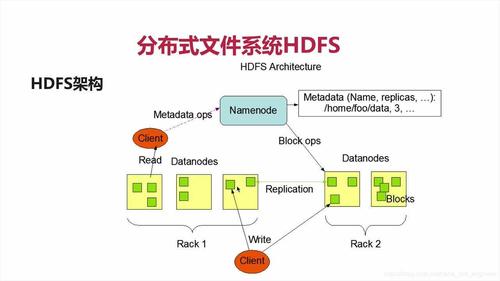
在Linux上安装Hadoop需要一些前期准备,包括Java环境的搭建和SSH免密登录的配置,以下是具体步骤:
1. 安装Java环境
Hadoop依赖于Java环境,因此首先需要安装JDK。
sudo aptget update sudo aptget install defaultjdk验证Java是否安装成功:
java version2. 配置SSH免密登录
Hadoop的启动需要用到SSH,为了方便管理,我们需要配置SSH免密登录。
生成密钥对:
sshkeygen t rsa将公钥添加到授权文件中:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys测试SSH免密登录是否成功:
ssh localhost3. 下载并解压Hadoop
从Apache官网下载Hadoop的tar包,然后解压到指定目录。
tar xzf hadoop*.tar.gz C /usr/local/4. 配置Hadoop环境变量
编辑~/.bashrc文件,添加以下内容:
export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin使配置生效:
source ~/.bashrc5. 配置Hadoop核心文件
编辑$HADOOP_HOME/etc/hadoop/coresite.xml,添加以下内容:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>编辑$HADOOP_HOME/etc/hadoop/hdfssite.xml,添加以下内容:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>格式化HDFS:
hdfs namenode format启动Hadoop:
startall.sh至此,Hadoop已经安装并启动成功。
使用Hadoop
HDFS命令
命令 描述 hadoop fs ls 列出HDFS上的文件和目录 hadoop fs mkdir 在HDFS上创建目录 hadoop fs put 将本地文件上传到HDFS hadoop fs get 从HDFS下载文件到本地 hadoop fs rm 删除HDFS上的文件或目录 hadoop fs tail 查看HDFS上文件的尾部内容 hadoop fs cat 查看HDFS上文件的全部内容 hadoop fs stat 查看HDFS上文件或目录的状态信息MapReduce程序运行
编写MapReduce程序后,可以使用以下命令进行编译、打包、运行:
编译 javac classpath ${HADOOP_CLASSPATH} Main.java 打包 jar cvf myApp.jar Main.class 运行 hadoop jar myApp.jar Main classname input outputMain是主类名,classname是主类的完全限定名,input是输入路径,output是输出路径。
FAQs
Q1: Hadoop启动失败怎么办?
A1: 检查日志文件,通常位于$HADOOP_HOME/logs目录下,查找错误信息并进行相应的处理,如果是配置文件错误,检查并修改相应的配置文件;如果是端口被占用,尝试更换端口或关闭占用端口的程序。
Q2: 如何在多台机器上部署Hadoop集群?
A2: 在每台机器上重复上述的安装步骤,然后在所有机器上配置$HADOOP_HOME/etc/hadoop/masters和$HADOOP_HOME/etc/hadoop/slaves文件,分别指定Master节点和Slave节点,最后在所有机器上启动Hadoop。











