
新智元报道
编辑:alan
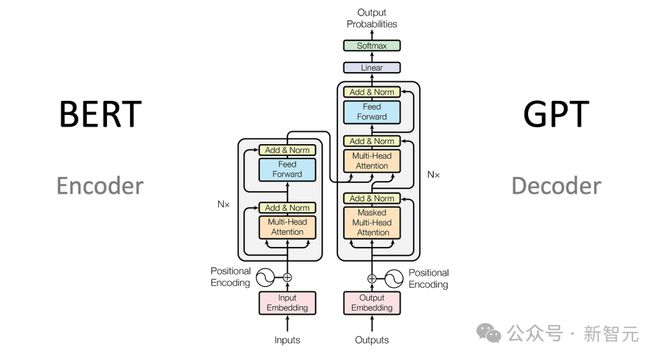
近日,来自 Meta 的研究人员将 Transformer 用于解码真实世界的场景,并转化为几何表示,效果超越了传统的点云、网格或辐射场,只需 70M 参数,就能完成虚拟叠加现实的炫酷效果。
抛弃传统方法,只采用 Transformer 来解码真实场景!
近日,来自 Meta 的研究人员推出了 SceneScript,只需要 70M 参数,仅采用编码器解码器架构,就能将真实世界的场景转化为几何表示。

论文地址:https://arxiv.org/pdf/2403.13064.pdf
SceneScript 是一种用于表示和推断场景几何图形的方法,使用自回归结构化语言模型和端到端学习。
SceneScript 可以助力 AR 和 AI 设备理解物理空间的几何形状,比如下面这个演示,利用 Aria 眼镜拍摄的素材,SceneScript 可以获取视觉输入并估计场景元素(墙壁、门窗等)。

是不是感觉一下子走到了虚拟和现实的交界?
用这个技术来帮助开发 AR 或者 MR 游戏应该是妥妥的,小编表示期待地搓搓手。
再看下面这个,将 SceneScript 技术叠加到 Meta Quest 的显示画面上,现实世界瞬间变得方方正正,还挺萌的。

同时我们也可以发现,SceneScript 预测的场景元素可以任意扩展,不断包含进来新的建筑特征、对象,甚至还可以将对象进行分解。

SceneScript 是 Meta RealityLabs Research 的一个研究项目,整个模型分为编码器和解码器两个部分。
其中,点云编码器由一系列 3D 稀疏卷积块组成,这些卷积块将大点云汇集到少量特征中。
随后,Transformer 解码器利用编码器的特征作为交叉注意力的上下文,自回归生成 token。
编码器和解码器都只有大约 35M 参数,整个模型训练了 3 天,大约 200k 次迭代。
模型在实际应用中的推理速度也很不错,即使直接使用 PyTorch 中原始的 Transformer(未经优化),解码 256 个 token(相当于一个包含墙壁、门、窗和对象边界框的中等大小的场景),也只需要大约2-3 秒。
SceneScript 是完全在模拟器中训练的,使用 Project Aria 眼镜上捕获的内容序列,而没有使用真实世界的数据。训练完成之后,模型又在真实场景中进行了验证。
另外,在适应其他设备时,也可以针对不同类型镜头的不同相机型号对模型进行微调。
不过作者也表示,SceneScript 仅在室内场景中进行了训练,因此对室外场景的推断可能会导致不可预测的输出。
目前,SceneScript 仅供 Meta 的内部研究团队使用。
SceneScript
区别于传统的将场景描述为网格(meshes),体素网格(voxel grids),点云(point clouds)或辐射场(radiance fields)的传统方法,
SceneScript 使用场景语言编码器-解码器架构,直接从编码的视觉数据中推断出结构化语言命令集。
工作流程
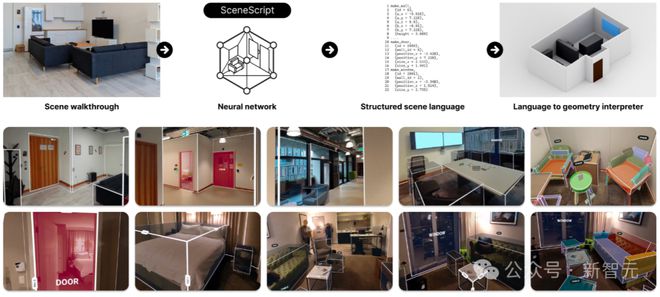
如上图所示,给定一个以自我为中心的环境视频,SceneScript 直接预测由结构化场景语言命令组成的 3D 场景表示。
第一行表示整个工作流程,放大一下就是下面这样子:
SceneScript 先从 VR 眼镜等设备中,拿到图像或点云表示的视觉信息,

然后将视觉信息编码为描述物理空间的潜在表示形式,
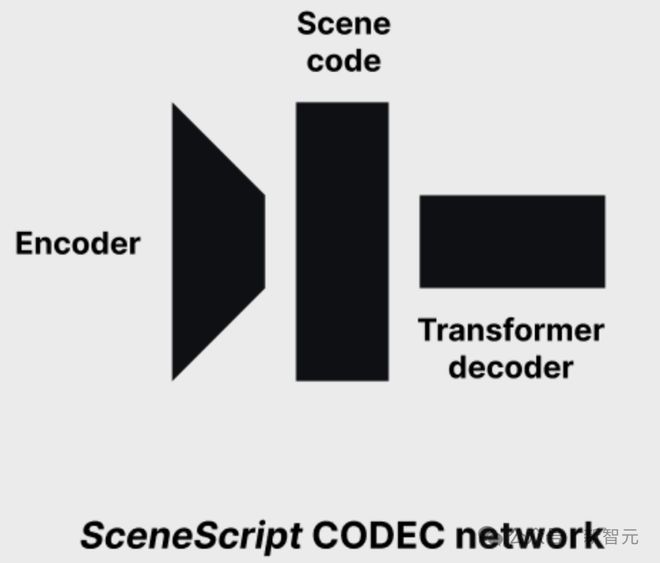
再将潜在表示解码为简洁、参数化且可解释的语言(类似 CAD),

最后,3D 解释器将上面的语言转换为物理空间的几何表示。
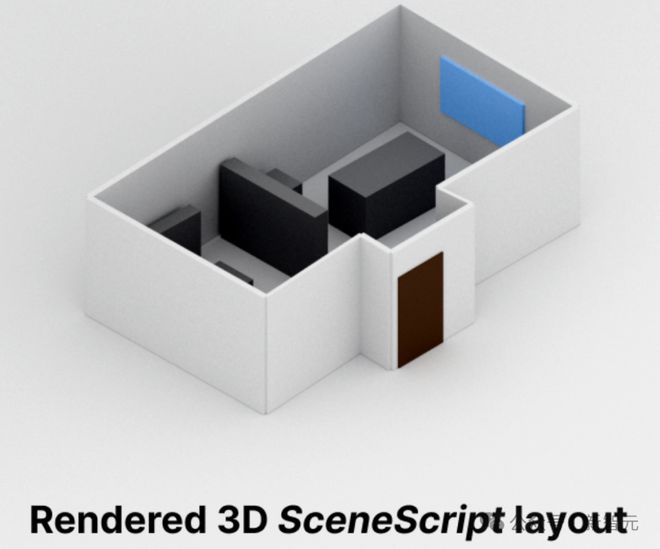
优势
SceneScript 以纯文本形式自回归地预测手工设计的结构化语言命令,这种形式有几个明显的优点:
首先,作为纯文本,占用空间很小,将大型场景的内存要求降低到只需要几个字节。
其次,这种命令旨在产生清晰且定义明确的几何图形,并且,模型所使用的 make_door(*door_parameters)等高级参数命令,在设计上是可解释、可编辑和语义丰富的。
另外,可以通过简单地向语言中添加新的结构化命令,来无缝集成新的几何实体。
最后,这种解决方式也为未来一些潜在的新应用提供了参考,例如编辑场景、查询场景或者聊天交互。
另外,由于语言模型需要大量数据来训练响应的结构化语言命令,而对于当前应用没有合适的数据集。
为了训练 SceneScript,研究人员于是自己造了一个名为 Aria Synthetic Environments 的大规模合成数据集,该数据集由 100k 个高质量的室内场景组成,包括以自我为中心的逼真场景演练和对应的标签。
对于每个场景,使用来自 Project Aria 的一整套传感器数据来模拟以自我为中心的轨迹,还包括深度和实例分割,而架构布局的基本事实采用上面提到的自定义的结构化语言命令给出。

上图展示了 Aria 生成场景的随机样本,显示了布局、灯光和物体放置的多样性,以及俯视图、模拟轨迹(蓝色路径)、深度、RGB 和对象实例的渲染,最后是场景点云。
SceneScript 可以轻松扩展到新任务,同时保持视觉输入和网络架构的固定性。
网络架构
SceneScript 的管道是一个简单的编码器-解码器体系结构,它使用视频序列并以标记化格式返回 SceneScript 语言。
作者研究了三种编码器变体:点云编码器、摆姿势图像集编码器和组合编码器,结果表明,解码器在所有情况下都保持不变。
编码器从场景的视频演练中以 1D 序列的形式计算潜在场景代码。解码器设计为将这些 1D 序列用作输入。这样就可以在一个统一的框架内整合各种输入模式。
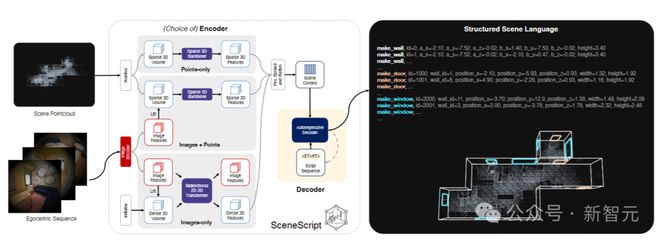
上图展示了 SceneScript 的核心管线。原始图像和点云数据被编码为潜在代码,然后自回归解码为描述场景的一系列命令。使用自定义构建的解释器显示可视化效果。
值得注意的是,对于本文中的结果,点云是使用 Aria MPS 从图像中计算出来的,没有使用专用的 RGB-D / 激光雷达传感器。
实验结果
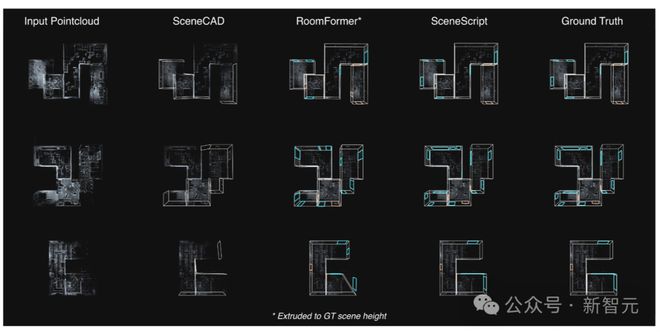
上图为在 Aria Synthetic Environments 测试集上,SceneScript 模型和 SOTA 方法之间的定性比较。
像 SceneCAD 这样的分层方法会受到错误级联的影响,这会导致边缘预测模块中缺少元素。而 RoomFormer(一种拉伸为 3D 的 2D 方法)主要受到轻微捕获的场景区域的影响,这些区域在密度图中留下了不明显的信号。
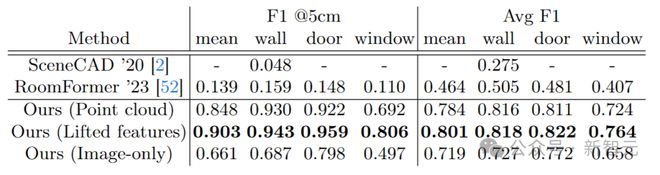
表中数据给出了 Aria 合成环境的布局估计,SceneScript 方法与近期相关工作之间的定量比较。
参考资料:











