
机器之心专栏
机器之心编辑部
Fast-DetectGPT 同时做到了高准确率、高速度、低成本、通用,扫清了实际应用的障碍!
大语言模型如 ChatGPT 和 GPT-4 在各个领域对人们的生产和生活带来便利,但其误用也引发了关于虚假新闻、恶意产品评论和剽窃等问题的担忧。本文提出了一种新的文本检测方法 ——Fast-DetectGPT,无需训练,直接使用开源小语言模型检测各种大语言模型生成的文本内容。
Fast-DetectGPT 将检测速度提高了 340 倍,将检测准确率相对提升了 75%,成为新的 SOTA。在广泛使用的 ChatGPT 和 GPT-4 生成文本的检测上,均超过商用系统 GPTZero 的准确率。
Fast-DetectGPT 同时做到了高准确率、高速度、低成本、通用,扫清了实际应用的障碍!

研究动机
大语言模型(LLMs)在各个领域已产生了深远影响。这些模型在新闻报道、故事写作和学术研究等多元领域提升了生产力。然而,它们的误用也带来了一些问题,特别是在假新闻、恶意产品评论和剽窃方面。这些模型生成的内容流畅连贯,甚至让专家都难以辨别其来源是人类还是机器。因此,我们需要可靠的机器生成文本检测方法来解决这个问题。
现有的检测器主要分为两类:有监督分类器和零样本分类器。虽然有监督分类器在其特定训练领域表现出色,但在面对来自不同领域或不熟悉模型生成的文本时,其表现会变差。零样本分类器则能够免疫领域特定的退化,并且在检测精度上可以与有监督分类器相媲美。
然而,典型的零样本分类器,如 DetectGPT,需要执行大约一百次模型调用或与 OpenAI API 等服务交互来创建扰动文本,这导致了过高的计算成本和较长的计算时间。同时它需要用生成文本的源语言模型来进行检测的计算,使得该方法不能用于检测由未知模型生成的文本。
在这篇论文中,我们提出了一种新的假设来检测机器生成的文本。我们认为,人类和机器在给定上下文的情况下选择词汇存在明显的差异,而机器和机器之间的差异不明显。利用这种差异我们能够有效地用一套模型和方法检测不同模型生成的文本内容。
方法
Fast-DetectGPT 的操作基于一个前提,即人类和机器在文本生成过程中倾向于选择不同的词汇,人类的选择比较多样,而机器更倾向于选择具有更高模型概率的词汇。
这个假设源于这样一个事实,即在大规模语料库上预训练的 LLM 反映的是人类的集体写作行为,而非个体的写作行为,这导致它们在给定上下文时的词汇选择存在差异。
这个假设在一定程度上也得到了文献中的观察结果的支持,这些观察结果表明,机器生成的文本通常具有比人类写作的文本有更高的统计概率(或更低的困惑度)。
然而,我们的方法并不仅仅依赖于机器生成文本具有更高的统计概率的假设。而是进一步假设,在条件概率函数中,机器生成的文本周围的局部空间存在一个正曲率。据此,我们提出条件概率曲率指标,用以区分机器生成文本和人类撰写文本。
我们的实验观察如图 1 所示,在四个不同开源模型上,人类撰写文本的条件概率曲率近似一个均值为 0 的正态分布,而机器生成文本的条件概率曲率近似一个均值为 3 的正态分布,这两个分布只有少量的重叠。根据这种分布上的特点,我们可以选择一个阈值,大于这个阈值判断为机器生成文本,小于则为人类撰写,从而获得一个检测器。
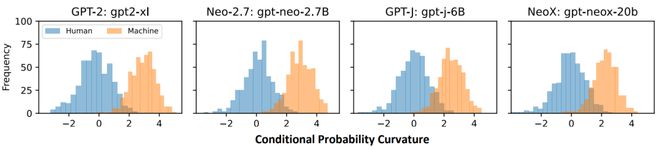
图 1:条件概率曲率在不同源模型设定上的分布
条件概率曲率

条件独立采样
对替代 tokens 的独立采样是 Fast-DetectGPT 能快速计算的关键。具体来说,我们在固定文本 x 的条件下,从中采样每个 token,而不依赖于其他采样的 token。

检测过程
如图 2 所示,Fast-DetectGPT 提出了一个新的三步检测过程,包括 1)采样-- 我们引入一个采样模型,给定条件 x 生成备选样本,2)打分-- 通过将 x 作为输入的评分模型的单次前向传递,可以轻易获得条件概率。所有样本都可以在同一预测分布中进行评估,因此我们不需要多次调用模型,以及 3)比较-- 段落和样本的条件概率被比较以计算条件概率曲率。更多的细节在论文的算法部分进行了详细描述。
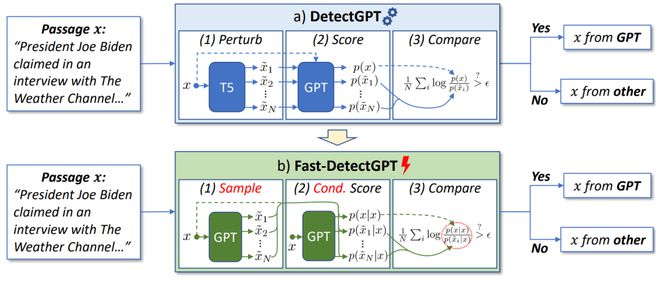
图 2:Fast-DetectGPT vs DetectGPT
我们发现 “采样” 和 “打分” 两个步骤在实现上可以进一步合并,并有一个解析解,而不是采样近似,详细论述和证明见论文附录 B。此外,我们发现使用相同的模型进行采样和评分时,条件概率曲率与简单的似然函数和熵基线有紧密的联系,具体论述见论文第 2 章结束部分。
实验结果

表 1:结果概况
如表 1 所示,Fast-DetectGPT 和基线 DetectGPT 相比,在速度上提升 340 倍,在检测准确率上相对提升约 75%,具体展开如下。
340 倍的推理加速
我们比较了 Fast-DetectGPT 和 DetectGPT 在 Tesla A100 GPU 上的推理时间(不包括初始化模型的时间)。尽管 DetectGPT 使用了 GPU 批处理,将 100 个扰动分成 10 个批次,但它仍然需要大量的计算资源。它在五次运行中(对应 5 个源模型)总共需要 79,113 秒(大约 22 小时)。相比之下,Fast-DetectGPT 仅用 233 秒(大约 4 分钟)就完成了任务,实现了约 340 倍的显著加速,突显出其显著的性能提升。
准确的 ChatGPT 和 GPT-4 文本检测
我们进一步在黑盒环境中评估 Fast-DetectGPT,使用由 ChatGPT 和 GPT-4 生成的段落来模拟真实世界场景。我们为每个数据集和源模型生成了 150 个样本,包括 150 个模型生成的文本段落和 150 个人工撰写的文本段落。
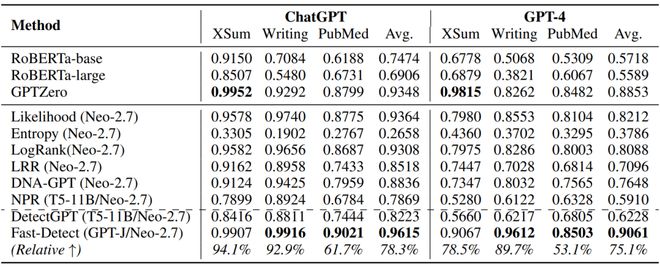
表 2:ChatGPT 和 GPT-4 生成内容的检测效果(AUROC)
如表 2 所示,Fast-DetectGPT 展现出一致的优越的检测能力。它在 ChatGPT 和 GPT-4 的相对 AUROC 上分别超过了 DetectGPT 的 78.3% 和 75.1%。与监督检测器 RoBERTa-base/large 相比,Fast-DetectGPT 实现了更高的整体准确性。这些结果展示 Fast-DetectGPT 在真实世界场景中工作的潜力。
更有趣的是,商业模型 GPTZero 在新闻(XSum)上表现较好,但在故事(WritingPrompts)和技术写作(PubMedQA)上表现较差。我们猜测该模型是有监督的检测器,其训练数据中可能包含比较多的新闻语料。虽然商用模型一般都有额外的针对性的效果上的改进,但总体上 Fast-DetectGPT 比 GPTZero 还是要好 2 到 3 个点。
低误报率、高召回率
在实际使用中,我们希望检测器有较低的误报率,否则会给用户带来困扰,伤害真实的内容创作者。在较低误报率的前提下,我们希望检测器有较高的召回率,能够识别出大部分机器生成的内容。
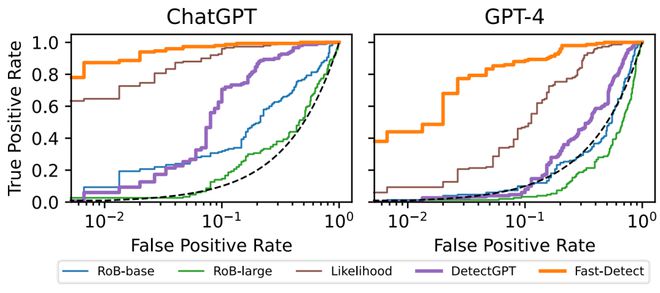
图 3:误报率(False Positive Rate) vs 召回率(True Positive Rate)
如图 3 所示,在正负样本一比一的 WritingPrompts 评测数据集上,橙色线标示的 Fast-DetectGPT 对比紫色线标示的 DetectGPT 和其它方法。我们可以看到,在误报率为 1% 的条件下,使用 Fast-DetectGPT 能获得的召回率比其它方法高出很多。比如说,在 ChatGPT 生成文本上,Fast-DetectGPT 能达到 87% 的召回率,而 Likelihood 和 DetectGPT 只有 64% 和 6% 的召回率。在 GPT-4 生成文本上,差距进一步拉大,Fast-DetectGPT 能达到 44% 的召回率,而 Likelihood 和 DetectGPT 只有 9% 和 0% 的召回率。
文本越长准确率越高
零样本检测器由于其统计性质,对较短的文本段落表现通常比较差。我们通过将 WritingPrompts 评测数据集中的文本段落截断到各种目标长度来进行评估。
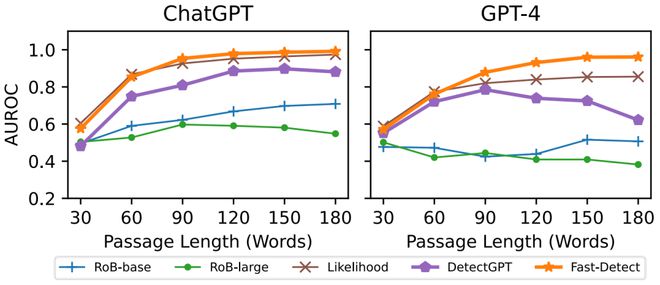
图 4:不同长度上的鲁棒性
如图 4 所示,这些检测器在由 ChatGPT 生成的段落上,整体检测准确率随着段落长度的增加而增加。在 GPT-4 生成的段落上,检测准确率显示出不一致的趋势。
具体来说,当段落长度增加时,有监督检测器的性能表现出下降趋势,而 DetectGPT 在开始时经历了一个增涨,然后在段落长度超过 90 个词时出现了显著的下降。
我们推测,有监督检测器和 DetectGPT 的非单调趋势源于它们将段落视为一个整体的 token 链(token chain),导致其检测效果不能泛化到不同长度的文本上。相比之下,Fast-DetectGPT 在段落长度增加时表现出一致的、单调的准确性增加,展示稳健的效果。
结语
主要结论:通过研究发现,条件概率曲率是机器生成文本上更本质的指标,验证了我们关于机器和人类文本生成过程区别的假设。基于这个新假设,检测器 Fast-DetectGPT 在 DetectGPT 基础上加速了两个数量级,并在白盒和黑盒设置中都显著提高了检测精度。
未来展望:Fast-DetectGPT 依赖于预训练语言模型来覆盖多个领域和语言,但没有单一的模型可以覆盖所有的语言和领域,要使检测器更通用,我们可能需要联合多个语言模型以获得更全面的覆盖。另一方便,条件概率曲率能区分机器生成文本和人类撰写文本,也可能区分由两个不同模型生成的文本(作者识别),还可能用于判别 OOD 文本(OOD 检测)。这些方向的应用值得进一步研究。











