
新智元报道
编辑:桃子好困
AI 世界的进化快的有点跟不上了。刚刚,全球最强最大 AI 芯片 WSE-3 发布,4 万亿晶体管 5nm 工艺制程。更厉害的是,WSE-3 打造的单个超算可训出 24 万亿参数模型,相当于 GPT-4/Gemini 的十倍大。
全球最快、最强的 AI 芯片面世,让整个行业瞬间惊掉了下巴!
就在刚刚,AI 芯片初创公司 Cerebras 重磅发布了「第三代晶圆级引擎」(WSE-3)。
性能上,WSE-3 是上一代 WSE-2 的两倍,且功耗依旧保持不变。

90 万个 AI 核心,44GB 的片上 SRAM 存储,让 WSE-3 的峰值性能达到了 125 FP16 PetaFLOPS。
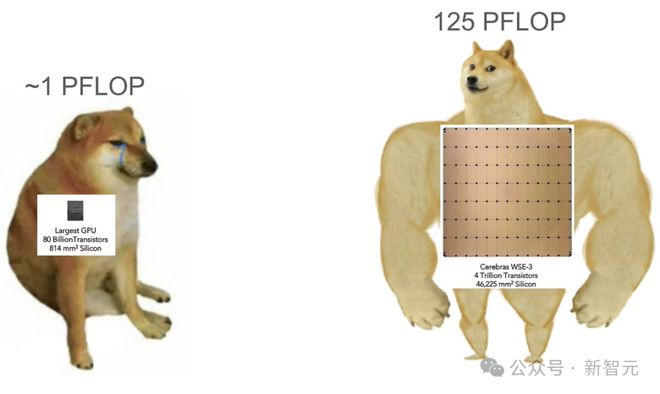
这相当于 52 块英伟达 H100 GPU!
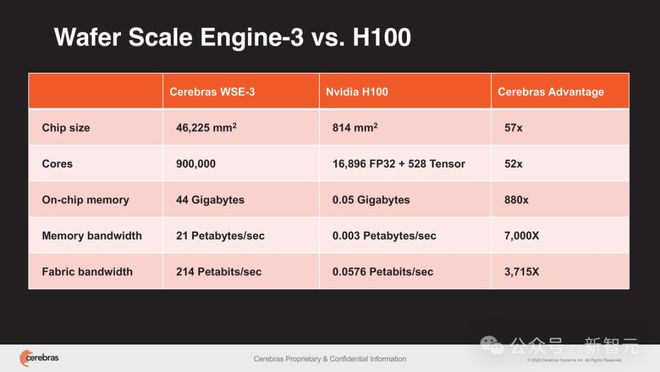
不仅如此,相比于 800 亿个晶体管,芯片面积为 814 平方毫米的英伟达 H100。
采用台积电 5nm 制程的 WSE-3,不仅搭载了 40000 亿个晶体管(50 倍),芯片面积更是高达 46225 平方毫米(57 倍)。

专为 AI 打造的计算能力
此前,在传统的 GPU 集群上,研究团队不仅需要科学地分配模型,还必须在过程中处理各种复杂问题,比如处理器单元的内存容量、互联带宽、同步机制等等,同时还要不断调整超参数并进行优化实验。

更令人头疼的是,最终的实现很容易因为小小的变动而受到影响,这样就会进一步延长解决问题所需的总时间。
相比之下,WSE-3 的每一个核心都可以独立编程,并且专为神经网络训练和深度学习推理中,所需的基于张量的稀疏线性代数运算,进行了优化。
而团队也可以在 WSE-3 的加持下,以前所未有的速度和规模训练和运行 AI 模型,并且不需要任何复杂分布式编程技巧。
单芯片实现集群级性能
其中,WSE-3 配备的 44GB 片上 SRAM 内存均匀分布在芯片表面,使得每个核心都能在单个时钟周期内以极高的带宽(21 PB/s)访问到快速内存——是当今地表最强 GPU 英伟达 H100 的 7000 倍。
超高带宽,极低延迟
而 WSE-3 的片上互连技术,更是实现了核心间惊人的 214 Pb/s互连带宽,是 H100 系统的 3715 倍。
单个 CS-3 可训 24 万亿参数,大 GPT-4 十倍
由 WSE-3 组成的 CS-3 超算,可训练比 GPT-4 和 Gemini 大 10 倍的下一代前沿大模型。
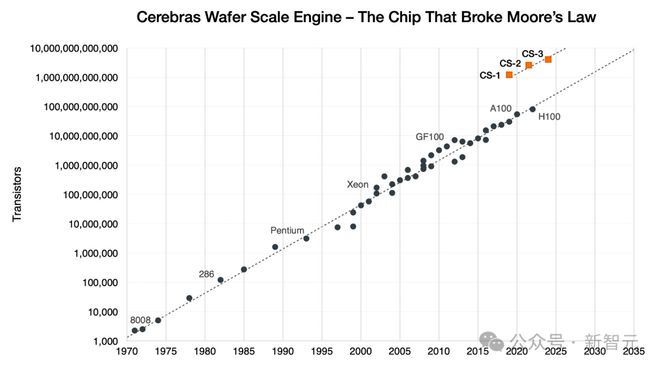
再次打破了「摩尔定律」!2019 年 Cerebras 首次推出 CS-1,便打破了这一长达 50 年的行业法则。
官方博客中的一句话,简直刷新世界观:在 CS-3 上训练一个万亿参数模型,就像在 GPU 上训练一个 10 亿参数模型一样简单!
显然,Cerebras 的 CS-3 强势出击,就是为了加速最新的大模型训练。
它配备了高达 1.2PB 的巨大存储系统,单个系统即可训出 24 万亿参数的模型——为比 GPT-4 和 Gemini 大十倍的模型铺平道路。
简之,无需分区或重构,大大简化训练工作流提高开发效率。

在 Llama 2、Falcon 40B、MPT-30B 以及多模态模型的真实测试中,CS-3 每秒输出的 token 是上一代的 2 倍。
而且,CS-3 在不增加功耗/成本的情况下,将性能提高了一倍。
除此之外,为了跟上不断升级的计算和内存需求,Cerebras 提高了集群的可扩展性。
上一代 CS-2 支持多达 192 个系统的集群,而 CS-3 可配置高达 2048 个系统集群,性能飙升 10 倍。
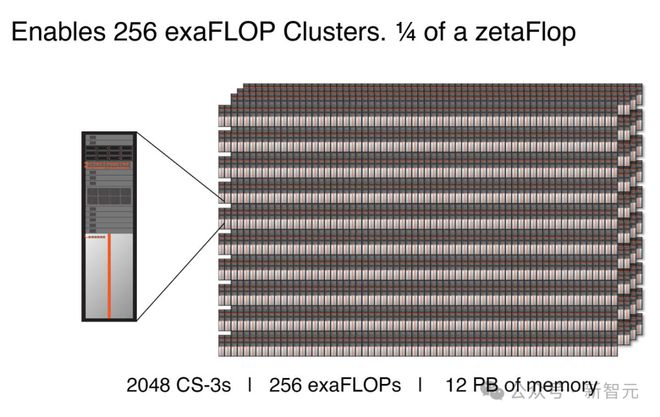
具体来说,由 2048 个 CS-3 组成的集群,可以提供 256 exafloop 的 AI 计算。
能够在 24 小时内,从头训练一个 Llama 70B 的模型。
相比之下,Llama2 70B 可是用了大约一个月的时间,在 Meta 的 GPU 集群上完成的训练。

与 GPU 系统的另一个不同是,Cerebras 晶圆规模集群可分离计算和内存组件,让开发者能轻松扩展 MemoryX 单元中的内存容量。
得益于 Cerebras 独特的 Weight Streaming 架构,整个集群看起来与单个芯片无异。
换言之,一名 ML 工程师可以在一台系统上开发和调试数万亿个参数模型,这在 GPU 领域是闻所未闻的。
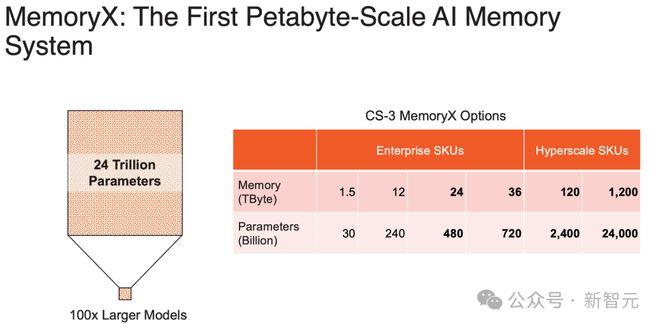
具体来说,CS-3 除了为企业提供 24TB 和 36TB 这两个版本外,还有面向超算的 120TB 和 1200TB 内存版本。(之前的 CS-2 集群只有 1.5TB 和 12TB 可选)
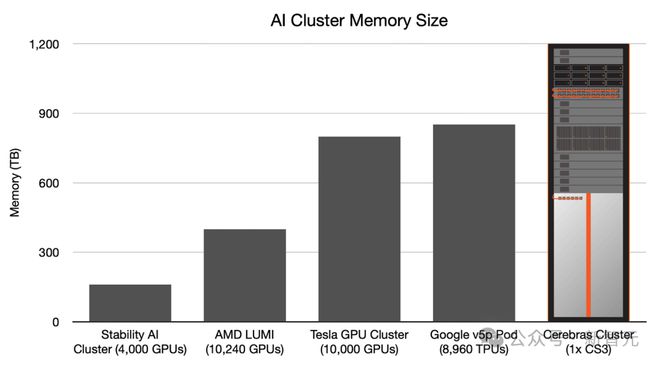
单个 CS-3 可与单个 1200 TB 内存单元配对使用,这意味着单个 CS-3 机架可以存储模型参数,比 10000 个节点的 GPU 集群多得多。
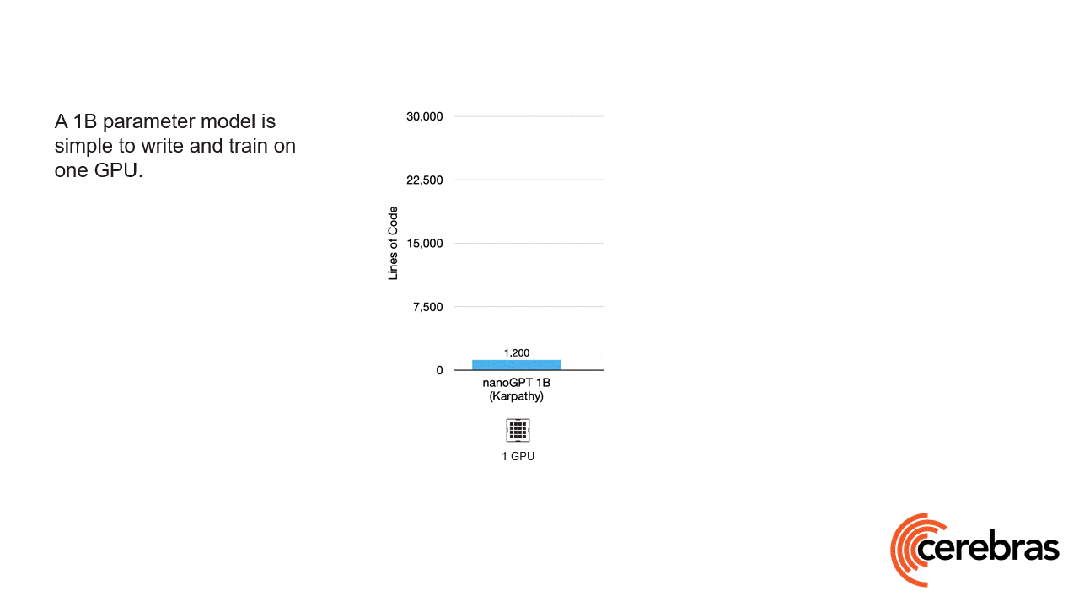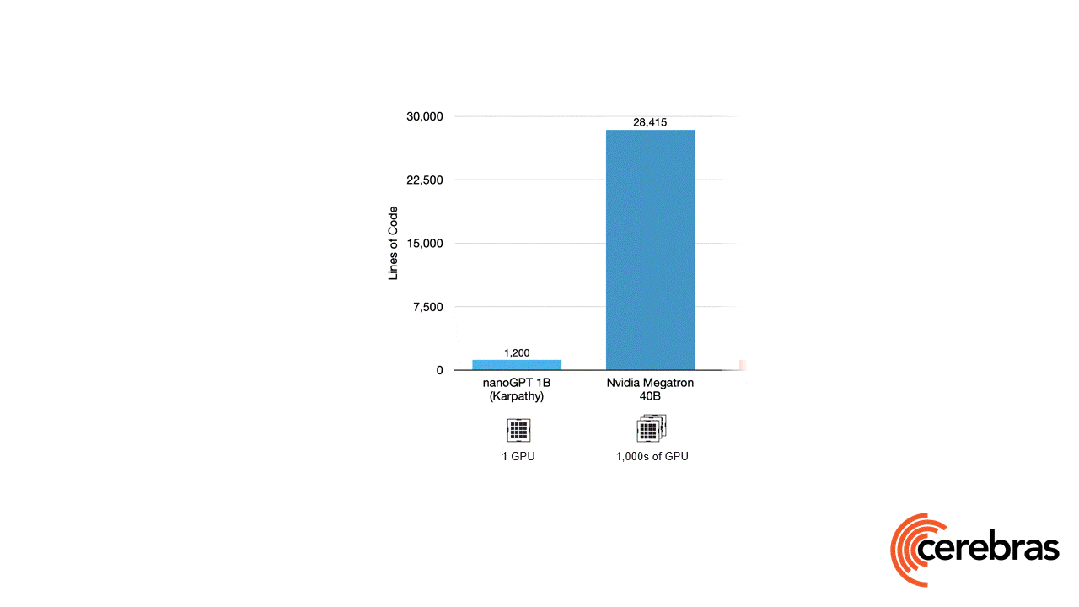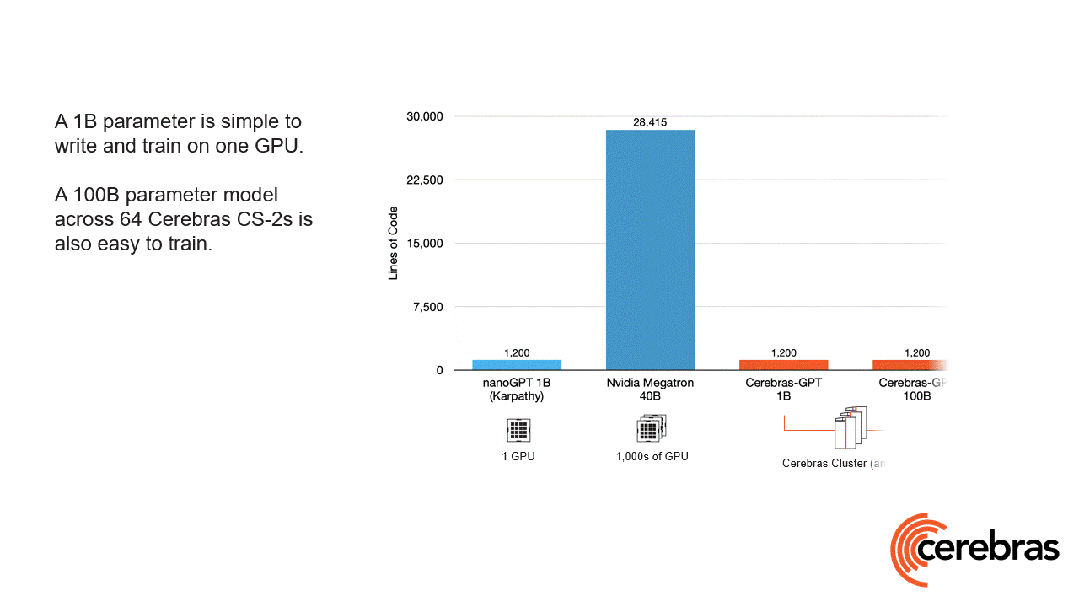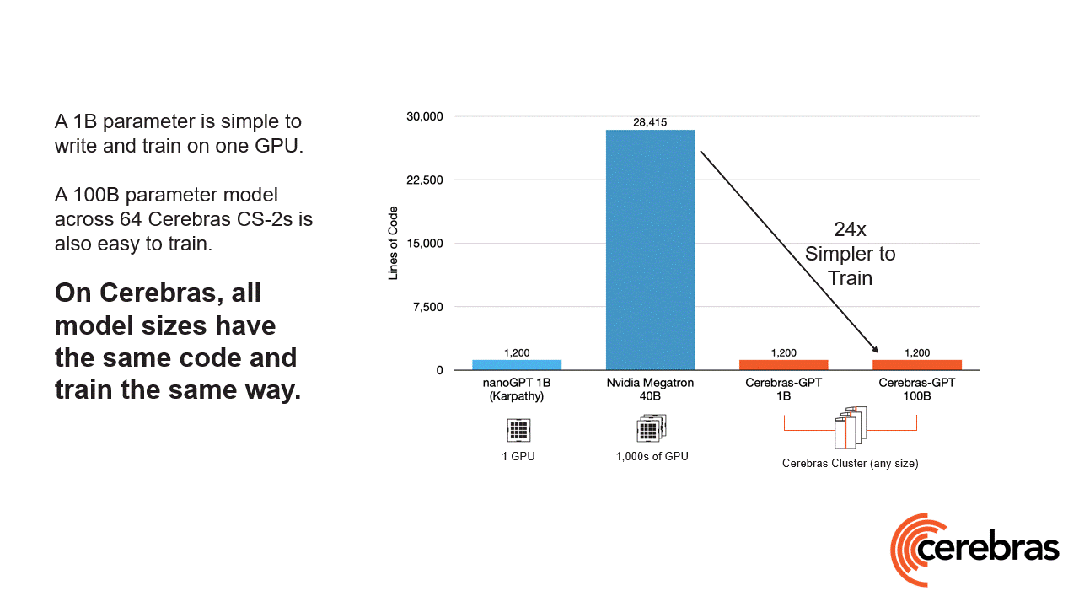
除此之外,与使用 GPU 相比,在 Cerebras 平台上开发所需的代码量还减少了高达 97%。
更令人震惊的数字是——训练一个 GPT-3 规模的模型,仅需 565 行代码!
Playground AI 创始人称,GPT-3 正稳步成为 AI 领域的新「Hello World」。在 Cerebras 上,一个标准的 GPT-3 规模的模型,只需 565 行代码即可实现,创下行业新纪录。

首个世界最强芯片打造的超算来了
由 G42 和 Cerebras 联手打造的超级计算机——Condor Galaxy,是目前在云端构建 AI 模型最简单、最快速的解决方案。

它具备超过 16 ExaFLOPs 的 AI 计算能力,能够在几小时之内完成对最复杂模型的训练,这一过程在传统系统中可能需要数天。
其 MemoryX 系统拥有 TB 级别的内存容量,能够轻松处理超过 1000 亿参数的大模型,大大简化了大规模训练的复杂度。
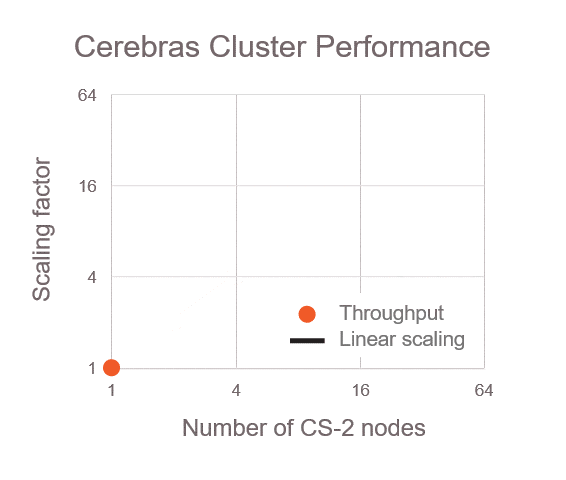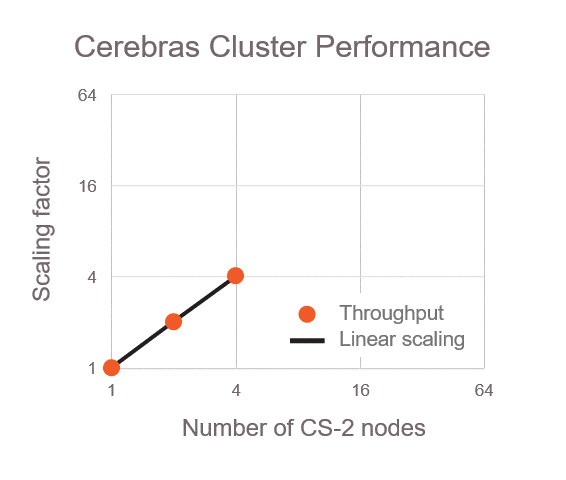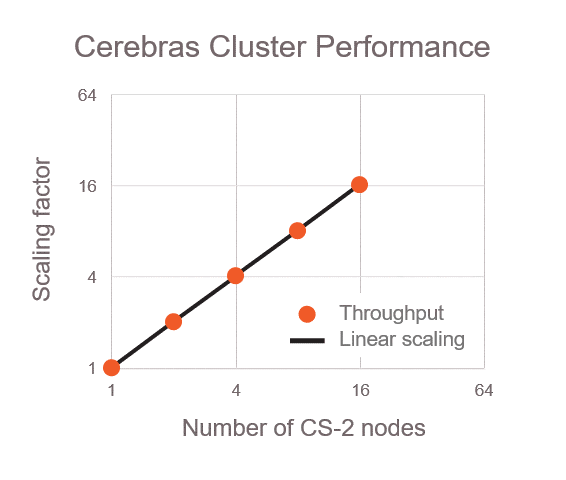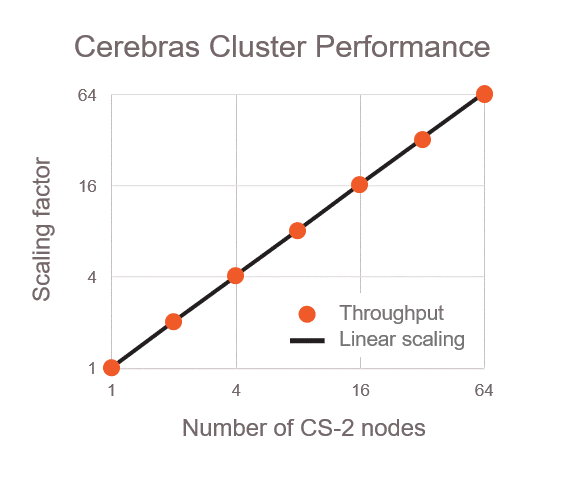
与现有的基于 GPU 的集群系统不同,Condor Galaxy 在处理 GPT 这类大型语言模型,包括 GPT 的不同变体、Falcon 和 Llama 时,展现出了几乎完美的扩展能力。
这意味着,随着更多的 CS-3 设备投入使用,模型训练的时间将按照几乎完美的比例缩短。
而且,配置一个生成式 AI 模型只需几分钟,不再是数月,这一切只需一人便可轻松完成。
在简化大规模 AI 计算方面,传统系统因为需要在多个节点之间同步大量处理器而遇到了难题。
而 Cerebras 的全片级计算系统(WSC)则轻松跨越这一障碍——它通过无缝整合各个组件,实现了大规模并行计算,并提供了简洁的数据并行编程界面。

此前,这两家公司已经联手打造了世界上最大的两台 AI 超级计算机:Condor Galaxy 1 和 Condor Galaxy 2,综合性能达到 8exaFLOPs。
G42 集团的首席技术官 Kiril Evtimov 表示:「我们正在建设的下一代 AI 超级计算机 Condor Galaxy 3,具有 8exaFLOPs 的性能,很快将使我们的 AI 计算总产能达到 16exaFLOPs。」

如今,我们即将迎来新一波的创新浪潮,而全球 AI 革命的脚步,也再一次被加快了。
参考资料:











